Содержание статьи

Обход данных – это процесс последовательного посещения всех элементов структуры данных с целью анализа, изменения или извлечения информации. Чаще всего обход применяется к массивам, спискам, деревьям и графам, где необходимо получить полный доступ ко всем элементам или выявить определённые закономерности.
При работе с массивами и списками обычно используют циклы for или while, позволяющие проходить элементы последовательно или с шагом. Для связанных списков предпочтительна итерация по указателям на следующий элемент, что уменьшает риск пропуска данных и повышает контроль над процессом.
Деревья и графы требуют особых методов обхода. Рекурсивный обход дерева позволяет выполнять операции на каждом узле до или после посещения дочерних элементов, тогда как итеративный обход графа с помощью стека или очереди помогает находить кратчайшие пути и предотвращает повторное посещение узлов.
В реальных проектах обход файловых систем применяется для поиска файлов по заданным критериям, а обход результатов запросов к базе данных – для фильтрации и агрегации информации. Выбор метода обхода зависит от структуры данных, объёма информации и требуемой логики обработки.
Неправильная организация обхода может приводить к пропуску элементов, бесконечным циклам или перегрузке памяти. Рекомендуется заранее оценивать глубину рекурсии, размер коллекции и использовать проверку уже посещённых элементов, особенно при работе с графами и сложными деревьями.
Что такое обход и где применяется в коде
Обход в программировании представляет собой алгоритм последовательного посещения элементов структуры данных для выполнения операций над ними. Каждый элемент посещается один или несколько раз в зависимости от логики задачи, что позволяет собирать информацию, модифицировать данные или проверять условия.
В массивах и списках обход используется для подсчёта элементов, поиска значений или фильтрации данных. Циклы for и while обеспечивают контроль позиции и позволяют изменять элементы на месте. Для связанных списков обход реализуется через ссылки на следующий элемент, что уменьшает потребление памяти при больших коллекциях.
В деревьях и графах обход необходим для навигации и анализа структуры. Рекурсивный подход подходит для обхода всех веток дерева, а итеративный с использованием стека или очереди обеспечивает работу с графами без риска переполнения стека и позволяет отслеживать посещённые узлы.
Обход применяется при работе с файловыми системами для поиска или сортировки файлов по атрибутам, а также при обработке результатов баз данных для агрегации и фильтрации записей. Выбор метода зависит от структуры данных, объёма и целей обработки, поэтому планирование обхода до реализации снижает вероятность ошибок и повышает читаемость кода.
Обход массивов: линейный и циклический подход
Обход массивов позволяет работать с каждым элементом для поиска, сортировки или модификации данных. Существует два основных подхода: линейный и циклический, выбор которых зависит от задачи.
Линейный обход выполняется один раз по всем элементам массива:
- Используется стандартный цикл for с индексом от 0 до длины массива минус один.
- Подходит для подсчёта значений, суммирования элементов и поиска конкретного значения.
- Прост в реализации и не требует дополнительной памяти.
Циклический обход применяется, когда необходимо многократное или периодическое прохождение массива:
- Используется модульная арифметика для возврата к первому элементу после последнего.
- Применим для задач с кольцевыми буферами или циклическими событиями.
- Позволяет непрерывно обновлять данные без создания новых массивов.
Рекомендации:
- Для больших массивов выбирайте линейный обход, чтобы снизить нагрузку на процессор.
- Для повторяющихся операций или анимаций используйте циклический подход.
- Следите за индексами и границами массива, чтобы избежать ошибок выхода за пределы.
Обход списков и связанных структур данных
Списки и связанные структуры данных требуют обхода с учётом их внутренней организации. В отличие от массивов, доступ к элементам происходит через указатели или ссылки на следующий элемент, что влияет на выбор алгоритма обхода.
Односвязные списки обходятся последовательно от головы к концу, используя указатель на следующий элемент. Для поиска или изменения значения текущего узла достаточно пройти по всем элементам один раз. Важно проверять, что указатель не равен null, чтобы избежать ошибок доступа.
Двусвязные списки позволяют перемещаться в обе стороны. Это упрощает задачи вставки и удаления элементов, а также обход с конца к началу. При двустороннем обходе следует отслеживать корректность связей prev и next, чтобы избежать разрыва списка.
Кольцевые и комбинированные структуры используют специальные условия для завершения обхода. Например, обход кольцевого списка должен учитывать возврат к началу, чтобы не войти в бесконечный цикл. Рекомендуется использовать счётчик элементов или маркеры посещённых узлов для контроля завершения.
При работе с любыми связанными структурами важно планировать обход в зависимости от задач: фильтрация, агрегация или изменение данных. Выбор метода обхода влияет на скорость выполнения и потребление памяти, особенно при больших списках.
