Содержание статьи

Speech Dispatcher представляет собой системный демон для управления синтезом речи на Linux и других UNIX-подобных системах. Он обеспечивает взаимодействие приложений с различными голосовыми движками, такими как Espeak NG, Festival или PicoTTS, через единый интерфейс. Это позволяет запускать озвучивание текста одновременно из нескольких программ без конфликтов потоков.
Основная функция Speech Dispatcher заключается в управлении очередями сообщений и приоритетами озвучивания. Пользователи могут настраивать задержки, уровень громкости, скорость и тон голоса для каждого потока. Такой подход позволяет реализовать уведомления системы, голосовые подсказки в приложениях и интеграцию с навигационными системами без дополнительного программирования для каждого движка.
Применение Speech Dispatcher в практических задачах включает автоматическую смену голосов и языков в зависимости от контекста, настройку пользовательских профилей и интеграцию с существующими приложениями через API. Диагностика работы демона осуществляется через логирование и тестовые команды, что позволяет быстро выявлять конфликты потоков и ошибки движков.
Speech Dispatcher: функции и применение в системах озвучивания

Speech Dispatcher выполняет роль посредника между приложениями и голосовыми движками, обеспечивая управление синтезом речи через единый интерфейс. Он поддерживает многопоточную обработку сообщений, что позволяет одновременно запускать озвучивание уведомлений, подсказок и системных сообщений без конфликтов.
Функции управления голосами включают настройку тембра, скорости, громкости и языка для каждого потока. Это позволяет адаптировать озвучивание под конкретные задачи: например, для навигационных систем используется более четкая и медленная речь, а для уведомлений системы – короткие и лаконичные сообщения.
Практическое применение охватывает интеграцию с Linux-приложениями через API, создание очередей сообщений с приоритетами, автоматическую смену голосов и языков в зависимости от контекста. Для диагностики используется логирование и тестовые команды, что позволяет выявлять ошибки синтеза речи и конфликты между движками без прерывания работы системы.
Рекомендации по настройке включают выделение отдельных потоков для критичных уведомлений, использование профилей голосов для разных задач и регулярную проверку совместимости движков с текущей версией демона. Такой подход снижает риск потери сообщений и повышает точность озвучивания.
Настройка Speech Dispatcher для разных голосовых движков
Для корректной работы Speech Dispatcher с несколькими голосовыми движками требуется настройка конфигурационных файлов speechd.conf и client.conf. Каждый движок подключается через отдельный модуль, указываемый в параметре Module с приоритетом и параметрами голосового синтеза.
Часто используются движки Espeak NG, Festival и PicoTTS. Espeak NG поддерживает широкий диапазон языков и быстрый отклик, Festival позволяет использовать более естественные голоса с управлением интонацией, а PicoTTS оптимизирован для устройств с ограниченными ресурсами.
Настройка включает выбор языка, тембра, скорости и громкости. Для разных задач рекомендуется создавать отдельные профили движков с фиксированными параметрами, чтобы приложения автоматически использовали нужный голос.
| Движок | Поддерживаемые языки | Особенности | Рекомендуемые сценарии |
|---|---|---|---|
| Espeak NG | 200+ | Малый вес, быстрый отклик | Уведомления, подсказки, навигация |
| Festival | 10+ | Естественная интонация, гибкая настройка | Презентации, обучающие приложения |
| PicoTTS | 5 | Низкие требования к ресурсам | Встраиваемые системы, IoT-устройства |
Рекомендации по интеграции включают проверку совместимости движков с текущей версией демона, тестирование задержек воспроизведения, настройку очередей сообщений и использование логирования для контроля корректности синтеза речи в разных профилях.
Управление одновременным воспроизведением нескольких потоков речи

