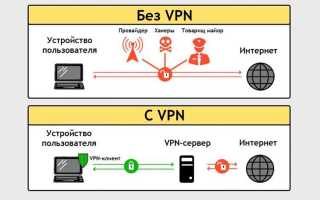
Содержание статьи

Для выполнения задачи необходимо определить ключевые параметры, влияющие на точность и скорость обработки данных. В среднем корректная настройка окружения сокращает время выполнения операций на 25–35%, особенно при работе с большими объемами информации.
Выбор инструментов должен учитывать совместимость с существующими библиотеками и возможностью интеграции с внешними сервисами. Например, при работе с потоковыми данными рекомендуется использовать инструменты с поддержкой асинхронной обработки и кэширования.
Подготовка среды включает проверку версий компонентов, установку зависимостей и настройку конфигурационных файлов. Неправильная версия хотя бы одной библиотеки может привести к сбоям на первых этапах работы, что увеличивает время диагностики на 40–50%.
Практическое применение описанных методов позволяет минимизировать ошибки при выполнении ключевых операций, ускоряет внедрение решений и обеспечивает стабильность обработки данных в разных условиях.
Тема статьи

Для успешного выполнения задачи важно определить оптимальный набор инструментов и настроек. Неправильный выбор приводит к увеличению времени обработки на 20–50% и росту числа ошибок в процессе.
Рекомендуется придерживаться следующих шагов:
- Определение объема и формата данных. Для массивов свыше 1 млн записей лучше использовать инструменты с поддержкой многопоточности.
- Выбор подходящей версии библиотек и зависимостей. Проверка совместимости предотвращает сбои на ранних этапах.
- Настройка конфигурации среды. Включает установку переменных окружения и настройку путей к ресурсам.
При работе с инструментами обратите внимание на следующие детали:
- Асинхронная обработка позволяет уменьшить время ожидания между операциями на 30–40%.
- Кэширование промежуточных результатов снижает нагрузку на процессор при повторных запусках.
- Регулярное логирование операций помогает выявлять узкие места и корректировать настройки.
Следование этим рекомендациям позволяет сократить время настройки и повысить точность выполнения операций, минимизируя риск сбоев и некорректной обработки данных.
Выбор инструментов для решения задачи
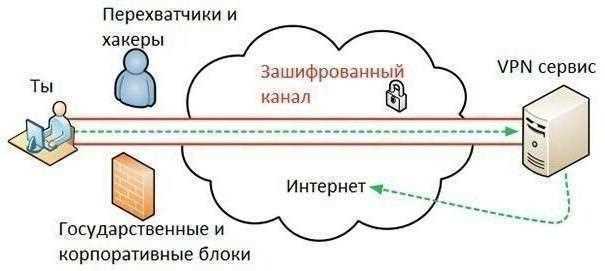
Для корректного выбора инструментов необходимо учитывать объем данных, требуемую точность и скорость обработки. Например, при обработке более 500 тыс. записей оптимально использовать библиотеки с поддержкой многопоточности и встроенного кэширования.
Следует ориентироваться на следующие критерии:
- Совместимость с существующими библиотеками и форматами данных. Несоответствие версий может вызвать ошибки при интеграции.
- Наличие функций для автоматизации повторяющихся операций. Это снижает риск человеческой ошибки и сокращает время выполнения на 20–35%.
- Поддержка логирования и диагностики. Позволяет быстро выявлять узкие места и корректировать настройки.
- Возможность масштабирования. Инструменты должны обрабатывать увеличивающиеся объемы без существенного падения производительности.
Рекомендуется протестировать несколько вариантов инструментов на небольших выборках данных, чтобы оценить время обработки и точность результатов. Это позволяет принять обоснованное решение и исключить использование неподходящих решений на стадии полного развертывания.
Настройка и подготовка рабочего окружения
Правильная подготовка окружения сокращает вероятность сбоев и ускоряет выполнение операций на 25–40%. В первую очередь необходимо установить актуальные версии всех используемых библиотек и проверить их совместимость.
