Содержание статьи

Модуль intertools в Python предназначен для работы с итераторами и последовательностями данных на уровне стандартной библиотеки. Он предоставляет набор инструментов, которые позволяют обрабатывать большие объемы данных без предварительного преобразования их в списки или другие структуры, что особенно важно при работе с потоками, генераторами и результатами запросов.
Основная ценность intertools заключается в том, что он оперирует ленивыми вычислениями. Это означает, что элементы последовательности создаются по мере необходимости, а не загружаются целиком в память. Такой подход полезен при анализе логов, обработке файлов, работе с API и при решении задач комбинаторики, где количество возможных вариантов может быстро расти.
Intertools включает функции для объединения нескольких источников данных, пошагового ограничения итераций, фильтрации элементов по условиям и генерации комбинаций. Например, с его помощью можно последовательно обрабатывать несколько файлов как один поток, выбирать элементы до наступления заданного условия или формировать все возможные сочетания параметров для тестирования.
Понимание intertools особенно важно для разработчиков, которые работают с данными, пишут парсеры, автоматизируют вычисления или разрабатывают алгоритмы, чувствительные к потреблению памяти. Использование этого модуля позволяет писать компактный и предсказуемый код, опираясь на проверенные инструменты стандартной библиотеки Python.
Intertools в Python: что это и для чего нужен

Модуль предоставляет функции, которые либо создают новые итераторы, либо управляют уже существующими. Например, chain позволяет последовательно обходить несколько источников данных как один, а islice дает возможность получать строго заданный диапазон элементов без преобразования последовательности в список.
Отдельная группа инструментов intertools применяется для комбинаторных задач. Функции product, permutations и combinations используются при переборе вариантов параметров, генерации тестовых данных и моделировании сценариев. Они возвращают итераторы, что позволяет контролировать объем вычислений и не создавать лишние структуры данных.
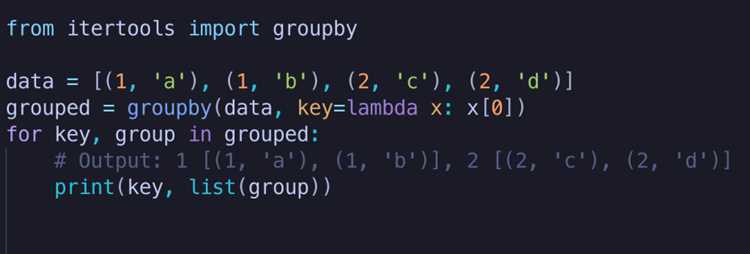
Intertools также полезен при агрегации и фильтрации данных. Функция groupby применяется для группировки элементов по ключу при условии предварительной сортировки, а takewhile и dropwhile помогают управлять процессом итерации на основе логических условий.
Использование intertools оправдано в задачах анализа данных, автоматизации, тестирования и разработки алгоритмов, где важны предсказуемое поведение итераций и контроль над потреблением ресурсов. Модуль позволяет решать такие задачи средствами стандартной библиотеки без подключения сторонних зависимостей.
Какие задачи решает модуль intertools при работе с последовательностями
Модуль intertools применяется в ситуациях, где требуется управлять обходом последовательностей без их копирования и преобразования в списки. Он решает задачи, связанные с комбинированием, ограничением и контролем порядка элементов при последовательной обработке данных.
Основные практические задачи, которые закрывает intertools:
- Последовательная обработка нескольких источников данных с помощью chain, что удобно при чтении данных из нескольких файлов или генераторов.
- Ограничение диапазона элементов без изменения исходной последовательности через islice, например при постраничной обработке результатов.
- Управление остановкой и пропуском элементов на основе условий с использованием takewhile и dropwhile.
- Синхронный обход нескольких последовательностей разной длины при помощи zip_longest, что актуально для объединения несбалансированных наборов данных.
Отдельный класс задач связан с перебором вариантов и комбинаций, которые часто возникают при тестировании, анализе параметров и генерации входных данных:
- Формирование декартовых произведений значений через product.
- Перебор всех возможных перестановок элементов с помощью permutations.
- Получение уникальных сочетаний фиксированной длины при помощи combinations.
