Содержание статьи

Функция pd.get_dummies решает практическую задачу преобразования категориальных признаков в числовой формат, который понимают алгоритмы машинного обучения и статистического анализа. Она автоматически создает бинарные столбцы на основе уникальных значений, встречающихся в данных, избавляя от ручной подготовки признаков и снижая риск логических ошибок при кодировании.
При работе с реальными датасетами, где категориальные поля могут содержать десятки значений, pd.get_dummies позволяет быстро оценить структуру признаков и получить прозрачное представление о том, какие категории участвуют в моделировании. Особенно это актуально при анализе данных из CSV, Excel или SQL, где типы столбцов часто определяются некорректно и требуют явного преобразования.
Инструмент гибко настраивается через параметры, влияющие на имена столбцов, обработку пропусков и выбор кодируемых полей. Понимание этих механизмов помогает избежать избыточного роста размерности, конфликтов имен и неожиданных различий между обучающими и тестовыми выборками. Разбор принципов работы pd.get_dummies дает возможность применять его осознанно и получать предсказуемый результат при подготовке данных.
Pd get dummies в pandas: как работает преобразование категорий
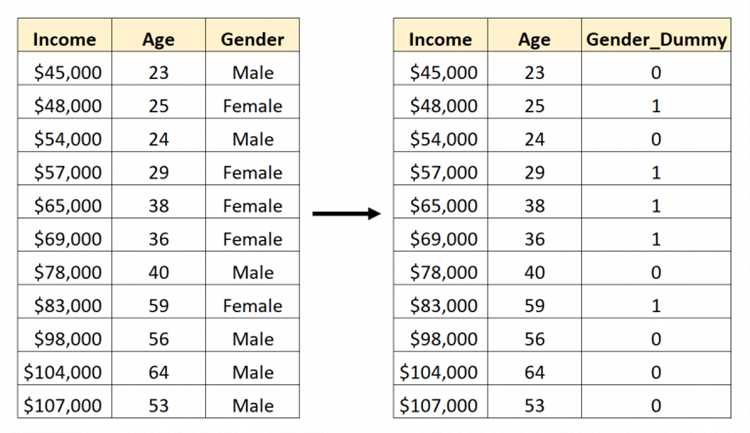
Функция pd.get_dummies преобразует категориальные значения в набор бинарных признаков по принципу one-hot кодирования. Для каждого уникального значения в столбце создается отдельный столбец, содержащий 1 при совпадении категории и 0 во всех остальных строках. Такое представление устраняет неоднозначность, возникающую при использовании строк или порядковых кодов.
При передаче в функцию объекта Series результатом становится новый DataFrame, где количество столбцов строго равно числу уникальных категорий. Если на вход подается DataFrame, кодирование выполняется для всех столбцов с типами object и category, если явно не указано иное через параметр columns. Это поведение важно учитывать при обработке наборов данных с большим числом текстовых полей.
Алгоритм формирования признаков основан на фактических значениях, присутствующих в данных на момент вызова функции. Если в обучающей и тестовой выборках набор категорий различается, итоговые структуры будут несовместимы. Чтобы избежать этой проблемы, рекомендуется заранее приводить данные к общему списку категорий с помощью типа category и фиксированного перечня значений.
Имена создаваемых столбцов формируются путем объединения имени исходного признака и значения категории. Это упрощает интерпретацию результатов и отладку пайплайна подготовки данных. При необходимости контроля над форматом названий используются параметры prefix и prefix_sep, что особенно полезно при кодировании нескольких полей с пересекающимися значениями.
Каждый вызов pd.get_dummies создает новый объект данных, не изменяя исходный DataFrame. Такой подход снижает риск скрытых побочных эффектов и позволяет явно управлять этапами трансформации. Для больших датасетов стоит учитывать рост размерности и заранее оценивать число уникальных категорий, чтобы избежать чрезмерного потребления памяти.