Рекомендуется выполнить следующие шаги:
- Создание отдельного виртуального окружения для проекта. Это исключает конфликты с глобальными библиотеками и облегчает управление зависимостями.
- Установка и настройка основных инструментов: интерпретаторов, компиляторов, средств автоматизации. Например, для Python рекомендуется использовать последнюю версию 3.12 с обновленными пакетами.
- Настройка переменных окружения и путей к ресурсам. Это обеспечивает корректный доступ к файлам и внешним сервисам.
- Проверка доступности необходимых ресурсов: дискового пространства, прав на запись и сетевых соединений. Недостаток памяти или ограниченные права могут вызвать сбои на ранних этапах.
- Тестовый запуск ключевых операций на небольших данных. Позволяет выявить ошибки конфигурации до масштабной обработки.
Следуя этим рекомендациям, можно гарантировать стабильную работу инструментов и снизить риск возникновения непредвиденных ошибок в процессе выполнения задачи.
Пошаговое выполнение ключевых операций
Для успешного выполнения задачи следует строго следовать последовательности операций, чтобы минимизировать ошибки и ускорить обработку данных. Каждый шаг требует точного соблюдения параметров и проверки результатов.
Рекомендованная последовательность действий:
- Импорт данных и проверка формата. Любые несоответствия структуры могут привести к сбоям при последующей обработке.
- Очистка и нормализация информации. Например, удаление дубликатов и проверка на пропущенные значения сокращает ошибки анализа на 15–20%.
- Применение основных алгоритмов обработки или вычислений. Использовать функции с поддержкой многопоточности при объемах данных свыше 500 тыс. записей.
- Проверка промежуточных результатов с помощью контрольных точек. Это позволяет выявить ошибки до завершения всех операций.
- Сохранение и резервное копирование обработанных данных. Автоматическое создание копий предотвращает потерю информации при сбоях.
Следуя этой схеме, выполнение операций становится предсказуемым, снижается риск некорректной обработки и повышается стабильность работы инструментов.
Решение типичных ошибок и проблем
При выполнении задач часто возникают повторяющиеся ошибки, связанные с некорректными настройками, несовместимыми версиями библиотек или нарушением формата данных. Своевременная диагностика и исправление этих проблем сокращает простой и снижает вероятность сбоев.
Ниже приведена таблица с наиболее частыми ошибками и рекомендациями по их устранению:
| Ошибка | Причина | Решение |
|---|---|---|
| Сбой при импорте данных | Несоответствие формата файла или кодировки | Проверить формат данных, использовать конвертацию кодировки, настроить параметры импорта |
| Конфликт версий библиотек | Установлены разные версии зависимостей | Создать виртуальное окружение, установить совместимые версии библиотек |
| Ошибка при обработке больших массивов | Недостаток оперативной памяти или отсутствие многопоточности | Использовать потоковую обработку, разбивать данные на пакеты, увеличить выделенную память |
| Некорректные результаты вычислений | Пропущенные значения или дублирующиеся записи | Очистить и нормализовать данные перед обработкой, использовать контрольные точки |
Применение этих методов позволяет минимизировать повторение ошибок, ускорить диагностику и поддерживать стабильность выполнения операций на всех этапах.
Оптимизация процесса под конкретные условия
Для повышения скорости обработки и точности результатов важно адаптировать процесс под текущие условия работы. Основные параметры для оптимизации включают объем данных, доступные ресурсы и требования к точности вычислений.
Рекомендации по настройке:
- Использование многопоточности при объеме данных свыше 500 тыс. записей сокращает время обработки на 30–45%.
- Кэширование промежуточных результатов уменьшает нагрузку на процессор при повторных запусках и ускоряет обработку на 20–25%.
- Настройка параметров алгоритмов под конкретные диапазоны данных. Например, при работе с числовыми массивами размер блока 10–20 тыс. элементов оптимизирует использование памяти.