Intertools также решает задачи логической группировки данных. Функция groupby позволяет объединять итерируемые элементы по ключу, что используется при анализе отсортированных логов, отчетов и результатов вычислений.
Применение intertools оправдано в сценариях, где важна пошаговая обработка данных, контроль порядка элементов и отказ от промежуточных коллекций, создающих лишнюю нагрузку на память.
Как использовать chain и zip_longest для объединения наборов данных
Функции chain и zip_longest из модуля intertools решают разные задачи объединения последовательностей и применяются в зависимости от структуры данных и требуемого результата. Обе работают с итераторами и не создают копий исходных наборов.
chain используется, когда необходимо последовательно обработать несколько наборов данных как единый поток. Элементы возвращаются строго в том порядке, в котором переданы исходные последовательности. Это удобно при объединении списков записей, результатов генераторов или данных, полученных из разных источников.
zip_longest применяется в случаях, когда требуется синхронно обходить несколько последовательностей, даже если их длины различаются. Функция продолжает итерацию до исчерпания самой длинной последовательности, подставляя заполнитель для отсутствующих значений.
| Функция | Тип объединения | Типовая задача | Особенность |
|---|---|---|---|
| chain | Последовательное | Объединение данных из нескольких источников | Не выравнивает элементы по позициям |
| zip_longest | Позиционное | Сопоставление наборов разной длины | Использует заполнитель для недостающих значений |
При использовании zip_longest рекомендуется явно задавать значение параметра fillvalue, чтобы избежать ошибок обработки и корректно отличать отсутствующие данные от реальных значений.
Выбор между chain и zip_longest зависит от логики объединения: если важен порядок следования элементов – используется chain, если требуется сопоставление по индексам – применяется zip_longest.
Применение product, permutations и combinations для перебора вариантов

Функции product, permutations и combinations из модуля intertools используются для генерации вариантов на основе исходных наборов данных. Они возвращают итераторы, что позволяет последовательно обрабатывать результаты и контролировать объем вычислений.
product формирует декартово произведение последовательностей. Эта функция применяется при переборе всех возможных сочетаний параметров, например при генерации конфигураций, сценариев тестирования или комбинаций входных данных. При указании параметра repeat можно моделировать повторяющиеся значения, что полезно при работе с фиксированным набором опций.
permutations создает все возможные упорядоченные перестановки элементов без повторений. Она используется в задачах, где порядок имеет значение: анализ вариантов маршрутов, подбор последовательностей действий или моделирование сценариев с уникальными элементами. Длина перестановки задается явно, что позволяет ограничивать количество возвращаемых результатов.
combinations предназначена для получения неупорядоченных сочетаний элементов без повторений. Типичные примеры применения включают выбор подмножеств параметров, анализ возможных групп и работу с наборами признаков, где порядок элементов не играет роли.
При использовании этих функций рекомендуется заранее оценивать потенциальное количество вариантов, так как рост числа элементов приводит к быстрому увеличению числа комбинаций. Для практических задач следует ограничивать длину перебора и обрабатывать результаты пошагово, не сохраняя их целиком в памяти.
Как groupby применяется для агрегации данных в отсортированных коллекциях
Функция groupby из модуля intertools используется для объединения соседних элементов последовательности по ключу. В отличие от группировок в базах данных или аналитических библиотеках, она не перестраивает данные, а работает строго в порядке их следования.
Ключевая особенность groupby заключается в требовании предварительной сортировки входной коллекции. Если элементы с одинаковым ключом не расположены подряд, они будут разбиты на несколько независимых групп, что напрямую влияет на корректность агрегации.
Типовой сценарий применения включает обработку журналов событий, отчетов и потоков данных, где записи уже упорядочены по времени, идентификатору или категории. После группировки каждая группа представляет собой отдельный итератор, который можно использовать для подсчета, суммирования или накопления значений.
При работе с groupby рекомендуется сразу преобразовывать группы в целевые агрегаты, так как повторный обход итератора невозможен. Например, для подсчета количества элементов или суммирования значений следует выполнять вычисления в момент получения группы.
Функция подходит для пошаговой агрегации данных в условиях ограниченной памяти и хорошо сочетается с генераторами и потоковой обработкой, где загрузка всей коллекции заранее недопустима.