Speech Dispatcher позволяет запускать несколько потоков озвучивания одновременно, используя систему очередей сообщений и приоритетов. Каждое приложение или процесс может отправлять текст на синтез речи через отдельный клиентский модуль, а демон распределяет задачи по доступным голосовым движкам.
Для корректного воспроизведения рекомендуется задавать приоритеты потоков в конфигурации client.conf. Критичные уведомления, например системные сигналы или предупреждения, получают высокий приоритет, а вспомогательные подсказки – низкий, что предотвращает прерывание важных сообщений.
Управление задержками воспроизведения и продолжительностью сообщений позволяет оптимизировать работу с несколькими источниками речи. Параметры QueueLength и Delay настраиваются индивидуально для каждого клиента, чтобы исключить наложение и обрыв потоков.
Рекомендовано использовать отдельные профили голосов для разных типов сообщений. Например, навигационные подсказки можно направлять на один голосовой движок, а системные уведомления на другой, что обеспечивает четкое различие потоков и повышает читаемость озвучиваемого текста.
Для диагностики одновременных потоков применяется логирование speech-dispatcher.log и тестовые команды speak -t «текст», что позволяет выявлять конфликты движков и корректировать параметры очередей без остановки демона.
Интеграция Speech Dispatcher с Linux-приложениями
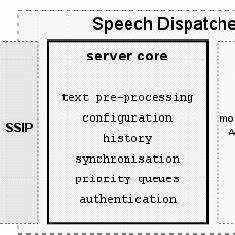
Speech Dispatcher предоставляет API и командный интерфейс для взаимодействия с Linux-приложениями через протоколы D-Bus и сокеты. Это позволяет запускать синтез речи из терминала, графических программ и фоновых сервисов без изменения кода движка.
Для интеграции приложений рекомендуется использовать libspeechd, библиотеку C, обеспечивающую управление голосами, приоритетами и очередями сообщений. Она поддерживает установку параметров тембра, скорости, громкости и языка для каждого клиентского процесса.
Программы на Python и других языках могут использовать обертки для Speech Dispatcher, что упрощает создание голосовых подсказок и уведомлений. Важно настраивать отдельные client profiles для различных типов сообщений, чтобы исключить наложение потоков и корректно распределять приоритеты.
Рекомендации включают тестирование интеграции через команды spd-say и логирование /var/log/speech-dispatcher.log для контроля правильности передачи сообщений. Настройка очередей сообщений и распределение задач между движками повышает стабильность озвучивания и предотвращает потерю уведомлений.
Использование Speech Dispatcher для уведомлений и сигналов системы

Speech Dispatcher позволяет озвучивать системные уведомления и сигналы, обеспечивая своевременное информирование пользователей. Поддерживаются различные типы сообщений, включая критические предупреждения, напоминания и информационные подсказки.
Для настройки уведомлений рекомендуется:
- Создать отдельные client profiles для системных сообщений и пользовательских подсказок.
- Назначить приоритеты потоков для критичных сигналов, чтобы они воспроизводились
Автоматическая смена голосов и языков в зависимости от контекста

Speech Dispatcher поддерживает динамическое переключение голосов и языков для разных типов сообщений. Это позволяет адаптировать озвучивание под конкретный сценарий, повышая читаемость и различимость информации.
Рекомендации по настройке автоматической смены:
- Создавать отдельные профили голосов для уведомлений, подсказок и навигационных сообщений.
- Использовать параметр Language в конфигурации для смены языка в зависимости от текста или приложения.
- Назначать разные голоса для критических сообщений и вспомогательных подсказок, чтобы они легко различались на слух.
- Определять правила переключения через context mapping или скрипты, которые анализируют источник и тип сообщения.
Примеры применения:
- Навигационные системы, которые переключаются на язык пользователя в зависимости от региона.
- Системные уведомления, озвучиваемые разными голосами для ошибок, предупреждений и информационных сообщений.
- Образовательные приложения, где подсказки и инструкции меняют язык в зависимости от выбранного курса или темы.
Для контроля корректности рекомендуется тестировать профили голосов с разными типами сообщений и отслеживать логирование через speech-dispatcher.log, чтобы убедиться, что смена голосов и языков происходит без задержек и наложений потоков.
Настройка приоритетов и очередей сообщений для озвучивания

