Содержание статьи

При работе с временными данными в pandas разработчики регулярно сталкиваются с особым значением NaT – Not a Time. Оно появляется в тех же ситуациях, где для чисел используется NaN, но предназначено строго для дат и времени. NaT сигнализирует о пропущенном, некорректном или невозможном для интерпретации временном значении и встроено на уровне ядра pandas, а не является просто соглашением.
NaT возникает при парсинге дат из строк, при арифметике с временными интервалами, при объединении наборов данных с несовпадающими временными индексами. Например, при использовании pd.to_datetime() с ошибочными строками или при вычитании дат, где одна из них отсутствует. Понимание механики NaT позволяет предсказуемо управлять результатами фильтрации, агрегаций и сравнений.
В отличие от None и NaN, NaT подчиняется собственным правилам поведения. Он всегда распространяется в операциях с датами, не равен самому себе и влияет на методы resample, groupby и временные сдвиги. Ошибочное игнорирование NaT часто приводит к искажённым временным рядам, неверным интервалам и сбоям при анализе логов, транзакций или событий.
Грамотная работа с NaT включает его явное обнаружение, осознанную замену или исключение из вычислений. Pandas предоставляет для этого специализированные методы, такие как isna(), notna() и инструменты заполнения временных пропусков. Без понимания роли NaT корректный анализ временных данных в pandas невозможен.
Pandas NaT: что это и как используется
NaT появляется в данных в строго определённых ситуациях:
- ошибки при преобразовании строк в даты через pd.to_datetime() с параметром errors=»coerce»;
- пропуски в исходных временных столбцах CSV, Excel, SQL;
- результат арифметики дат, если хотя бы один операнд отсутствует;
- объединение наборов данных с несовпадающими временными индексами.
NaT ведёт себя иначе, чем NaN и None. Любое сравнение с NaT возвращает False, включая проверку на равенство с самим собой. Это влияет на фильтрацию и условия:
- выражение series == pd.NaT не выявляет пропуски;
- для проверки требуется использовать isna() или notna();
- методы агрегации автоматически исключают NaT из расчётов интервалов.
При работе с временной арифметикой NaT распространяется на результат:
- вычитание даты и NaT возвращает NaT;
- разница между временными метками с пропуском не вычисляется;
- сдвиги (shift) сохраняют NaT на границах данных.
Для управления NaT используются специализированные операции:
- заполнение фиксированной датой через fillna();
- удаление строк с NaT в ключевых столбцах с помощью dropna();
- замена на вычисляемые значения, например предыдущую дату через ffill;
- отдельная обработка временных пропусков перед resample и groupby.
Корректное понимание NaT позволяет избежать логических ошибок при анализе временных рядов, расчёте интервалов, обработке событий и журналов. Игнорирование его особенностей приводит к скрытым пропускам в результатах и некорректным временным зависимостям.
Что означает NaT в pandas и чем он отличается от None и NaN
В отличие от NaT, значение None относится к объектной модели Python и не предназначено для временной математики. При наличии None столбец дат часто приводится к типу object, что блокирует использование операций resample, dt-аксессоров и векторных сравнений.
NaN применяется для числовых данных и реализован на уровне NumPy. Он может присутствовать в pandas, но не несёт семантики даты или времени. При попытке использовать NaN в столбце datetime64[ns] pandas автоматически приводит его к NaT, сохраняя тип столбца.
Ключевые различия между NaT, None и NaN проявляются в поведении операций:
- NaT поддерживает временные типы и не ломает структуру данных;
- None приводит к потере специализированного временного типа;
- NaN не используется напрямую в датах и заменяется на NaT.
Сравнения с NaT работают по строгим правилам:
- NaT не равен ни одному значению, включая самого себя;
- условия вида == и != не выявляют NaT;
- для проверки применяются только isna() и notna().
При проектировании пайплайнов обработки данных рекомендуется:
- использовать NaT для всех временных пропусков;
- избегать None в столбцах с датами;
- приводить строки к датам через pd.to_datetime() с явной обработкой ошибок;
- проверять наличие NaT перед вычислением интервалов и агрегаций.
Выбор правильного типа пропуска напрямую влияет на корректность временных расчётов и стабильность аналитического кода.
В каких типах данных pandas появляется NaT (DatetimeIndex, Series, DataFrame)
NaT присутствует во всех структурах pandas, которые поддерживают временные типы данных. Его появление напрямую связано с использованием datetime64[ns], timedelta64[ns] и производных от них объектов. При этом NaT сохраняет тип данных и не нарушает векторные операции.