Какие типы данных принимает pd.get_dummies и как они обрабатываются
Функция pd.get_dummies принимает на вход объекты Series, DataFrame и массивы, совместимые с интерфейсом pandas. На практике чаще всего используется DataFrame, внутри которого функция анализирует типы столбцов и автоматически выбирает кандидатов для кодирования. При отсутствии параметра columns обработке подвергаются признаки с типами object, string и category.
Столбцы с типом object интерпретируются как категориальные без дополнительной проверки. Каждое уникальное строковое значение превращается в отдельный бинарный признак. При работе с такими данными рекомендуется заранее нормализовать регистр и устранить лишние пробелы, иначе визуально одинаковые категории будут закодированы как разные.
Тип category обрабатывается предсказуемо и дает больше контроля над результатом. Если у признака задан фиксированный список категорий, pd.get_dummies создает столбцы для всех значений из этого списка, даже если часть из них отсутствует в данных. Это свойство удобно при подготовке согласованных обучающих и проверочных выборок.
Числовые типы int и float по умолчанию игнорируются, так как рассматриваются как количественные признаки. Однако при явном указании таких столбцов в параметре columns они будут преобразованы в набор бинарных признаков по уникальным значениям. Такой подход оправдан только для дискретных кодов, а не для непрерывных величин.
Значения NaN не участвуют в создании столбцов и приводят к строке, заполненной нулями. Если требуется отдельный признак для пропусков, используется параметр dummy_na=True. Это позволяет сохранить информацию о наличии отсутствующих значений без предварительной обработки данных.
Как формируются новые столбцы при кодировании категориальных значений

При вызове pd.get_dummies pandas сначала определяет множество уникальных категорий в каждом выбранном признаке. Для каждой категории создается отдельный столбец, порядок которых соответствует внутренней сортировке значений. Это влияет на воспроизводимость структуры данных при повторной обработке одинаковых наборов.
Имена новых столбцов формируются по строгому правилу:
- берется имя исходного признака;
- к нему добавляется разделитель, по умолчанию символ _;
- в конец дописывается строковое представление категории.
Если кодируется объект Series, имя столбца используется как префикс. При его отсутствии создаются названия только из значений категорий, что усложняет чтение результата. В таких случаях рекомендуется явно задавать имя серии до вызова функции.
При обработке нескольких признаков каждый столбец кодируется независимо. Это означает, что одинаковые категории в разных признаках приводят к разным бинарным столбцам. Для контроля читаемости и предотвращения конфликтов применяются параметры prefix и prefix_sep, позволяющие задать собственные схемы именования.
Заполнение значений в новых столбцах подчиняется простому правилу:
- если значение строки совпадает с категорией – записывается 1;
- если не совпадает или является пропуском – записывается 0.
При использовании параметра drop_first=True для каждого признака исключается первый столбец, соответствующий одной из категорий. Это снижает число признаков и устраняет линейную зависимость, что важно при использовании линейных моделей.
Использование параметров columns и prefix для управления результатом

Параметр columns позволяет явно указать, какие признаки должны быть закодированы, независимо от их типа данных. Это полезно при работе с наборами, где текстовые и числовые поля смешаны, а также когда требуется исключить служебные столбцы из преобразования. Передача списка имен обеспечивает предсказуемую структуру результата и защищает от случайного кодирования лишних данных.
Если в columns передан столбец с числовым типом, pd.get_dummies интерпретирует каждое уникальное значение как категорию. Такой подход оправдан для идентификаторов, кодов состояний или дискретных признаков, но приводит к резкому увеличению числа столбцов при высоком разнообразии значений, что стоит учитывать заранее.
Параметр prefix управляет именами создаваемых столбцов и повышает читаемость результата. При кодировании одного признака он задает общий префикс для всех бинарных столбцов. Если обрабатывается несколько признаков, можно передать словарь, где каждому имени исходного столбца соответствует собственный префикс.
