В Python получение подсписков осуществляется через срезы (slicing) списков. Например, выражение my_list[2:5] вернёт элементы с индексами 2, 3 и 4, сохраняя исходный список без изменений. Такой подход позволяет быстро извлекать конкретные участки данных для дальнейшей обработки или анализа.
Подсписки можно создавать с шагом, указывая третий параметр среза. Выражение my_list[1:10:2] извлечёт каждый второй элемент из диапазона с 1 по 9. Это особенно удобно при работе с числовыми или текстовыми массивами, когда необходимо выбирать элементы с регулярным интервалом.
Sublist можно применять для изменения частей списка без пересоздания нового объекта. Например, my_list[0:3] = [7, 8, 9] заменяет первые три элемента на новые значения. Такой приём ускоряет обновление данных при обработке больших массивов, исключая лишние копирования.
Для проверки наличия последовательности внутри списка используется сравнение срезов или функции. Выражение sublist in my_list[i:j] позволяет определить, содержится ли набор элементов в заданном диапазоне, что облегчает фильтрацию и поиск повторяющихся паттернов в данных.
Подсписки также применяются для объединения данных из разных источников. Комбинация срезов с конкатенацией списков через оператор + позволяет создавать новые списки из выбранных фрагментов, сохраняя порядок и структуру элементов.
Создание подсписков с помощью срезов

В Python подсписки формируются через срезы с помощью квадратных скобок и двоеточий. Синтаксис list[start:end] возвращает элементы с индексом от start до end-1. Например, data[2:5] извлечёт третий, четвёртый и пятый элементы исходного списка data.
Если параметр start не указан, срез начинается с начала списка. Например, data[:4] вернёт первые четыре элемента. Аналогично, если end отсутствует, срез продолжается до конца списка: data[3:] выбирает все элементы начиная с индекса 3.
Срезы поддерживают отрицательные индексы, которые отсчитываются с конца списка. Выражение data[-5:-2] вернёт три элемента, начиная с пятого с конца и до второго с конца, не включая его. Это позволяет удобно получать элементы с конца без необходимости вычислять длину списка.
Третий параметр step задаёт шаг среза. Например, data[1:10:3] выбирает каждый третий элемент диапазона с индекса 1 по 9. Использование шага позволяет быстро формировать выборки с регулярным интервалом.
Срезы создают новый список и не изменяют исходный объект. Для больших массивов рекомендуется учитывать копирование данных, чтобы избежать лишней нагрузки на память. В случаях, когда требуется изменение оригинала, используют присваивание срезу, например: data[2:5] = [7, 8, 9].
Извлечение элементов по условию через sublist
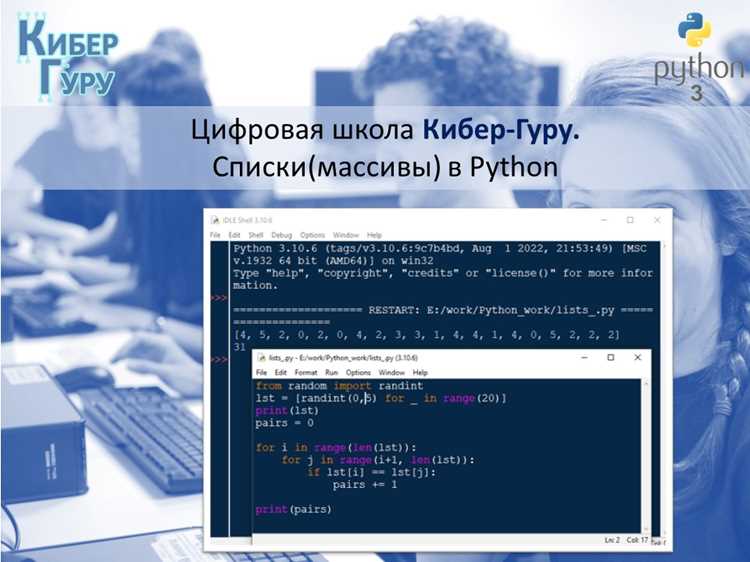
Для формирования подсписков по условию в Python используют генераторы списков и фильтрацию через if. Например, выражение [x for x in data if x > 10] создаёт новый список, включающий только элементы больше 10 из исходного списка data.
Подсписки можно ограничивать диапазоном индексов перед применением условия. Например, [x for x in data[2:8] if x % 2 == 0] выбирает только чётные элементы с третьего по восьмой элемент исходного списка, не изменяя остальную структуру.
Функция filter() также позволяет извлекать элементы по условию: list(filter(lambda x: x < 5, data)) возвращает все элементы меньше 5. Преимущество такого подхода в явной передаче функции-предиката и возможности комбинировать несколько условий.
Для сложных фильтров используют несколько критериев одновременно. Например, [x for x in data if x > 0 and x % 3 == 0] создаёт подсписок положительных чисел, кратных 3, что упрощает обработку числовых последовательностей без дополнительных циклов.
Применение условной фильтрации в подсписках помогает уменьшить объём данных для анализа и ускоряет вычисления при работе с большими массивами, сохраняя исходный список без изменений.
Обновление и замена подсписков в Python

