Содержание статьи

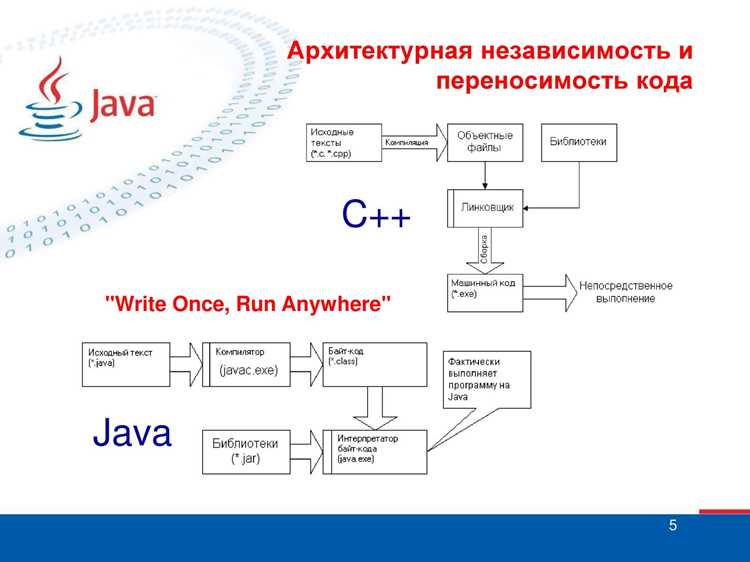
Java-программы не запускаются напрямую как исполняемые файлы. Сначала исходный код (.java) проходит компиляцию с помощью javac, превращаясь в байт-код (.class), который понимает Java Virtual Machine (JVM). Байткод сохраняет платформонезависимый формат инструкций, позволяя запускать программу на любой системе с установленной JVM.
JVM загружает классы в память через ClassLoader, проверяет байт-код на корректность и управляет распределением памяти. Этот процесс включает создание стека для потоков выполнения, кучи для объектов и постоянного пула для метаданных классов. Понимание работы загрузчика классов помогает контролировать порядок инициализации компонентов и избегать ошибок ClassNotFoundException.
После загрузки и проверки байт-кода JVM начинает интерпретацию или компиляцию в машинный код через Just-In-Time (JIT) компилятор. JIT анализирует часто выполняемые участки кода, превращая их в нативные инструкции для ускорения работы. Это объясняет, почему повторный запуск программы может работать быстрее.
Пошаговое выполнение программ Java включает обработку потоков, последовательное выполнение инструкций, вызов методов и управление исключениями. Использование инструментов мониторинга, таких как VisualVM или встроенные средства JVM, позволяет отслеживать нагрузку на память и время выполнения отдельных методов.
Компиляция исходного кода в байт-код
Процесс начинается с сохранения исходного кода в файлы с расширением .java. Компилятор javac анализирует синтаксис, проверяет типы данных и структуру классов, после чего преобразует код в байт-код .class. Каждому методу и выражению присваивается последовательность инструкций JVM, пригодная для платформонезависимого исполнения.
При компиляции рекомендуется включать флаги -g для генерации отладочной информации и -encoding UTF-8, чтобы избежать ошибок с символами в строковых литералах. Компилятор создает отдельный .class для каждого класса и внутреннего класса, что облегчает загрузку и оптимизацию JVM.
Ошибки компиляции фиксируются до запуска программы. Сообщения syntax error или cannot find symbol указывают на неправильное использование типов, методов или переменных. В сложных проектах рекомендуется использовать сборочные инструменты, такие как Maven или Gradle, для автоматической компиляции всех модулей с учетом зависимостей.
Роль JVM в интерпретации и запуске байт-кода

Java Virtual Machine (JVM) выполняет байт-код, создавая среду исполнения, независимую от операционной системы. Она интерпретирует инструкции .class или компилирует часто используемые участки в нативный код с помощью Just-In-Time (JIT) компилятора. Это позволяет программе работать быстрее и переносимо.
JVM управляет памятью, выделяя область для стека потоков, кучи объектов и постоянного пула классов. Каждый поток получает собственный стек для хранения локальных переменных и адресов возврата из методов, что снижает вероятность конфликтов при параллельном выполнении.
Для понимания распределения ресурсов и работы JVM полезно использовать следующие показатели:
| Компонент JVM | Назначение | Рекомендации |
|---|---|---|
| Heap (куча) | Хранение объектов и массивов | Мониторить использование с помощью VisualVM или jconsole, при необходимости настраивать -Xmx |
| Stack (стек потоков) | Локальные переменные и вызовы методов | Избегать чрезмерной рекурсии, при необходимости увеличивать -Xss |
| Method Area (постоянный пул) | Метаданные классов и статические данные | Следить за загрузкой большого числа классов при динамической генерации |
| JIT Compiler | Преобразование часто используемых методов в нативный код | Использовать профилирование, чтобы выявлять узкие места кода |
Загрузка классов и управление памятью
Загрузка классов в Java выполняет ClassLoader, который ищет байт-код в файловой системе, JAR-архивах или сети. Каждый класс загружается один раз и хранится в постоянной области памяти JVM. При повторных вызовах используется уже загруженный класс, что сокращает использование ресурсов.
Классы проходят три стадии: загрузка, проверка и инициализация. Проверка включает в себя контроль синтаксиса, проверку ссылок на другие классы и соблюдение правил безопасности. Инициализация выполняет статические блоки и устанавливает значения статических переменных.
Управление памятью включает кучу для объектов, стек потоков и постоянный пул классов. Для оптимизации работы рекомендуется:
— Настроить размер кучи через параметры -Xms и -Xmx в зависимости от объема создаваемых объектов.
— Использовать слабые ссылки или SoftReference для объектов, которые можно удалить при нехватке памяти.
— Контролировать загрузку классов, удаляя ненужные динамически сгенерированные классы с помощью ClassLoader, чтобы не перегружать постоянный пул.
Работа JIT-компилятора для ускорения выполнения

