Содержание статьи

Хэш – это числовое или символьное значение, получаемое из исходных данных с помощью специальной функции. Оно позволяет быстро сравнивать, хранить и идентифицировать информацию без необходимости работать с полным набором исходных данных. Такой подход используется при построении баз данных, создании индексов и работе с криптографией.
Хэш-функция преобразует входные данные произвольной длины в фиксированный результат, называемый хэш-суммой. При этом даже небольшое изменение входных данных полностью меняет результат, что делает хэш удобным для проверки целостности файлов и защиты паролей. Например, алгоритмы SHA-256 и MD5 часто применяются для сравнения контрольных сумм при передаче данных.
В прикладных задачах хэш используется для ускорения поиска элементов в коллекциях, формирования уникальных идентификаторов и построения структур вроде хэш-таблиц. При правильном выборе алгоритма можно сократить время обработки больших массивов информации и минимизировать коллизии – ситуации, когда разные данные дают одинаковый хэш.
Практическое понимание принципов хэширования помогает разработчикам проектировать устойчивые и производительные системы. Владение этими инструментами важно при работе с сетевой безопасностью, распределёнными базами данных и системами контроля версий.
Хэш в программировании: понятие и применение

Хэш используется для представления данных в компактной форме, что позволяет ускорять операции поиска, проверки и сравнения. Он не хранит исходную информацию, а лишь отражает её в виде короткой последовательности символов, полученной через математическое преобразование. Такой подход снижает нагрузку на систему и упрощает обработку больших массивов данных.
Хэш-функции применяются при работе с коллекциями, базами данных и сетевыми протоколами. Например, при сохранении паролей система не хранит сам пароль, а записывает его хэш, что повышает уровень защиты. При сравнении вводимого пароля функция снова вычисляет хэш и сверяет его с уже сохранённым значением.
В хранилищах данных и кэшах хэширование используется для быстрого доступа к нужным элементам. Индексирование через хэш минимизирует количество обращений к памяти, что особенно важно при работе с миллионами записей. В таких случаях важно выбирать функцию, которая равномерно распределяет значения, избегая коллизий.
Хэширование применяется и в передаче данных: контрольные суммы позволяют проверять, не были ли изменены файлы при копировании или загрузке. Это делает процесс проверки целостности быстрым и надёжным. В криптографии хэши служат основой для цифровых подписей, токенов и блокчейнов, где требуется неизменность и достоверность данных.
Что такое хэш и как он формируется
Хэширование не подразумевает обратного преобразования, то есть восстановить исходные данные из хэша невозможно. Это свойство делает технологию удобной при хранении паролей, идентификаторов и других данных, которые должны оставаться конфиденциальными. При этом важно, чтобы функция имела равномерное распределение результатов, иначе возрастает риск коллизий – совпадений хэшей для разных входных значений.
Процесс формирования хэша можно описать поэтапно:
| Этап | Описание |
|---|---|
| 1. Подготовка данных | Исходные данные приводятся к двоичному виду и разбиваются на блоки фиксированной длины. |
| 2. Обработка блоков | Каждый блок проходит через последовательность логических и арифметических операций, зависящих от выбранного алгоритма. |
| 3. Сжатие результата | Итоговое значение объединяет результаты всех блоков, формируя хэш фиксированной длины. |
| 4. Проверка стабильности | При повторной обработке тех же данных хэш должен оставаться идентичным, что подтверждает корректность функции. |
Типичные алгоритмы формирования хэша включают MD5, SHA-1, SHA-256 и BLAKE3. При выборе алгоритма стоит учитывать баланс между скоростью вычисления и уровнем устойчивости к коллизиям. Для современных приложений предпочтительны алгоритмы семейства SHA-2 и SHA-3, обеспечивающие надёжность при минимальной нагрузке на процессор.
Основные свойства и особенности хэш-функций