В DatetimeIndex NaT используется для обозначения отсутствующих или некорректных временных меток. Он может появиться при создании индекса через pd.to_datetime(), при объединении индексов с разным набором дат или при смещении значений методом shift. DatetimeIndex с NaT остаётся полностью функциональным для срезов, сортировки и ресемплинга.
В Series NaT встречается в столбцах с типом datetime64[ns] или timedelta64[ns]. Он возникает при загрузке данных из внешних источников, преобразовании строк, а также при вычислении разницы между датами. Series с NaT поддерживает dt-аксессор, что невозможно при наличии None.
В DataFrame NaT используется внутри отдельных столбцов или в индексах строк. Каждый временной столбец хранит NaT независимо от других данных. При операциях объединения (merge, join) NaT появляется в строках, где отсутствует соответствующая временная метка. Это поведение сохраняет согласованность данных без приведения типов.
Важно учитывать, что NaT не распространяется на числовые или строковые столбцы DataFrame. Его область применения строго ограничена временными структурами, что позволяет pandas выполнять специализированные операции без дополнительных проверок типов.
При проектировании структуры данных рекомендуется заранее определять временные столбцы и индексы, чтобы все пропуски дат автоматически представлялись в виде NaT, а не смешивались с другими типами значений.
Как NaT возникает при преобразовании строк в даты и времени

Наиболее частая причина появления NaT – преобразование строковых значений в даты с помощью pd.to_datetime(). Если строка не соответствует ожидаемому формату или содержит логически некорректную дату, pandas не генерирует исключение при использовании параметра errors=»coerce», а заменяет результат на NaT, сохраняя тип datetime64[ns].
NaT появляется при обработке следующих строковых значений:
строки с невозможными датами, например 2023-02-30 или 2024-13-01;
значения с нарушенной структурой даты, включая лишние символы и обрывы;
пустые строки и явно отсутствующие значения;
смесь форматов, не поддающаяся автоматическому распознаванию.
При указании параметра format pandas строго сопоставляет строку с шаблоном. Любое расхождение приводит к NaT, даже если дата визуально корректна. Это поведение используется для контроля качества данных и выявления отклонений в источнике.
Если параметр errors не задан, pandas выбрасывает исключение и останавливает выполнение. Применение errors=»coerce» рекомендуется в потоках загрузки данных, где важна непрерывная обработка и последующий анализ пропусков.
Для минимизации количества NaT следует:
предварительно очищать строки от лишних символов;
унифицировать форматы дат до вызова преобразования;
явно задавать часовой пояс, если данные содержат временные смещения;
анализировать долю NaT сразу после конвертации.
Осознанное использование NaT при парсинге строк позволяет сохранить структуру временных данных и выявить проблемные записи без потери совместимости с остальными операциями pandas.
Поведение NaT при сравнении дат и выполнении логических операций
NaT подчиняется строгим правилам при сравнении дат и участии в логических выражениях. Он рассматривается как неизвестное временное значение, поэтому не может быть корректно сопоставлен ни с одной датой, включая самого себя. Это поведение встроено на уровне pandas и не зависит от типа контейнера.
При использовании операторов сравнения результат всегда предсказуем:
- выражения NaT == любая_дата и NaT == NaT возвращают False;
- операции <, >, <=, >= с участием NaT возвращают False;
- условия на основе таких сравнений автоматически исключают строки с NaT.
Это напрямую влияет на фильтрацию временных данных. Если в логическом выражении используется только сравнение с датой, строки с NaT не попадают в результат, даже если ожидается их отдельная обработка.
Для корректного выявления NaT применяются специализированные методы:
- isna() – возвращает True только для NaT и других пропусков;
- notna() – позволяет исключить строки без временных значений;
- комбинация логических условий с явной проверкой NaT.
В логических операциях and, or, &, | NaT не приводит к ошибке, но может менять итоговую маску. Например, объединение условий без предварительной фильтрации NaT часто даёт неполный результат.
Рекомендуется:
- всегда проверять наличие NaT перед сложными логическими условиями;
- отделять фильтрацию пропусков от сравнений дат;
- не использовать операторы равенства для поиска NaT.
Понимание этих правил позволяет строить предсказуемые фильтры и избегать скрытых потерь данных при анализе временных рядов.
