Содержание статьи

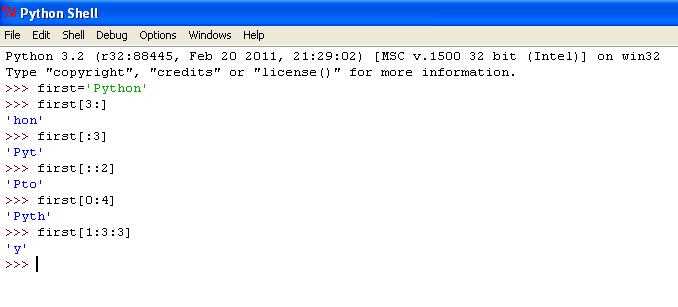
В Python строки являются упорядоченными последовательностями символов, что позволяет легко получать доступ к отдельным элементам. Для преобразования строки в список символов можно использовать встроенную функцию list(), которая сразу создаёт список из всех символов исходной строки.
Генераторы списков предоставляют альтернативный подход, позволяя создавать новые списки с применением условий или преобразований к каждому символу. Например, можно получить список только букв или символов, удовлетворяющих определённому критерию, используя if внутри генератора.
При обработке больших текстов важно учитывать специфику Unicode-символов. Обычное обращение к строке через индексы работает для большинства символов, но для символов за пределами Basic Multilingual Plane требуется использовать функции, корректно работающие с кодовыми точками, чтобы избежать разделения одного визуального символа на несколько элементов.
Для обратного преобразования списка символов в строку применяется метод join(), который позволяет объединять элементы с указанием любого разделителя или без него. Этот подход удобен при необходимости модификации отдельных символов и последующего восстановления исходной строки.
Комбинация циклов for, функций map() и лямбда-выражений даёт гибкость при обработке строк с разной структурой. Можно одновременно изменять регистр, фильтровать символы или выполнять другие преобразования, получая на выходе сразу готовый список символов.
Использование функции list() для преобразования строки в список символов
Функция list() принимает строку и возвращает список, где каждый элемент соответствует отдельному символу исходного текста. Например, list(«Python») создаёт список [‘P’, ‘y’, ‘t’, ‘h’, ‘o’, ‘n’]. Этот метод сохраняет порядок символов, включая пробелы и специальные символы.
Применение list() удобно при необходимости последующей обработки каждого символа, например, при подсчёте частоты появления или фильтрации по определённым условиям. Списки, полученные таким способом, поддерживают все стандартные операции Python для последовательностей, включая индексацию, срезы и методы append(), insert() и pop().
При работе с Unicode-строками функция list() корректно обрабатывает символы любой длины, создавая отдельный элемент для каждого визуального символа. Это позволяет безопасно модифицировать текст с кириллицей, китайскими и эмодзи-символами без риска разрыва символа на части.
Функция list() также полезна для быстрого создания копии строки в виде изменяемого объекта. Поскольку строки в Python неизменяемы, преобразование в список открывает возможность заменять отдельные символы и затем объединять их обратно в строку с помощью метода join().
Разделение строки с помощью генераторов списков
Генераторы списков позволяют создавать новый список символов на основе исходной строки с одновременным применением условий или преобразований. Например, выражение [c.upper() for c in «Python»] создаёт список [‘P’, ‘Y’, ‘T’, ‘H’, ‘O’, ‘N’], переводя все буквы в верхний регистр.
Можно фильтровать символы по типу, оставляя только буквы или цифры: [c for c in «Py123!@#» if c.isalpha()] вернёт [‘P’, ‘y’]. Такой подход сокращает количество дополнительных проверок и циклов при обработке текста.
Генераторы списков работают с любыми символами Unicode, включая кириллицу и эмодзи. Это позволяет формировать списки, где каждый элемент соответствует целому визуальному символу, без разбиения составных кодовых точек.
Использование генераторов также упрощает последующую обработку: можно комбинировать фильтрацию, изменение регистра и замену символов в одном выражении. Полученный список поддерживает стандартные методы Python, такие как append() или insert(), что облегчает дальнейшие манипуляции с текстом.
Преобразование строки в массив символов с помощью цикла for
Цикл for позволяет пошагово проходить по каждому символу строки и добавлять его в массив, обеспечивая полное управление процессом преобразования. Такой подход удобен, если требуется выполнить дополнительные действия с символами перед добавлением в список.