Хэш-функции используются для преобразования данных произвольного размера в короткий фиксированный результат. Они работают по детерминированному принципу: одинаковый ввод всегда даёт одинаковый хэш, что обеспечивает предсказуемость и возможность проверки совпадений без хранения исходных данных.
Ключевое свойство – необратимость. Получить исходное значение из хэша невозможно, что делает такие функции удобными для хранения паролей и других конфиденциальных сведений. При этом важно, чтобы функция не позволяла находить разные входные данные с одинаковым результатом – это свойство называют устойчивостью к коллизиям.
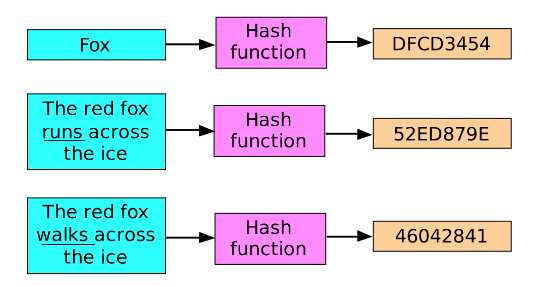
Ещё одно требование – лавинный эффект. Незначительное изменение входных данных должно приводить к полностью новому хэшу. Например, при изменении одного символа в строке хэш по алгоритму SHA-256 меняется более чем на 50% битов, что исключает предсказуемость результата.
Хэш-функции должны обладать равномерным распределением выходных значений, иначе часть диапазона может использоваться чаще, создавая нагрузку на систему и повышая риск коллизий. При анализе работы функции полезно тестировать распределение результатов на больших массивах случайных данных.
Для разных задач подбираются разные функции. Алгоритмы вроде SHA-2 и SHA-3 применяются в безопасности и криптографии, MurmurHash и xxHash – в системах хранения данных, где важна скорость вычислений. Выбор зависит от требований к устойчивости, скорости и объёму обрабатываемой информации.
Использование хэшей для хранения и поиска данных

Хэширование применяется для ускорения доступа к данным за счёт прямого вычисления позиции элемента. Вместо последовательного перебора используется хэш-функция, которая вычисляет индекс для хранения значения. Такой подход значительно сокращает время поиска в больших коллекциях, где операции выполняются за константное время.
В структурах данных хэш используется при работе с хэш-таблицами, словарами и ассоциативными массивами. Каждый элемент имеет ключ, который преобразуется в хэш. Если два ключа дают одинаковое значение, возникает коллизия, которая решается методами открытой адресации или цепочек. Для снижения вероятности коллизий рекомендуется выбирать функцию с равномерным распределением и таблицу достаточного размера.
Хэши применяются и в индексировании баз данных. При создании индекса хэш-функция преобразует значения столбцов, позволяя быстро сравнивать и находить записи без полного сканирования таблицы. Такой метод особенно полезен для полей с короткими строками и равномерным распределением данных.
В распределённых системах хэширование используется для балансировки нагрузки между узлами. Например, метод consistent hashing позволяет равномерно распределять ключи по серверам и минимизировать перестановки данных при изменении числа узлов. Это повышает устойчивость системы при масштабировании.
При проектировании хранилищ рекомендуется использовать проверенные алгоритмы, такие как MurmurHash3 или CityHash, которые обеспечивают быстрое вычисление и равномерное распределение. При работе с конфиденциальными данными предпочтительно применять криптографические хэши – SHA-256 или BLAKE2.
Применение хэширования в безопасности и проверке целостности