Как NaT влияет на арифметику дат и вычисление временных интервалов
NaT напрямую участвует в арифметике дат и временных интервалов, распространяясь на результат любой операции. Если хотя бы один операнд содержит NaT, итоговое значение также становится NaT. Это правило применяется к сложению, вычитанию, смещению дат и вычислению разницы между временными метками.
При вычислении интервалов между датами pandas возвращает тип timedelta64[ns]. Наличие NaT делает интервал неопределённым, что предотвращает появление ошибочных числовых значений и сохраняет семантику пропуска.
| Операция | Результат при наличии NaT |
|---|---|
| Дата − NaT | NaT |
| NaT − Дата | NaT |
| Дата + интервал (NaT) | NaT |
| Разница двух дат, одна из которых NaT | NaT |
Методы агрегации временных интервалов учитывают NaT особым образом. При расчёте среднего, минимума или максимума значения NaT автоматически исключаются. Если все элементы интервала равны NaT, результат также будет NaT.
При использовании операций shift, diff и rolling NaT появляется на границах данных или в местах разрыва временной последовательности. Это поведение используется для сохранения корректной длины Series и DataFrame без смещения индексов.
Практические рекомендации при работе с арифметикой дат:
проверять наличие NaT до вычисления интервалов;
явно обрабатывать NaT перед агрегированием временных разниц;
не заменять NaT на фиктивные даты без анализа контекста;
использовать NaT как индикатор недостоверных или отсутствующих временных значений.
Такое поведение NaT делает расчёты с датами предсказуемыми и предотвращает появление скрытых ошибок в логике временного анализа.
Методы обнаружения и проверки NaT в данных pandas
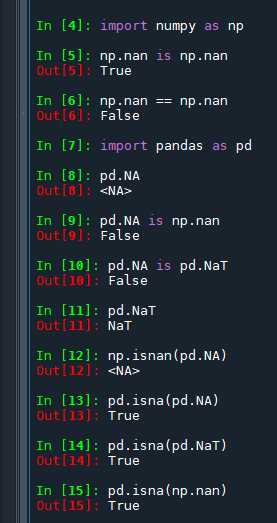
Для корректной работы с временными данными pandas предоставляет специализированные инструменты обнаружения NaT. Использование операторов сравнения для этой задачи недопустимо, так как NaT не равен самому себе и не участвует в логике равенства.
Основной способ проверки – метод isna(). Он корректно выявляет NaT во всех временных структурах, включая DatetimeIndex, Series и столбцы DataFrame. Метод работает векторно и возвращает булеву маску, пригодную для фильтрации и анализа.
Обратная проверка выполняется через notna(). Она используется для отбора строк с валидными временными значениями перед вычислением интервалов, сортировкой и агрегациями. Это особенно важно при построении временных рядов и событийных последовательностей.
Для индексов дат применяются те же методы:
index.isna() позволяет определить позиции пропущенных временных меток;
index.notna() используется для очистки временной оси без изменения данных.
При анализе источников данных рекомендуется сразу проверять долю NaT после преобразования строк в даты. Высокая концентрация NaT указывает на ошибки формата, несогласованные часовые пояса или повреждённые записи.
В потоках обработки данных практикуется следующая последовательность:
явное приведение строк к датам;
проверка NaT через isna();
логирование или изоляция проблемных строк;
дальнейшие вычисления только над валидными временными значениями.
Использование специализированных методов проверки NaT обеспечивает предсказуемое поведение фильтров и защищает временную аналитику от скрытых пропусков.
Способы замены, заполнения и удаления значений NaT
Управление значениями NaT выполняется стандартными инструментами pandas для работы с пропусками, но с учётом временной специфики. Все операции должны сохранять тип datetime64[ns] или timedelta64[ns], иначе дальнейшие временные вычисления становятся недоступными.
Для замены NaT используется метод fillna(). Он позволяет подставить фиксированную дату, вычисленное значение или результат сдвига. Замена подходит для сценариев, где отсутствие времени имеет однозначную бизнес-логику, например подстановка даты начала периода.