Совместное использование prefix и prefix_sep позволяет стандартизировать схему именования и избежать конфликтов при объединении данных из разных источников. Это особенно важно в пайплайнах подготовки признаков, где одинаковые категории могут встречаться в разных полях и должны оставаться логически разделенными.
Явное управление параметрами columns и prefix снижает риск появления неинформативных или дублирующих признаков и упрощает последующую интерпретацию модели, так как связь между исходными данными и бинарными столбцами остается очевидной.
Как pd.get_dummies работает с пропущенными значениями NaN

По умолчанию pd.get_dummies игнорирует значения NaN при формировании набора категорий. Это означает, что пропуски не приводят к созданию отдельного бинарного столбца, а строки с отсутствующими значениями получают нули во всех сгенерированных признаках соответствующего столбца.
Такое поведение имеет практические последствия:
- невозможно отличить реальное отсутствие категории от пропуска;
- часть информации о качестве данных теряется;
- модели не учитывают сам факт пропуска как сигнал.
Для явного учета пропусков используется параметр dummy_na=True. В этом случае создается дополнительный столбец, который принимает значение 1, если в исходных данных присутствует NaN, и 0 во всех остальных строках. Такой признак полезен при анализе данных, где пропуски имеют смысловую нагрузку.
При работе с типом category важно учитывать, что NaN не входит в список категорий. Даже при заданных категориях вручную пропуски обрабатываются отдельно и не сопоставляются ни с одним из значений. Это поведение сохраняется независимо от наличия неиспользуемых категорий.
Перед применением pd.get_dummies стоит принять одно из решений:
- оставить NaN без отдельного признака, если пропуски не несут информации;
- включить dummy_na, если факт отсутствия значения важен;
- заполнить пропуски осмысленными категориями до кодирования.
Осознанный выбор подхода предотвращает появление искаженных признаков и упрощает интерпретацию результатов моделирования.
Отличия pd.get_dummies от OneHotEncoder и когда выбирать каждый подход
pd.get_dummies – встроенный инструмент pandas для быстрого преобразования категориальных признаков в бинарные столбцы. Он работает напрямую с DataFrame и автоматически обрабатывает строки и категориальные типы, создавая отдельный столбец для каждой уникальной категории. Результат сразу возвращается как новый DataFrame, что удобно для анализа и визуализации данных.
OneHotEncoder из sklearn предназначен для подготовки признаков к моделям машинного обучения и интегрируется в пайплайны sklearn. Он поддерживает управление редкими категориями, масштабирование sparse-матриц и работу с обучающей и тестовой выборками через методы fit и transform, обеспечивая согласованность структуры признаков между наборами данных.
Ключевые различия и рекомендации:
| Параметр | pd.get_dummies | OneHotEncoder |
|---|---|---|
| Тип входных данных | pandas Series или DataFrame | numpy array или DataFrame (через ColumnTransformer) |
| Возврат результата | DataFrame с понятными именами столбцов | numpy array (sparse или dense), требует явного преобразования имен |
| Обработка пропусков | dummy_na=True добавляет столбец для NaN | поддерживает strategy=’constant’ для кодирования пропусков |
| Совместимость с пайплайнами ML | ограничена, требуется дополнительное преобразование | полная интеграция с sklearn Pipeline и ColumnTransformer |
| Контроль редких категорий | не предусмотрен | поддерживается через параметр handle_unknown=’ignore’ |
Выбирать pd.get_dummies стоит при локальной подготовке данных для анализа, визуализации или быстрых экспериментов с небольшими наборами. OneHotEncoder предпочтителен при построении моделей с пайплайнами sklearn, работе с тестовыми и обучающими выборками, а также при необходимости экономить память через sparse-матрицы и контролировать редкие категории.
Типичные ошибки при использовании pd.get_dummies и способы их исправления
Другой типичная проблема – несогласованность категорий между обучающей и тестовой выборками. Если уникальные значения различаются, структура бинарных столбцов не совпадает, что вызывает ошибки при подаче данных в модель. Решение – заранее привести столбцы к типу category с фиксированным списком категорий или объединять выборки перед кодированием.