Хэширование используется в системах безопасности для защиты данных от несанкционированного доступа и подмены. Основная идея заключается в том, что система хранит не исходные значения, а их хэши. При проверке данных хэш вычисляется заново и сравнивается с сохранённым значением. Совпадение подтверждает подлинность информации без необходимости раскрывать оригинал.
В управлении паролями применяются алгоритмы bcrypt, scrypt и Argon2. Они дополнительно используют «соль» – случайную строку, добавляемую к паролю перед хэшированием. Это защищает от атак с использованием заранее вычисленных таблиц (rainbow tables) и усложняет подбор значений.
Проверка целостности файлов основана на сравнении контрольных сумм. Например, при скачивании программного обеспечения можно сверить хэш, опубликованный на сайте разработчика, с вычисленным локально. Несовпадение указывает на изменение содержимого или вмешательство третьих лиц.
В криптографии хэши применяются для формирования цифровых подписей и токенов. Подпись создаётся на основе хэша сообщения и закрытого ключа отправителя. Получатель, используя открытый ключ, может убедиться в подлинности и неизменности данных, не имея доступа к исходной информации.
Хэширование также используется в блокчейне для связывания блоков и проверки истории транзакций. Каждый блок содержит хэш предыдущего, что делает изменение данных без следа невозможным. Это свойство обеспечивает прозрачность и доверие к распределённым системам хранения данных.
Хэш-таблицы и их роль в структуре данных
Хэш-таблица – структура данных, которая обеспечивает быстрый доступ к элементам по ключу. Она использует хэш-функцию для преобразования ключа в индекс массива, где хранится соответствующее значение. Такой подход позволяет выполнять операции поиска, вставки и удаления за константное время в среднем.
Основные компоненты хэш-таблицы:
- Ключ – уникальный идентификатор элемента.
- Значение – данные, ассоциированные с ключом.
- Хэш-функция – алгоритм преобразования ключа в индекс.
- Массив ячеек – структура хранения значений по индексам.
Методы обработки коллизий:
- Метод цепочек – элементы с одинаковым индексом сохраняются в связном списке.
- Открытая адресация – поиск следующей свободной ячейки по определённой последовательности.
При проектировании хэш-таблицы важно учитывать:
- Размер массива: слишком маленький увеличивает коллизии, слишком большой расходует память.
- Выбор хэш-функции: равномерное распределение ключей снижает количество коллизий.
- Реорганизация таблицы: при росте числа элементов выполняется увеличение массива и перераспределение элементов.
Хэш-таблицы применяются в словарях, кэшах, индексах баз данных и распределённых системах. Они позволяют минимизировать задержки при доступе к данным и оптимизировать использование ресурсов при больших объёмах информации.
Популярные алгоритмы хэширования и их отличия
MD5 – классический алгоритм, формирующий 128-битный хэш. Быстро вычисляется, но устарел в безопасности из-за высокой вероятности коллизий, поэтому не рекомендуется для защиты конфиденциальных данных.
SHA-1 генерирует 160-битный хэш. Использовался в цифровых подписях и сертификатах, но уязвим к коллизиям при современных атаках. Подходит только для проверки целостности в некритичных системах.
SHA-2 включает семейство алгоритмов с длиной хэша 224, 256, 384 и 512 бит. Обеспечивает высокий уровень защиты, широко применяется в криптографии, цифровых подписьях и хранении паролей.
SHA-3 построен на другой структуре (Keccak) и используется там, где важна устойчивость к новым типам атак. Отличается от SHA-2 внутренней обработкой блоков и меньшей предсказуемостью хэша при определённых паттернах данных.
BLAKE2 и BLAKE3 обеспечивают высокую скорость вычисления и надёжность. BLAKE3 особенно эффективен при многопоточном вычислении и больших объёмах данных, поддерживает слияние и последовательную проверку блоков.
Выбор алгоритма зависит от задачи:
- Для контроля целостности файлов и быстрых проверок подходят MD5 и SHA-1, но не для защиты паролей.
- Для хранения паролей и криптографических операций предпочтительны SHA-2, SHA-3 и BLAKE2/3.
- Для распределённых систем и кэшей важна скорость вычисления и равномерность распределения – здесь используют BLAKE3 и xxHash.
Вопрос-ответ:
Что такое хэш в программировании и зачем он нужен?
Хэш — это короткое фиксированное значение, получаемое из исходных данных с помощью хэш-функции. Он используется для быстрого сравнения, поиска и идентификации информации без необходимости работать с полным набором данных. Например, хэш позволяет ускорять поиск в больших коллекциях, проверять целостность файлов и защищать пароли.
В чем разница между MD5, SHA-1 и SHA-256?
MD5 создаёт 128-битный хэш, вычисляется быстро, но имеет высокую вероятность коллизий. SHA-1 генерирует 160-битный хэш и тоже уязвим к коллизиям, поэтому подходит только для некритичных задач. SHA-256 формирует 256-битный хэш и обеспечивает более надёжную защиту данных, широко применяется в криптографии и цифровых подписях.
Как хэширование помогает хранить и проверять пароли?
При хранении паролей система сохраняет не сам пароль, а его хэш. При вводе пароля вычисляется хэш введённого значения и сравнивается с сохранённым. Если они совпадают, доступ разрешён. Использование «соли» — случайной строки, добавляемой к паролю перед хэшированием — делает атаки с заранее вычисленными таблицами сложнее.
Что такое хэш-таблица и как она ускоряет поиск данных?
Хэш-таблица хранит элементы в виде пар «ключ-значение». Ключ преобразуется в индекс с помощью хэш-функции, что позволяет напрямую обращаться к нужной ячейке. Этот метод уменьшает количество операций поиска и делает доступ к данным практически мгновенным при больших объёмах информации.
Как хэш используется для проверки целостности файлов?
Для проверки целостности вычисляется хэш файла и сравнивается с контрольной суммой, опубликованной разработчиком или сохранённой ранее. Если значения совпадают, файл не изменялся; если отличаются, это указывает на повреждение или вмешательство. Этот метод применяют при скачивании программ, обновлений и передачи данных по сети.