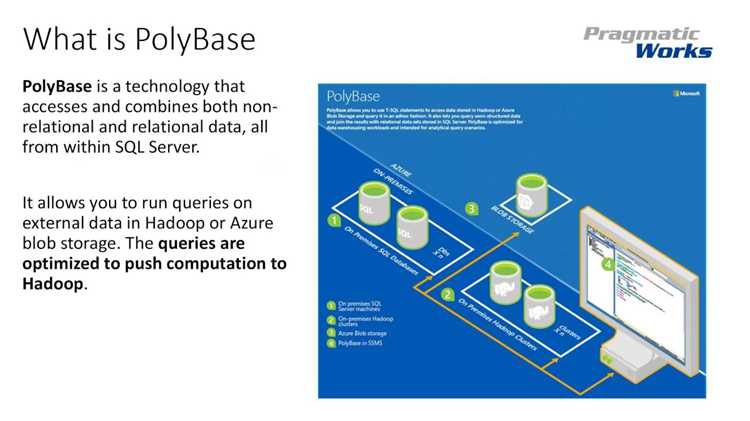
PolyBase предоставляет механизм прямого доступа к внешним наборам данных через привычный T-SQL. Функция позволяет обращаться к Hadoop, Azure Blob Storage, Azure Data Lake и совместимым системам без промежуточной загрузки. MS SQL обрабатывает такие запросы через внешние таблицы, сохраняя стандартную структуру работы с реляционными объектами.
В отличие от классического импорта, PolyBase использует оптимизированный компонент Data Movement Service, распределяющий операции чтения. Благодаря этому можно подключать файловые хранилища и анализировать данные в формате CSV, Parquet или ORC как локальные таблицы. Настройки задаются через объекты External Data Source, External File Format и External Table.
Практическая ценность PolyBase проявляется при работе с крупными файловыми каталогами, где важно минимизировать время ручных операций. Администратор задаёт параметры подключения и формат файлов, после чего запросы выполняются напрямую, включая фильтрацию, выборку и базовые преобразования. Такой подход снижает количество служебных шагов и упрощает интеграцию разных систем хранения.
PolyBase в MS SQL: что это и как работает

При обращении к такой таблице SQL Server использует компонент Data Movement Service. Он распределяет задачи между вычислительными узлами кластера или локальными ресурсами, что ускоряет обработку больших файловых наборов. Система поддерживает работу с CSV, Parquet и ORC, а также с контейнерами в облачных хранилищах.
Для включения PolyBase требуется установка соответствующих служб и настройка объектов External Data Source, External File Format и External Table. Эти элементы определяют тип подключения, особенности чтения файлов и структуру данных, доступных для запросов. Такой подход позволяет выполнять фильтрацию, выборку и агрегацию без предварительной загрузки файлов в базу.
Назначение PolyBase и его роль при работе с внешними источниками данных
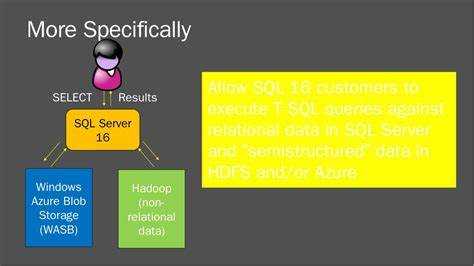
PolyBase задействуется для прямого обращения к файлам и распределённым хранилищам без промежуточной загрузки в локальные таблицы. Механизм позволяет объединять данные из Hadoop, Azure Blob Storage, Azure Data Lake и S3-совместимых систем в одном T-SQL-контуре, сохраняя единый подход к работе с выборками.
При использовании PolyBase SQL Server формирует внешние таблицы, где определены пути к наборам файлов и структура их чтения. Такой способ исключает создание временных копий и сокращает объём операций по подготовке данных. Ключевые объекты – External Data Source и External File Format – определяют параметры подключения и формат записей.
В сценариях, где требуется регулярный доступ к каталогам с большими файлами, PolyBase упрощает интеграцию: администратор один раз задаёт конфигурацию, после чего запросы применяются к источникам так же, как к локальным таблицам. Это позволяет выполнять фильтрацию, сортировку и агрегацию напрямую, что удобно при многократном анализе обновляемых файловых наборов.
Типы внешних источников, поддерживаемых PolyBase, и их особенности
PolyBase работает с несколькими классами хранилищ, отличающихся протоколами доступа, форматом файлов и правилами авторизации. Ниже перечислены основные варианты, применяемые в инфраструктуре MS SQL Server.
- Hadoop (HDFS) – подключается через WebHDFS. Подходит для каталогов с большим количеством файлов в форматах CSV, Parquet и ORC. Внешние таблицы позволяют выполнять запросы без копирования данных.