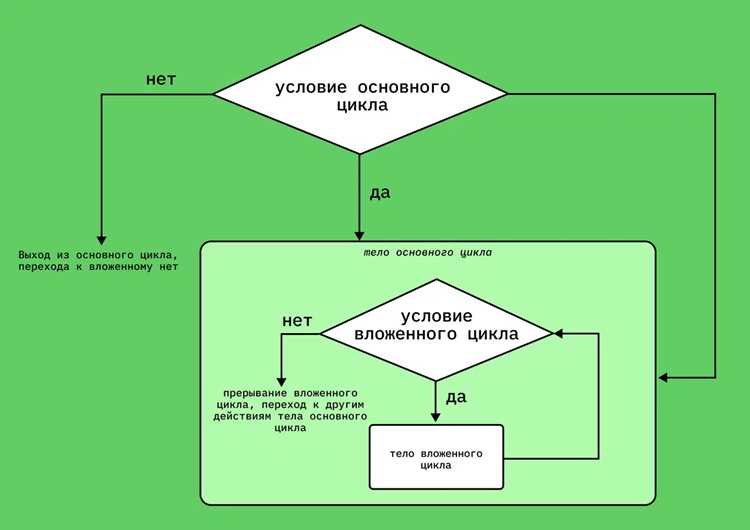
Рекурсивный обход деревьев и графов
Рекурсивный обход используется для последовательного посещения всех узлов деревьев и графов. В деревьях часто применяются обходы в глубину: preorder, inorder и postorder, которые позволяют выполнять операции до посещения дочерних элементов, между ними или после.
В графах рекурсивный обход помогает пройти по всем смежным узлам, сохраняя список уже посещённых вершин, чтобы избежать циклов и повторного посещения. Без отслеживания посещённых узлов рекурсивный обход может войти в бесконечный цикл.
Рекурсия позволяет легко реализовать сложные алгоритмы поиска, такие как нахождение путей, подсчёт количества узлов или суммирование значений в поддеревьях. Необходимо учитывать глубину рекурсии и размер стека вызовов, особенно при больших графах или глубоких деревьях.
Для оптимизации рекурсивного обхода рекомендуется:
- Использовать структуру данных для отслеживания посещённых узлов.
- При больших глубинах заменять рекурсию на итеративный подход с явным стеком.
- Применять хвостовую рекурсию, если язык программирования её поддерживает, для уменьшения нагрузки на стек.
Итеративный обход графов с использованием стека и очереди
Итеративный обход графов применяется для обхода всех вершин без использования рекурсии. Стек используется для обхода в глубину (DFS), а очередь – для обхода в ширину (BFS), что позволяет контролировать порядок посещения узлов и снижает риск переполнения стека вызовов.
В DFS вершины добавляются в стек по мере обнаружения смежных узлов. После извлечения вершины из стека проверяется, была ли она посещена ранее, чтобы избежать циклов. Этот подход подходит для поиска пути, топологической сортировки и анализа компонент связности.
BFS использует очередь, в которую помещаются все смежные непосещённые вершины текущей вершины. Такой подход гарантирует посещение всех вершин на одном уровне перед переходом на следующий, что удобно для поиска кратчайшего пути в невзвешенных графах и анализа соседних связей.
Рекомендации при итеративном обходе:
- Использовать массив или множество для отметки посещённых вершин.
- Для больших графов контролировать размер стека и очереди, чтобы избежать переполнения памяти.
- Выбирать DFS для задач с глубокими зависимостями и BFS для поиска минимальных расстояний между узлами.
Обход файловой системы и работа с каталогами
Обход файловой системы применяется для поиска, сортировки и обработки файлов в каталогах. Для этого используют рекурсивный и итеративный методы обхода, которые обеспечивают доступ ко всем подкаталогам и файлам.
Рекурсивный обход проходит по каждому каталогу, вызывая функцию для всех вложенных директорий:
- Применяется для подсчёта файлов, копирования и удаления структур.
- Позволяет фильтровать файлы по расширению или атрибутам.
- Необходимо отслеживать глубину рекурсии, чтобы избежать переполнения стека при больших деревьях каталогов.
Итеративный обход с использованием стека или очереди позволяет обходить каталоги без рекурсии:
- Каталоги помещаются в стек/очередь, затем последовательно извлекаются для обработки.
- Подходит для обработки больших файловых систем с ограничением памяти.
- Обеспечивает контроль порядка посещения каталогов и предотвращает повторное посещение.
Рекомендации при обходе файловой системы:
- Использовать фильтры для работы только с нужными файлами и каталогами.
- При обработке больших объёмов данных использовать итеративный метод для снижения нагрузки на память.
- Обрабатывать ошибки доступа к файлам и каталогам, чтобы избежать прерывания программы.