Автоматическое заполнение применяется при наличии упорядоченной временной последовательности:
метод ffill копирует предыдущее валидное значение;
метод bfill использует следующее доступное значение;
оба варианта сохраняют непрерывность временного ряда.
| Метод | Назначение |
|---|---|
| fillna(дата) | Явная замена NaT фиксированным значением |
| ffill | Заполнение на основе предыдущей даты |
| bfill | Заполнение на основе следующей даты |
| dropna | Удаление строк или индексов с NaT |
Удаление NaT выполняется через dropna(). Метод применяется к Series, DataFrame и индексам. Он используется в случаях, когда строки с пропущенными датами не подлежат восстановлению или искажают расчёт интервалов.
При работе с временными индексами удаление NaT часто предпочтительнее замены, так как индекс с пропусками может приводить к некорректному ресемплингу и смещениям оконных вычислений.
Рекомендации по выбору стратегии:
использовать замену только при наличии логически обоснованной даты;
применять заполнение для непрерывных временных рядов;
удалять NaT перед вычислением разниц и сортировкой;
проверять результат после каждой операции с временными пропусками.
Осознанное управление NaT сохраняет корректность временной структуры данных и предотвращает появление ложных интервалов и смещённых дат.
Типичные ошибки при работе с NaT и как их избежать на практике
Распространённая ошибка – попытка сравнивать NaT с датами или с самим собой через операторы равенства. Такие проверки всегда возвращают ложный результат и приводят к тому, что строки с пропущенными временными значениями незаметно исключаются из выборок. Единственный корректный способ проверки – использование isna() и notna().
Ещё одна частая проблема – смешивание NaT и None в одном столбце. Это приводит к приведению типа к object, отключению dt-аксессора и невозможности выполнять временную арифметику. Следует заранее приводить данные к типу datetime64[ns] и заменять все пропуски исключительно на NaT.
Ошибки возникают и при неявном появлении NaT во время преобразования строк. Использование pd.to_datetime() без анализа результата скрывает некорректные записи. После конвертации необходимо сразу проверять количество NaT и выявлять причины их появления, особенно при работе с внешними источниками данных.
При вычислении интервалов часто игнорируется влияние NaT на результат. Если не отфильтровать пропуски заранее, операции diff, вычитание дат и оконные расчёты возвращают NaT, что может быть ошибочно интерпретировано как нулевой интервал.
Некорректной практикой является замена NaT на фиктивные даты без контекста. Такие подстановки искажают временные зависимости, нарушают сортировку и дают ложные интервалы. Замена допустима только при наличии чёткой логики или бизнес-правила.
Для предотвращения ошибок рекомендуется:
всегда проверять временные данные на NaT после загрузки и преобразований;
не использовать операторы сравнения для поиска пропусков;
изолировать обработку NaT от основной логики анализа;
контролировать типы данных после каждой операции с датами.
Следование этим правилам позволяет избежать скрытых искажений и сохранить корректность анализа временных данных в pandas.
Вопрос-ответ:
Почему при сравнении столбца с датами с конкретной датой строки с NaT пропадают из результата?
NaT рассматривается pandas как неопределённое временное значение. Любое сравнение через операторы равенства или неравенства с участием NaT возвращает False. В результате строки с пропущенными датами не удовлетворяют условию и автоматически исключаются. Для корректной логики такие строки нужно обрабатывать отдельно, применяя isna() или комбинируя проверку NaT с основным условием фильтрации.
Почему после появления NaT в столбце с датами перестают работать операции через dt?
Сами значения NaT не отключают dt-аксессор. Проблема возникает, когда вместе с NaT в столбце присутствует None или строковые значения. В этом случае pandas переводит столбец в тип object, и доступ к dt теряется. Решение — привести весь столбец к datetime64[ns] через pd.to_datetime() и использовать только NaT для обозначения пропусков.
Как отличить NaT, полученный из-за ошибки формата даты, от NaT из реального пропуска данных?
Различие определяется контекстом появления. Если NaT появился после pd.to_datetime() с errors=»coerce», его стоит сопоставить с исходной строкой. Ошибки формата обычно связаны с невозможными датами, разным порядком компонентов или лишними символами. Реальные пропуски чаще приходят как пустые значения из источника данных. Проверка исходного столбца до преобразования помогает разделить эти случаи.
Можно ли безопасно заменять NaT на фиксированную дату перед расчётом интервалов?
Замена допустима только при наличии чёткого правила, объясняющего выбор даты. Произвольная подстановка создаёт ложные интервалы и искажает порядок событий. Если логика отсутствует, правильнее исключить строки с NaT из расчётов или выполнять операции только над валидными датами, сохраняя NaT как индикатор отсутствия времени.