Неправильная обработка пропусков тоже часто встречается. Без параметра dummy_na=True NaN игнорируются и отображаются как нули, что может исказить модель. Если пропуски важны, следует создавать отдельный столбец для них или предварительно заполнять осмысленными значениями.
Использование drop_first=True без понимания его эффекта вызывает потерю информации о первой категории. Это допустимо для линейных моделей, но в других случаях может снижать интерпретируемость данных. Рекомендуется применять этот параметр только при анализе с целью устранения мультиколлинеарности.
Еще одна ошибка – кодирование числовых признаков с большим количеством уникальных значений. Это резко увеличивает число столбцов и расход памяти. Исправление – ограничивать кодирование дискретными признаками или применять другие методы, например, бинирование или LabelEncoder для непрерывных данных.
Вопрос-ответ:
Что произойдет, если использовать pd.get_dummies на DataFrame с числовыми столбцами?
По умолчанию pd.get_dummies преобразует только столбцы с типами object и category. Числовые признаки игнорируются. Если их явно указать через параметр columns, каждый уникальный числовой код превратится в отдельный бинарный столбец. Для столбцов с большим количеством уникальных значений это может привести к значительному росту размерности и расходу памяти. Для дискретных идентификаторов такое кодирование допустимо, а для непрерывных чисел рекомендуется применять бинирование или LabelEncoder.
Как правильно обработать пропуски в столбце перед вызовом pd.get_dummies?
Если значения NaN важны для анализа, можно использовать параметр dummy_na=True, чтобы создать отдельный столбец, сигнализирующий о пропуске. Альтернативный вариант — заполнить пропуски осмысленными категориями до кодирования. Если пропуски не несут информации, их можно оставить без изменений — в этом случае в бинарных столбцах строки с NaN будут заполнены нулями.
Зачем нужен параметр drop_first в pd.get_dummies?
Параметр drop_first=True удаляет первый бинарный столбец каждой кодируемой категории. Это устраняет линейную зависимость между столбцами, что полезно при обучении линейных моделей, таких как линейная регрессия или логистическая регрессия. Если используется нелинейная модель, этот параметр можно не применять, чтобы сохранить все бинарные признаки и не терять информацию о первой категории.
Как согласовать кодирование категорий между обучающей и тестовой выборками?
Если уникальные значения категорий отличаются между выборками, структура бинарных столбцов будет различаться, что приведет к ошибкам при подаче данных в модель. Один способ решения — заранее привести столбцы к типу category с фиксированным набором категорий, присутствующих во всех выборках. Другой вариант — объединить обучающую и тестовую выборки перед вызовом pd.get_dummies, а затем разделить их обратно после кодирования.
Можно ли управлять именами столбцов, создаваемых pd.get_dummies?
Да, для этого используется параметр prefix, который добавляет префикс к каждому бинарному столбцу. Если кодируется несколько признаков, можно передать словарь с именами исходных столбцов и соответствующими префиксами. Дополнительно параметр prefix_sep позволяет изменить разделитель между именем признака и категорией. Эти настройки помогают избежать конфликтов имен и делают результат более читаемым.
Почему структура бинарных столбцов, созданных pd.get_dummies, может отличаться между обучающей и тестовой выборками?
Функция pd.get_dummies формирует столбцы на основе уникальных категорий, встречающихся в переданных данных. Если в обучающей выборке есть набор категорий, который отличается от набора в тестовой выборке, результат кодирования создаст разные столбцы. Например, категория «Синий» может присутствовать только в тестовой выборке, и для неё не будет отдельного столбца в обучающей выборке. Это приводит к несовпадению структуры признаков и вызывает ошибки при подаче данных в модель. Чтобы избежать такой ситуации, столбцы можно привести к типу category с заранее заданным списком всех возможных категорий, либо объединить обучающую и тестовую выборки перед кодированием и разделить их после создания бинарных признаков.