- Azure Blob Storage – используется при работе с контейнерами, где хранится сырьё аналитических процессов. Авторизация осуществляется через ключи или SAS-токены, что удобно для изолированных рабочих пространств.
- Azure Data Lake Storage Gen1/Gen2 – предоставляет доступ к дереву файлов с поддержкой ACL. Подходит для ситуаций, где требуется точное управление разрешениями и обработка больших файловых пакетов.
- S3-совместимые хранилища – подключаются через протоколы, поддерживающие работу с S3 API. Подходят для объединения источников из разных облачных провайдеров.
- ODBC-совместимые системы – позволяют подключать внешние СУБД и сервисы через шлюз ODBC. Полезно при миграции данных или анализе распределённых наборов из нескольких систем.
Перед созданием внешних таблиц необходимо уточнить формат файлов (CSV, Parquet, ORC), тип аутентификации и структуру каталогов. От этих параметров зависит корректность чтения данных и соответствие внешних таблиц фактической структуре источника.
Механизм создания External Data Source и его параметры

External Data Source определяет тип подключения и путь к внешнему хранилищу. Объект создаётся через инструкцию CREATE EXTERNAL DATA SOURCE с указанием протокола, местоположения файлов и параметров аутентификации. Для Azure Blob Storage и ADLS используется указание URL контейнера, для HDFS – адрес WebHDFS, для S3-совместимых систем – путь в формате s3://.
Ключевой параметр – LOCATION, задающий корневой каталог или конкретный endpoint. Значение должно указывать реальную структуру хранилища, чтобы внешние таблицы могли корректно обращаться к каталогам. При работе с облачными контейнерами желательно фиксировать нужный уровень структуры, чтобы избежать выбора лишних подкаталогов.
Для источников, требующих авторизации, применяется блок WITH CREDENTIAL. В нём указываются ключи доступа, SAS-токены или пары ключ/секрет. Если доступ к хранилищу открыт по IP или конфигурации firewall, объект создаётся без учётных данных.
После создания External Data Source проверяется доступность каталога с помощью простого запроса к внешней таблице или команды CREATE EXTERNAL TABLE с тестовой структурой. При ошибках обычно нужно уточнить протокол подключения, корректность пути или действительность ключей доступа.
Настройка External File Format для чтения файловых данных
External File Format определяет правила разбора файлов, доступных через внешние таблицы. Объект создаётся с помощью инструкции CREATE EXTERNAL FILE FORMAT, где задаются тип формата, структура разделителей и дополнительные параметры, влияющие на интерпретацию строк и столбцов.
- CSV – требует указания разделителя, символа окончания строки, кодировки и поведения при наличии кавычек. При работе с большими каталогами желательно фиксировать единый набор параметров, чтобы избежать расхождений между файлами.
- Parquet – не нуждается в дополнительных параметрах, так как структура хранится внутри файлов. Формат подходит для наборов данных с большим количеством столбцов и чётко определёнными типами.
- ORC – используется в Hadoop-средах. При создании формата достаточно указать тип ORC, остальная информация извлекается автоматически.
Параметр DATA_COMPRESSION применяется для форматов, поддерживающих встроенное сжатие. Его необходимо согласовывать с фактическим содержимым файлов, чтобы исключить ошибки на этапе чтения.
После создания External File Format рекомендуется выполнить тестовую выборку из небольшой внешней таблицы. Это помогает проверить корректность интерпретации строк, валидацию типов и соответствие структуры фактическим данным.
Создание External Table и связь с физическими данными
External Table используется для обращения к внешним данным через T-SQL. Таблица создаётся командой CREATE EXTERNAL TABLE, где указываются имена столбцов, их типы и связь с External Data Source и External File Format. Правильная настройка структуры обеспечивает корректное чтение файлов и сопоставление типов данных.
Пример структуры External Table:
| Столбец | Тип | Описание |
|---|---|---|
| OrderID | INT | Идентификатор заказа |
| CustomerName | NVARCHAR(100) | Имя клиента |
| OrderDate | DATE | Дата оформления заказа |
| TotalAmount | DECIMAL(10,2) | Сумма заказа |
Для корректной работы необходимо, чтобы External Data Source указывал на каталог с файлами, а External File Format соответствовал их формату. После создания таблицы можно выполнять выборки и агрегации, фильтровать строки по условиям и использовать JOIN с локальными таблицами, как с обычной SQL-таблицей.
Обработка запросов PolyBase: разбор этапов выполнения

При выполнении T-SQL-запроса к внешней таблице PolyBase проходит несколько этапов. Сначала SQL Server анализирует синтаксис и строит план запроса, включая операции над внешними источниками. В этом шаге определяется, какие столбцы и фильтры будут отправлены на удалённый источник.