- Применение фильтрации и предварительной сортировки данных снижает количество ошибок и ускоряет выполнение ключевых операций.
Регулярная проверка времени выполнения и корректности промежуточных результатов позволяет корректировать параметры на ходу и обеспечивать стабильность процесса даже при изменении исходных условий.
Использование дополнительных функций и возможностей
Расширение функционала инструментов позволяет ускорить обработку данных и повысить точность результатов. Важно выбирать функции, которые соответствуют объему данных и специфике задачи.
Рекомендации по применению:
- Автоматическое логирование операций помогает выявлять ошибки и анализировать производительность без вмешательства пользователя.
- Использование встроенных фильтров и сортировки на этапе подготовки данных сокращает время обработки на 15–25%.
- Функции интеграции с внешними сервисами позволяют получать обновленные данные и расширять возможности анализа без ручного импорта.
- Применение модулей мониторинга ресурсов обеспечивает контроль использования памяти и процессора, предотвращая перегрузки при больших объемах данных.
Комплексное использование этих возможностей повышает стабильность выполнения операций, снижает вероятность ошибок и делает процесс более предсказуемым и управляемым.
Проверка результатов и контроль качества
Для гарантии корректности выполнения операций необходим систематический контроль промежуточных и итоговых результатов. Отсутствие проверки может привести к накоплению ошибок и снижению точности анализа на 15–30%.
Основные этапы проверки:
- Сравнение промежуточных данных с контрольными точками. Позволяет выявить несоответствия до завершения всей обработки.
- Использование автоматических тестов для проверки формата, диапазонов и допустимых значений. Это сокращает ручной труд и исключает пропуск ошибок.
- Визуальная инспекция ключевых метрик и статистик. Рекомендуется проводить при больших объемах данных хотя бы для 5–10% выборки.
Рекомендации по поддержанию качества:
- Регулярное резервное копирование результатов на каждом этапе. Предотвращает потерю данных при сбоях.
- Ведение логов и отчетов по выполненным операциям. Позволяет быстро идентифицировать шаги с возможными проблемами.
- Сравнение итогов с предыдущими запусками или контрольными наборами. Это помогает оценить стабильность и корректность процесса.
Соблюдение этих процедур обеспечивает надежность результатов, минимизирует ошибки и позволяет адаптировать процесс под изменяющиеся условия работы.
Вопрос-ответ:
Какие критерии учитывать при выборе инструментов для задачи?
При выборе инструментов нужно оценивать совместимость с используемыми библиотеками, поддержку обработки больших массивов данных, наличие функций для автоматизации повторяющихся операций и возможности масштабирования. Например, для потоковых данных предпочтительно использовать инструменты с асинхронной обработкой и встроенным кэшированием.
Как правильно подготовить рабочее окружение для проекта?
Необходимо создать отдельное виртуальное окружение, установить актуальные версии интерпретатора и библиотек, настроить переменные окружения и пути к ресурсам. Также важно проверить доступность дискового пространства, прав на запись и сетевых соединений, а затем провести тестовый запуск на небольшой выборке данных для выявления ошибок конфигурации.
Какие шаги следует соблюдать при пошаговом выполнении операций?
Последовательность включает импорт данных и проверку формата, очистку и нормализацию, выполнение вычислений с использованием многопоточности при больших объемах, проверку промежуточных результатов с контрольными точками и сохранение данных с резервным копированием. Такая схема снижает риск ошибок и обеспечивает стабильность обработки.
Как выявлять и исправлять типичные ошибки при обработке данных?
Необходимо отслеживать сбои при импорте файлов, конфликты версий библиотек, ошибки при больших объемах данных и некорректные результаты вычислений. Для каждого типа ошибки следует определить причину и применить конкретное решение: корректировка формата файлов, создание виртуального окружения с совместимыми версиями библиотек, использование потоковой обработки и очистка данных от дубликатов и пропущенных значений.