Пример базового использования:
- Создать пустой список: symbols = []
- Пройтись по строке: for c in «Python»:
- Добавить символ в список: symbols.append(c)
Цикл for позволяет сразу фильтровать и изменять символы:
- Удаление пробелов: if c != » «
- Преобразование в верхний или нижний регистр: c.upper() или c.lower()
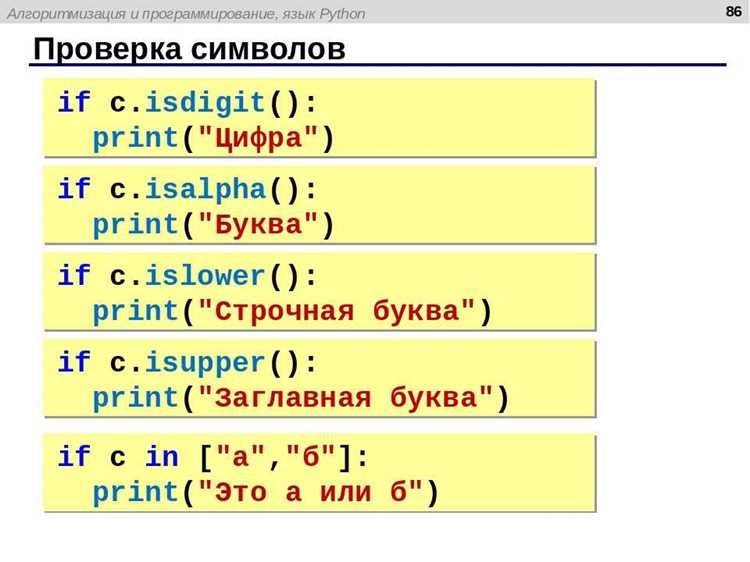
- Фильтрация по типу символа: c.isdigit(), c.isalpha()
Метод подходит для работы с Unicode-строками, включая составные символы, и позволяет строить массивы с точным набором элементов, готовых к дальнейшей обработке или объединению обратно в строку с помощью метода join().
Использование метода join() для объединения символов обратно в строку
Метод join() объединяет элементы списка символов в одну строку, сохраняя их порядок. Например, «».join([‘P’, ‘y’, ‘t’, ‘h’, ‘o’, ‘n’]) создаёт строку «Python». Пустая строка перед join() определяет отсутствие разделителя между символами.
Можно использовать любой разделитель, включая пробел или специальный символ: «-«.join([‘1’, ‘2’, ‘3’]) вернёт «1-2-3». Это удобно при форматировании текста или создании структурированных данных.
Метод join() работает с Unicode-символами, обеспечивая корректное объединение кириллицы, эмодзи и других символов вне Basic Multilingual Plane. Каждая кодовая точка сохраняется как единый элемент.
Для восстановления строки после обработки или фильтрации символов метод join() позволяет объединять только необходимые элементы, например:
- Объединение букв без пробелов: «».join([c for c in text if c.isalpha()])
- Формирование строки с разделителями: «, «.join(list_of_chars)
Метод join() эффективен для работы с большими массивами символов, так как создаёт новую строку без необходимости ручного конкатенирования через цикл, что снижает нагрузку на память и ускоряет выполнение кода.
Разделение строки на символы с сохранением пробелов и спецсимволов
Для сохранения всех символов, включая пробелы и спецсимволы, достаточно использовать стандартные методы Python, такие как list() или генераторы списков без фильтров. Например, list(«Привет, мир!») вернёт [‘П’, ‘р’, ‘и’, ‘в’, ‘е’, ‘т’, ‘,’, ‘ ‘, ‘м’, ‘и’, ‘р’, ‘!’].
Генераторы списков также позволяют сохранить пробелы и спецсимволы при одновременной модификации букв: [c.upper() for c in «Привет, мир!»] создаст [‘П’, ‘Р’, ‘И’, ‘В’, ‘Е’, ‘Т’, ‘,’, ‘ ‘, ‘М’, ‘И’, ‘Р’, ‘!’].
Цикл for с условием добавления каждого символа в список без исключений гарантирует, что ни один элемент исходного текста не будет потерян. Это особенно важно при работе с текстами, где пробелы и знаки препинания влияют на смысл или форматирование.
Метод join() позволяет затем собрать массив символов обратно в строку, полностью сохранив пробелы и спецсимволы: «».join(list_of_chars) восстанавливает оригинальный текст с точной структурой.
Работа с Unicode-символами при разбиении строки
Строки в Python полностью поддерживают Unicode, что позволяет обрабатывать тексты на любом языке и включать эмодзи. При разбиении строки на символы важно учитывать, что некоторые визуальные символы состоят из нескольких кодовых точек, например, эмодзи «👩💻».