Далее Data Movement Service распределяет задачи между вычислительными узлами или локальными ресурсами. Для каждого файла или каталога создаются блоки чтения, которые затем агрегируются и преобразуются в формат, совместимый с SQL Server.
На этапе выполнения происходит непосредственное считывание данных, фильтрация и частичная агрегация на стороне внешнего источника, если это поддерживается. Затем данные передаются в SQL Server для окончательной обработки и возврата результата пользователю.
Рекомендации для оптимизации:
- Использовать фильтры WHERE и проекции только необходимых столбцов, чтобы уменьшить объём передаваемых данных.
- Разбивать крупные каталоги на логические подкаталоги, чтобы Data Movement Service мог распределять задачи параллельно.
- Контролировать соответствие External File Format фактической структуре файлов для предотвращения ошибок чтения.
Использование PolyBase для импорта и экспорта больших наборов данных

PolyBase позволяет напрямую импортировать и экспортировать данные между MS SQL и внешними хранилищами без промежуточного копирования. Для импорта создаётся External Table с указанием источника и формата файлов, после чего данные можно вставлять в локальные таблицы с помощью INSERT INTO … SELECT.
Для экспорта применяется обратный принцип: локальные данные выбираются через T-SQL и направляются в внешние файлы, которые создаются в формате, поддерживаемом External File Format. Такой подход сокращает время передачи больших объёмов информации и уменьшает нагрузку на временные хранилища.
Рекомендации при работе с крупными наборами данных:
- Разбивать импортируемые и экспортируемые файлы на логические блоки для параллельной обработки.
- Использовать подходящие форматы файлов: Parquet или ORC для колоночных наборов, CSV для простого текстового обмена.
- Настраивать External Data Source с корректными параметрами авторизации и путями к каталогам.
- Проверять соответствие типов столбцов External Table и локальных таблиц, чтобы избежать ошибок конверсии при вставке.
Вопрос-ответ:
Что такое PolyBase в MS SQL и для чего его используют?
PolyBase — это компонент MS SQL Server, который позволяет выполнять T-SQL-запросы к внешним источникам данных, таким как Hadoop, Azure Blob Storage или S3-совместимые хранилища. С его помощью можно обращаться к большим наборам файлов напрямую, без предварительной загрузки в локальные таблицы, что упрощает интеграцию и обработку данных.
Какие форматы файлов поддерживаются при работе с PolyBase?
PolyBase поддерживает чтение файлов в форматах CSV, Parquet и ORC. CSV подходит для простых текстовых наборов, Parquet — для колоночных данных с большим количеством столбцов, ORC применяется преимущественно в Hadoop-средах. Выбор формата влияет на производительность и корректность обработки столбцов.
Как настроить подключение к внешнему источнику через PolyBase?
Для подключения используется объект External Data Source, в котором указываются тип хранилища, путь к файлам и параметры авторизации. В случае облачных хранилищ можно использовать ключи доступа или SAS-токены. После создания источника можно создавать внешние таблицы, которые напрямую ссылаются на данные в этом хранилище.
В чем разница между External Table и обычной таблицей SQL?
External Table отображает данные, находящиеся вне MS SQL, без их физического копирования в базу. Она использует ссылку на External Data Source и External File Format, чтобы выполнять выборку и фильтрацию напрямую на внешнем хранилище. Обычная таблица хранит данные локально внутри базы, что требует дополнительных операций для импорта или экспорта.
Какие рекомендации по оптимизации запросов через PolyBase?
Для ускорения работы рекомендуется использовать фильтры WHERE и выбирать только необходимые столбцы, чтобы уменьшить объём передаваемых данных. Также полезно разбивать большие каталоги на подкаталоги для параллельной обработки и проверять соответствие структуры External File Format фактическим файлам. Это снижает вероятность ошибок и повышает скорость выборки.
Как PolyBase обрабатывает большие объёмы данных из внешних источников?
PolyBase распределяет задачу чтения данных между узлами SQL Server или локальными ресурсами с помощью компонента Data Movement Service. Данные считываются блоками, выполняется фильтрация и частичная агрегация на стороне источника. Это позволяет обрабатывать большие файлы напрямую, снижая нагрузку на базу и сокращая время выполнения запросов.
Можно ли использовать PolyBase для интеграции данных из нескольких источников одновременно?
Да, через PolyBase можно объединять данные из нескольких внешних источников в одном запросе. Для этого создаются соответствующие External Data Source и External Table для каждого источника. После настройки можно выполнять JOIN, UNION и агрегации между таблицами, как если бы они находились в одной базе данных.