Обход структур баз данных и результатов запросов

Обход структур баз данных необходим для анализа, фильтрации и агрегации данных после выполнения запросов. Чаще всего результаты обходятся по строкам таблицы или по объектам ORM, что позволяет применять вычисления и преобразования на лету.
Для обхода результатов SQL-запросов используют последовательное чтение каждой строки:
| Метод | Описание | Применение |
|---|---|---|
| Цикл по строкам | Последовательное извлечение каждой записи | Фильтрация, подсчёт, преобразование данных |
| Курсоры | Управляемый обход строк с возможностью изменения данных | Обновление и удаление отдельных записей без загрузки всей таблицы |
| ORM-итераторы | Обход объектов, соответствующих строкам таблицы | Работа с объектами в приложении, интеграция с логикой кода |
Рекомендации при обходе баз данных:
- Использовать фильтры в запросе для уменьшения объёма данных на этапе обхода.
- При больших таблицах применять пакетную обработку или курсоры, чтобы снизить нагрузку на память.
- Отслеживать состояние транзакций при изменении данных, чтобы обеспечить целостность базы.
Ошибки при обходе и методы их предотвращения

При обходе структур данных часто возникают ошибки, связанные с некорректным доступом к элементам или повторным посещением узлов. Типичные ошибки включают выход за пределы массива, бесконечные циклы в графах и нарушение ссылочной целостности связанных структур.
В массивах ошибки возникают при неправильной инициализации индексов или шагов цикла. Рекомендуется проверять диапазон индексов и использовать стандартные функции для итерации, чтобы избежать выхода за границы.
В списках и связанных структурах возможны разрывы ссылок и потеря узлов. Для предотвращения ошибок необходимо:
- Отслеживать корректность указателей prev и next при двусвязных списках.
- Использовать маркеры посещённых узлов для кольцевых и комбинированных списков.
В графах бесконечные циклы предотвращаются с помощью множества или массива для отметки уже посещённых вершин. Без такой проверки рекурсивный и итеративный обход может зациклиться на циклических соединениях.
При обходе файловых систем и баз данных ошибки часто связаны с отсутствием доступа к элементам. Следует обрабатывать исключения и проверять права доступа, чтобы программа не прерывалась на первой недоступной записи.
Общие рекомендации:
- Тестировать обход на небольших выборках перед применением к большим структурам.
- Использовать встроенные средства языка для безопасного обхода.
- Документировать логику обхода и условия завершения, чтобы избежать скрытых ошибок.
Вопрос-ответ:
Что такое обход в программировании и зачем он нужен?
Обход — это процесс последовательного посещения элементов структуры данных, таких как массивы, списки, деревья и графы, для анализа, изменения или извлечения информации. Он позволяет выполнять поиск, подсчёт значений, фильтрацию данных и другие операции, которые требуют обработки каждого элемента.
В чём разница между линейным и циклическим обходом массивов?
Линейный обход проходит по массиву один раз от первого до последнего элемента и используется для подсчёта, фильтрации или поиска значений. Циклический обход возвращается к началу после последнего элемента, что удобно для работы с кольцевыми буферами, повторяющимися процессами или непрерывной обработкой данных.
Как правильно обходить двусвязные списки, чтобы не потерять данные?
При обходе двусвязного списка нужно последовательно переходить по указателям next и prev. Для изменения или удаления узлов важно корректно обновлять связи между соседними элементами, чтобы структура списка не нарушилась. Использование маркеров посещённых узлов помогает избежать повторного обхода и ошибок.
Когда стоит использовать рекурсивный обход деревьев и графов?
Рекурсивный обход удобен, когда необходимо обрабатывать все ветви дерева или графа, выполняя действия до или после посещения дочерних элементов. Он подходит для поиска путей, подсчёта узлов, суммирования значений. При больших структурах нужно контролировать глубину рекурсии, чтобы избежать переполнения стека вызовов.
Какие ошибки чаще всего возникают при обходе и как их избежать?
Частые ошибки включают выход за пределы массива, бесконечные циклы в графах, разрывы ссылок в списках и ошибки доступа к файлам или записям базы данных. Для их предотвращения используют проверку границ, маркеры посещённых узлов, обработку исключений и отслеживание целостности ссылок и транзакций.
Как выбрать подходящий метод обхода для конкретной структуры данных?
Выбор метода обхода зависит от типа структуры данных и задачи, которую нужно решить. Для массивов и списков подходят линейные или циклические циклы, которые позволяют последовательно обрабатывать элементы. В деревьях и графах часто применяются рекурсивные обходы для работы с ветвями или итеративные методы с использованием стека и очереди для контроля порядка посещения и предотвращения бесконечных циклов. При работе с файлами и каталогами рекурсивный подход удобен для вложенных директорий, а итеративный с очередью или стеком — для больших систем с ограничением памяти. Планирование обхода заранее помогает снизить ошибки и ускоряет обработку данных.