Функция list() создаёт отдельный элемент для каждой кодовой точки, поэтому составные символы могут быть разделены на несколько элементов. Чтобы сохранить целостность таких символов, можно использовать нормализацию через модуль unicodedata: unicodedata.normalize(‘NFC’, text).
Циклы for и генераторы списков работают с Unicode-символами так же, как с обычными буквами, позволяя фильтровать, изменять регистр или заменять отдельные символы без нарушения кодировки.
При объединении символов обратно в строку метод join() сохраняет корректное отображение Unicode, обеспечивая точное восстановление исходного текста независимо от сложности символов.
Разделение строки на символы в контексте обработки больших текстов
При работе с большими текстами важно минимизировать использование операций, создающих множество промежуточных объектов. Преобразование строки в список символов через list() или генераторы списков остаётся эффективным, если последующая обработка ограничена необходимыми изменениями.
Рекомендации при обработке крупных данных:
- Использовать генераторы вместо списков, если требуется только итерация без хранения всех символов: (c for c in large_text)
- Применять фильтры и условия внутри генератора, чтобы избежать создания лишних элементов
- Обрабатывать текст блоками, если строка слишком длинная для памяти, например, читать и разбирать по строкам или частям
Циклы for с постепенным добавлением символов в список позволяют комбинировать фильтрацию, замену и подсчёт частоты символов без полного копирования текста. Это снижает нагрузку на оперативную память при обработке файлов размером в десятки мегабайт и больше.
Метод join() для объединения символов обратно в строку остаётся актуальным даже для больших массивов, если необходимо сформировать финальный текст после обработки. Оптимально объединять только обработанные или отфильтрованные символы, чтобы избежать ненужного выделения памяти.
Применение функций map() и lambda для преобразования строки в символы
Функция map() вместе с lambda позволяет применять преобразования к каждому символу строки без явного цикла. Например, list(map(lambda c: c.upper(), «Python»)) создаёт список [‘P’, ‘Y’, ‘T’, ‘H’, ‘O’, ‘N’].
Такой подход удобно использовать для массовой фильтрации или изменения символов:
| Задача | Пример кода | Результат |
|---|---|---|
| Преобразование в верхний регистр | list(map(lambda c: c.upper(), «abc»)) | [‘A’, ‘B’, ‘C’] |
| Фильтрация только букв | list(filter(lambda c: c.isalpha(), «a1!b2@»)) | [‘a’, ‘b’] |
| Замена пробелов на подчёркивания | list(map(lambda c: ‘_’ if c==’ ‘ else c, «a b c»)) | [‘a’, ‘_’, ‘b’, ‘_’, ‘c’] |
Метод позволяет объединять несколько операций за один проход по строке, что сокращает количество временных объектов и повышает читаемость кода при обработке текстов средней и большой длины.
Вопрос-ответ:
Как в Python быстро преобразовать строку в список символов?
Для преобразования строки в список символов можно использовать функцию list(). Например, list(«Python») создаёт список [‘P’, ‘y’, ‘t’, ‘h’, ‘o’, ‘n’]. Этот метод сохраняет порядок символов и включает пробелы и знаки препинания.
Можно ли фильтровать символы при разделении строки на отдельные элементы?
Да, генераторы списков позволяют сразу применять условия. Например, [c for c in «Py123!» if c.isalpha()] вернёт [‘P’, ‘y’], оставляя только буквы. Таким образом можно сразу исключить цифры, пробелы или спецсимволы.
Как обрабатывать Unicode-символы, чтобы эмодзи или составные символы не разделялись неправильно?
В Python строки поддерживают Unicode. Для сложных символов, таких как эмодзи «👩💻», можно использовать модуль unicodedata для нормализации строки: unicodedata.normalize(‘NFC’, text). Это сохраняет целостность составных символов при разбиении на отдельные элементы.
В чём преимущества использования функции map() и lambda для разделения строки на символы?
Функция map() вместе с lambda позволяет применять преобразования к каждому символу за один проход. Например, list(map(lambda c: c.upper(), «abc»)) вернёт [‘A’, ‘B’, ‘C’]. Такой подход полезен для массового изменения регистра, замены символов или фильтрации без дополнительных циклов.
Как правильно работать с большими текстами при разбиении на символы, чтобы не перегружать память?
Для больших строк рекомендуется использовать генераторы вместо создания полного списка символов, например (c for c in large_text). Также можно обрабатывать текст блоками или по строкам. Циклы for с добавлением символов в список по мере обработки позволяют фильтровать и изменять данные без создания множества промежуточных объектов, что снижает нагрузку на память.