Just-In-Time (JIT) компилятор анализирует байт-код во время исполнения и преобразует часто вызываемые методы в нативный машинный код. Это сокращает количество интерпретируемых инструкций и ускоряет выполнение программы. JIT использует статистику выполнения для выбора «горячих» методов, которые требуют оптимизации.
JIT поддерживает несколько уровней компиляции: базовую интерпретацию, оптимизацию методом инлайнинга и агрессивное удаление неиспользуемого кода. Например, метод, вызываемый в цикле миллионы раз, компилируется в нативный код с прямыми переходами, что сокращает накладные расходы JVM.
Обработка потоков и выполнение инструкций

Каждый поток в Java имеет собственный стек, где хранятся локальные переменные, адреса возврата и результаты выполнения методов. Потоки выполняют инструкции JVM последовательно, управляя вызовами методов и обработкой исключений.
Основные аспекты управления потоками и инструкциями:
- Создание потока через Thread или ExecutorService.
- Синхронизация доступа к общим объектам с помощью synchronized или Lock для предотвращения конфликтов.
- Использование volatile для обеспечения видимости изменений переменных между потоками.
- Организация очередей задач для потоков, чтобы оптимизировать распределение нагрузки.
Пошаговое выполнение инструкции включает:
- Выбор следующей инструкции из байт-кода.
- Интерпретацию или запуск через JIT-компиляцию.
- Обновление стека и переменных потока.
- Обработку исключений, если они возникают.
Для мониторинга работы потоков рекомендуется использовать jconsole или VisualVM, чтобы отслеживать состояние блокировок, количество активных потоков и нагрузку на стек.
Отладка и мониторинг выполнения программы
Для анализа работы Java-программы используется встроенный отладчик JVM и внешние инструменты. jdb позволяет пошагово выполнять код, устанавливать точки останова и просматривать значения локальных переменных и аргументов методов.
Мониторинг состояния памяти и потоков выполняется через VisualVM, jconsole или встроенные утилиты JVM. Эти инструменты отображают:
- Использование кучи и стека потоков.
- Активные потоки и их состояния.
- Количество загруженных классов и метаданных.
- Статистику выполнения методов, включая время вызова.
Для выявления узких мест рекомендуется включать -Xprof или -XX:+PrintGCDetails, чтобы анализировать сборку мусора и нагрузку на JIT-компилятор. Совмещение отладки и мониторинга позволяет точно определить, какие участки кода требуют оптимизации или изменения структуры потоков.
Вопрос-ответ:
Что происходит после компиляции Java-кода в байт-код?
После компиляции исходный код Java превращается в байт-код, сохраняемый в файлах с расширением .class. Этот байт-код не зависит от операционной системы и готов к запуску на любой JVM. JVM загружает классы, проверяет их корректность и распределяет память для объектов и потоков, создавая среду для выполнения инструкций.
Как JVM управляет памятью при запуске программы?
JVM делит память на несколько областей: кучу для объектов, стек для потоков и постоянный пул для классов и статических данных. Куча используется для хранения всех создаваемых объектов, а стек каждого потока хранит локальные переменные и адреса возврата из методов. Постоянный пул классов содержит метаданные, которые нужны JVM для загрузки и инициализации классов. Правильная настройка размеров кучи и стека помогает избежать ошибок OutOfMemoryError.
Как работает JIT-компилятор и зачем он нужен?
JIT-компилятор анализирует байт-код во время выполнения и преобразует часто вызываемые методы в нативный машинный код. Это сокращает накладные расходы интерпретации и ускоряет выполнение программы. JIT отслеживает «горячие» участки кода, оптимизируя их с помощью инлайнинга и удаления неиспользуемых инструкций. Использование флагов -XX:+PrintCompilation и -XX:CompileThreshold помогает контролировать процесс компиляции.
Какие инструменты помогают отслеживать работу программы и потоков в JVM?
Для анализа работы программы и потоков применяются VisualVM, jconsole и jdb. С их помощью можно контролировать использование памяти, активные потоки, состояние блокировок, количество загруженных классов и время выполнения методов. Эти данные позволяют выявлять узкие места и корректировать структуру кода или потоков для улучшения производительности.