В Python срезы позволяют изменять части списка напрямую без создания нового объекта. Для замены подсписка используют присваивание срезу:
- data[2:5] = [7, 8, 9] – заменяет элементы с третьего по пятый значениями 7, 8, 9.
- data[:3] = [0, 1, 2] – обновляет первые три элемента списка.
- data[4:] = [10, 11] – заменяет все элементы, начиная с пятого, на новые значения.
Можно изменять подсписки с шагом, что позволяет модифицировать выборочные элементы:
- data[1:10:2] = [100, 200, 300, 400, 500] – обновляет каждый второй элемент диапазона с индекса 1 по 9.
Замена подсписков поддерживает списки любой длины. Если количество новых элементов меньше, чем заменяемых, лишние удаляются. Если больше – список расширяется автоматически:
- data[2:4] = [5, 6, 7, 8] – подсписок увеличивается на новые элементы.
- data[0:3] = [1] – первые три элемента заменяются одним значением.
Применение обновления подсписков через срезы ускоряет обработку данных в больших массивах и сокращает использование циклов для последовательной модификации элементов.
Проверка наличия подсписка внутри списка

Определить, содержится ли один список в другом, можно с помощью перебора срезов или функций. Простейший метод – сравнение срезов длины подсписка с самим подсписком:
sublist = [2, 3, 4]
for i in range(len(data) — len(sublist) + 1):
if data[i:i+len(sublist)] == sublist:
print(«Найдено»)
Можно визуализировать проверку наличия подсписка в таблице:
| Исходный список | Подсписок | Срез | Совпадение |
|---|---|---|---|
| [1, 2, 3, 4, 5] | [2, 3, 4] | [1:4] = [2, 3, 4] | Да |
| [1, 2, 3, 4, 5] | [3, 5] | [2:4] = [3, 4] | Нет |
Для больших списков удобно использовать функцию any() с генератором срезов: any(data[i:i+len(sublist)] == sublist for i in range(len(data)-len(sublist)+1)). Это сокращает код и сохраняет читаемость при поиске подсписков.
Использование sublist для обработки больших списков

При работе с массивами свыше миллиона элементов прямое копирование всего списка может быть ресурсоёмким. Использование срезов позволяет выделять подсписки без изменения исходного массива: chunk = data[i:i+1000] создаёт блок из 1000 элементов для обработки.
Обработка подсписков помогает разбивать задачи на части и применять операции поэтапно:
- Анализ значений: sum(data[i:i+1000]) вычисляет сумму для каждого блока.
- Фильтрация: [x for x in data[i:i+500] if x > 50] извлекает элементы, удовлетворяющие условию, из каждой части.
- Модификация: data[i:i+200] = [x*2 for x in data[i:i+200]] изменяет элементы блока без пересоздания всего списка.
Использование подсписков с шагом позволяет пропускать элементы и оптимизировать вычисления: data[::100] выбирает каждый сотый элемент. Такой подход сокращает объём обрабатываемых данных и ускоряет выполнение задач на больших массивах.
Комбинирование подсписков для новых списков

В Python подсписки можно объединять для создания новых массивов с помощью оператора + или методов списков. Это позволяет формировать новые структуры данных без изменения исходных списков.
Примеры комбинирования подсписков:
- new_list = data[0:3] + data[5:8] – объединяет первые три и элементы с пятого по восьмой индекс.
- combined = [*data[:2], *data[4:6], *data[7:9]] – использует распаковку для объединения нескольких подсписков.
- segments = [data[i:i+3] for i in range(0, len(data), 3)] – делит список на блоки по 3 элемента и формирует список списков.
Комбинирование подсписков позволяет:
- Создавать выборочные массивы для анализа или визуализации.
- Объединять данные из разных диапазонов без циклов.
- Подготавливать блоки для пакетной обработки больших списков.
Использование срезов при комбинировании обеспечивает контроль за индексами и упрощает отбор нужных элементов без копирования всего списка целиком.
Вопрос-ответ:
Что такое sublist в Python и как его создать?
Sublist — это часть исходного списка, выделяемая с помощью срезов. Для создания подсписка используют синтаксис list[start:end], где start — начальный индекс, end — конечный (не включительно). Например, my_list[2:5] вернёт третий, четвёртый и пятый элементы.
Как выбрать элементы подсписка по определённому условию?
Для фильтрации подсписка используют генераторы списков или функцию filter(). Пример: [x for x in my_list if x > 10] создаёт подсписок с элементами больше 10. Можно комбинировать условия, например: [x for x in my_list if x > 0 and x % 2 == 0] для положительных чётных чисел.
Можно ли изменять элементы подсписка без копирования всего списка?
Да, присваивание срезу позволяет изменять элементы на месте. Например, my_list[1:4] = [7, 8, 9] заменяет три элемента с индексов 1, 2 и 3. Если новый список длиннее или короче заменяемого, длина исходного списка изменится автоматически.
Как проверить наличие подсписка внутри списка?
Для поиска подсписка используют перебор срезов или генераторы. Например: any(my_list[i:i+len(sublist)] == sublist for i in range(len(my_list)-len(sublist)+1)) возвращает True, если подсписок найден. Такой способ работает для любых списков, включая большие массивы данных.
Как объединять несколько подсписков в новый список?
Для комбинации подсписков используют оператор + или распаковку через *. Пример: new_list = my_list[0:3] + my_list[5:8] объединяет элементы с первых трёх и с пятого по восьмой индекс. Распаковка combined = [*my_list[:2], *my_list[4:6]] позволяет объединять произвольное количество подсписков.
Как использовать срезы для создания подсписков с определённым шагом в Python?
В Python срезы позволяют извлекать элементы с заданным шагом, используя третий параметр: list[start:end:step]. Например, my_list[1:10:2] создаёт подсписок из элементов с индексами 1, 3, 5, 7 и 9. Если шаг отрицательный, например my_list[9:0:-2], подсписок формируется в обратном порядке через каждый второй элемент. Такой подход упрощает выборку элементов через регулярные интервалы и сохраняет исходный список без изменений.