Использование islice и takewhile для управления потоком итераций
Функции islice и takewhile из модуля intertools применяются для точного контроля процесса итерации без изменения исходной последовательности. Они работают с любыми итерируемыми объектами, включая генераторы и потоки данных.
islice позволяет извлекать элементы по диапазону, аналогично срезам списков, но без предварительного преобразования последовательности. Она принимает начальный индекс, конечную позицию и шаг, что делает ее удобной для постраничной обработки, ограничения объема входных данных и анализа фрагментов длинных итераторов.
takewhile используется для чтения элементов до тех пор, пока выполняется заданное логическое условие. Итерация прекращается при первом несоответствии предикату, что особенно полезно при обработке упорядоченных данных, таких как временные ряды или отсортированные записи.
При совместном использовании islice и takewhile можно строить цепочки обработки, в которых сначала ограничивается диапазон значений, а затем применяется логический фильтр. Такой подход позволяет гибко управлять потоком данных и исключать лишние вычисления.
Эти инструменты подходят для задач, где требуется точный контроль над количеством и условиями обработки элементов, особенно при работе с большими или потенциально бесконечными последовательностями.
Типовые ошибки при работе с intertools и способы их избежать
Одна из распространенных ошибок при использовании intertools – попытка повторного обхода итераторов. Функции модуля возвращают одноразовые объекты, и после исчерпания данных повторная итерация приводит к пустому результату. Чтобы избежать этого, агрегацию или преобразование следует выполнять в момент первого прохода.
Часто встречается некорректное применение groupby без предварительной сортировки входных данных. Это приводит к разбиению элементов с одинаковым ключом на несколько групп. Перед использованием groupby необходимо явно упорядочивать последовательность по ключу группировки.
Ошибки возникают и при работе с zip_longest, когда не задан параметр заполнителя. В таких случаях сложно отличить отсутствующее значение от реального элемента с тем же значением. Явное указание fillvalue упрощает последующую обработку данных.
Недооценка объема перебора при использовании product, permutations и combinations приводит к чрезмерному числу итераций и длительному выполнению кода. Перед запуском перебора рекомендуется оценивать количество возможных вариантов и ограничивать длину входных последовательностей.
Еще одна ошибка связана с использованием takewhile на неупорядоченных данных. При первом нарушении условия итерация прекращается, даже если подходящие элементы встречаются дальше. Для корректной работы необходимо либо сортировать данные, либо использовать другие механизмы фильтрации.
Вопрос-ответ:
Чем intertools отличается от обычных циклов for при работе с последовательностями?
Intertools предоставляет готовые итераторы, которые позволяют управлять порядком, длиной и логикой обхода данных без ручного написания вложенных циклов. Это снижает количество служебного кода и уменьшает риск логических ошибок, особенно при работе с генераторами и потоками данных.
Почему функции intertools часто возвращают итераторы, а не списки?
Итераторы создают элементы по мере запроса, а не заранее. Такой подход полезен при обработке больших последовательностей, чтении файлов построчно и работе с результатами API, где хранение всех данных в памяти не требуется.
В каких случаях лучше использовать chain вместо объединения списков через +?
Chain подходит для объединения нескольких итерируемых объектов, включая генераторы и файловые потоки. В отличие от оператора +, он не создает новую коллекцию и не копирует элементы, а возвращает единый поток значений.
Можно ли использовать groupby для группировки неотсортированных данных?
Groupby работает только с соседними элементами, поэтому без сортировки одинаковые ключи будут разбиты на несколько групп. Для корректной агрегации данные нужно заранее упорядочить по ключу группировки.
Опасно ли использовать product и permutations с большими наборами данных?
Да, количество возвращаемых вариантов растет очень быстро. Например, permutations из 10 элементов длиной 10 дает более 3 миллионов комбинаций. Перед использованием следует оценивать объем перебора и ограничивать длину входных последовательностей.
Когда имеет смысл выбирать intertools вместо стандартных функций filter и map?
Intertools подходит в ситуациях, где требуется не просто преобразовать элементы, а управлять самим процессом обхода последовательности. Например, при ограничении количества элементов через islice, остановке итерации по условию с помощью takewhile или объединении нескольких источников данных в один поток через chain. Filter и map решают задачи преобразования, а intertools — задачи контроля и структуры итерации.