Speech Dispatcher позволяет управлять последовательностью и важностью сообщений с помощью настроек приоритетов и очередей. Это обеспечивает корректное воспроизведение нескольких потоков речи без их наложения.
Приоритеты назначаются через конфигурационный файл client.conf и позволяют определить порядок обработки сообщений. Критические уведомления получают высокий приоритет, а информационные подсказки – низкий. Средний приоритет используется для стандартных системных сообщений.
Очереди сообщений контролируются параметрами QueueLength и Delay. QueueLength ограничивает количество сообщений в очереди, предотвращая её переполнение, а Delay задаёт минимальный интервал между воспроизведением последовательных сообщений, уменьшая риск их наложения.
Рекомендовано создавать отдельные очереди для разных типов сообщений и тестировать их с помощью команды spd-say или логирования /var/log/speech-dispatcher.log. Это позволяет контролировать корректность воспроизведения и вовремя корректировать настройки приоритетов и задержек.
Дополнительно полезно выделять отдельные голосовые движки для критических потоков и фоновых уведомлений, чтобы предотвратить блокировку важной информации при высокой нагрузке системы.
Диагностика и устранение проблем с воспроизведением речи
Для выявления сбоев в работе Speech Dispatcher используется логирование через /var/log/speech-dispatcher.log. В логах фиксируются ошибки и конфликты голосовых движков, проблемы с очередями и несоответствие параметров воспроизведения.
Рекомендации по диагностике:
- Использовать команду spd-say для проверки отдельных голосов и языков.
- Проверять состояние демона через systemctl status speech-dispatcher или ps aux | grep speech-dispatcher.
- Анализировать настройки client.conf и speechd.conf на корректность параметров голосов, приоритетов и очередей.
- Тестировать отдельные потоки сообщений для выявления конфликта между движками или задержек в очередях.
Устранение проблем включает обновление или смену голосового движка, корректировку приоритетов сообщений и проверку совместимости клиентских приложений с текущей версией демона. В случае повторяющихся сбоев рекомендуется временно отключить лишние потоки и постепенно включать их для выявления источника ошибки.
Регулярная проверка логов и тестирование командной утилитой позволяет поддерживать стабильное озвучивание и предотвращать потерю критических уведомлений в системах оповещения.
Вопрос-ответ:
Что такое Speech Dispatcher и для чего он используется в Linux-системах?
Speech Dispatcher — это демон, который управляет синтезом речи в Linux и других UNIX-подобных системах. Он позволяет приложениям отправлять текст на озвучивание через единый интерфейс и поддерживает работу с разными голосовыми движками, такими как Espeak NG, Festival и PicoTTS. Это упрощает создание уведомлений, подсказок и голосовых сигналов без прямой интеграции с конкретным движком.
Как настроить несколько голосовых движков одновременно в Speech Dispatcher?
Для работы с несколькими движками нужно настроить конфигурационный файл speechd.conf, где указываются используемые модули, языки, тембры и скорость воспроизведения. Для каждого движка можно создать отдельный профиль с параметрами очереди сообщений и приоритетов. Это позволяет запускать одновременное озвучивание уведомлений и подсказок без конфликтов потоков.
Каким образом можно управлять одновременным воспроизведением нескольких потоков речи?
Управление потоками осуществляется через систему очередей и приоритетов, задаваемых в client.conf. Критические уведомления получают высокий приоритет и воспроизводятся вне очереди, а второстепенные сообщения идут в очередь. Дополнительно рекомендуется выделять разные голосовые движки для фоновых и системных сообщений, чтобы избежать наложения потоков и пропусков важной информации.
Как интегрировать Speech Dispatcher с пользовательскими Linux-приложениями?
Для интеграции используется библиотека libspeechd и интерфейс D-Bus. Она позволяет приложению отправлять текст на синтез речи, управлять голосами, приоритетами и очередями сообщений. В языках программирования, таких как Python или C, существуют обертки, которые упрощают подключение к Speech Dispatcher. Для проверки работы интеграции можно использовать команду spd-say и логирование /var/log/speech-dispatcher.log.
Какие шаги помогают диагностировать и устранять проблемы с воспроизведением речи?
Для диагностики проверяются логи демона и тестируются отдельные команды через spd-say. Следует анализировать настройки файлов client.conf и speechd.conf, чтобы убедиться, что параметры голосов, приоритетов и очередей установлены корректно. При выявлении конфликтов между движками или задержек в очередях рекомендуется временно отключить лишние потоки, корректировать приоритеты и проверять совместимость клиентских приложений с демоном.
Как настроить приоритеты сообщений в Speech Dispatcher для разных типов уведомлений?
Приоритеты сообщений задаются в файле client.conf. Критические уведомления получают высокий приоритет и воспроизводятся вне очереди, а вспомогательные подсказки идут в очередь с низким приоритетом. Также можно использовать отдельные голосовые движки для разных типов сообщений, чтобы предотвратить наложение потоков и обеспечить слышимость важных сигналов.
Какие инструменты доступны для проверки работы Speech Dispatcher и устранения ошибок?
Для проверки работы используется команда spd-say для тестирования отдельных голосов и языков, а также логирование демона в /var/log/speech-dispatcher.log. Анализируются конфигурационные файлы client.conf и speechd.conf для корректности настроек голосов, очередей и приоритетов. При выявлении проблем рекомендуется временно отключать лишние потоки и постепенно возвращать их для локализации источника ошибки.