Содержание статьи

Парсер – это программный компонент, который анализирует текстовые данные и преобразует их в структуру, удобную для обработки. В программировании парсеры часто применяются для разбора HTML, JSON, XML, CSV и логов. Основная задача парсера – идентифицировать ключевые элементы и их взаимосвязи, чтобы дальнейшие алгоритмы могли работать с информацией корректно.
Процесс работы парсера обычно делится на два этапа: лексический и синтаксический анализ. На лексическом этапе текст разбивается на токены – минимальные значимые единицы, например слова, числа или символы. На синтаксическом этапе эти токены объединяются в дерево или граф, отражающий структуру данных. Такая организация позволяет выявлять ошибки формата и применять трансформации к отдельным элементам.
Выбор типа парсера зависит от задач. Простые регулярные выражения подходят для извлечения конкретных значений из текстовых файлов, но для сложных структур используют генераторы парсеров, такие как ANTLR или PLY. Рекомендуется заранее определить грамматику данных, чтобы парсер корректно обрабатывал исключения и обеспечивал стабильную работу приложения.
При разработке парсера важно учитывать производительность и устойчивость к ошибкам. Для больших объемов данных применяют потоковый анализ, который позволяет обрабатывать информацию по частям без загрузки всего файла в память. Также стоит реализовать логирование и тесты на корректность обработки нестандартных случаев, чтобы снизить риск сбоев при парсинге реальных данных.
Как парсер извлекает данные из HTML и JSON

Парсер для HTML использует структуру документа в виде дерева элементов DOM. Каждый тег, атрибут и текстовая нода становятся узлами дерева. Для извлечения информации применяют методы поиска по тегам, классам или идентификаторам. Например, в Python библиотека BeautifulSoup позволяет использовать методы find(), find_all() и CSS-селекторы через select(). При этом важно учитывать вложенность элементов, чтобы не захватывать лишние узлы.
При работе с JSON данные представляют собой объектно-ключевую структуру. Парсер разбирает текст JSON в словари и списки, которые можно обрабатывать стандартными методами языка программирования. В Python для этого используется библиотека json с функциями json.loads() и json.load(). Важно проверять наличие ключей перед доступом к значениям, чтобы избежать ошибок.
Для систематизации извлечённых данных удобно использовать таблицы. Ниже представлен пример формата, который можно применять после парсинга HTML или JSON:
| Источник | Элемент/Ключ | Значение |
|---|---|---|
| HTML | <div class=»price»> | 1500 руб. |
| HTML | <h1 id=»title»> | Название товара |
| JSON | product.name | Название товара |
| JSON | product.price | 1500 |
Рекомендуется использовать фильтры для извлечения только необходимых узлов или ключей. В HTML это XPath или CSS-селекторы, в JSON – проверка наличия ключей и вложенных объектов. Такой подход минимизирует ошибки и ускоряет обработку данных.
При регулярном обновлении источников стоит строить парсеры с учётом возможных изменений структуры HTML или JSON. Для HTML это проверка классов и тегов, для JSON – наличие новых или удалённых ключей. Это повышает надёжность сбора данных.
Разбор текстовых файлов с помощью регулярных выражений

Регулярные выражения позволяют извлекать структурированные данные из текстовых файлов без необходимости ручной обработки строк. Они представляют собой шаблоны поиска, которые сопоставляются с текстом по заданным правилам.
Основные шаги работы с текстовыми файлами через регулярные выражения:
- Открытие файла и чтение содержимого в память. Для больших файлов рекомендуется построчная обработка.
- Определение шаблона регулярного выражения с учетом нужных элементов, например:
- Электронные адреса:
[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,} - Номера телефонов:
\+?\d{1,3}[-.\s]?\(?\d{1,4}\)?[-.\s]?\d{1,4}[-.\s]?\d{1,9} - Даты в формате ДД-ММ-ГГГГ:
\b\d{2}-\d{2}-\d{4}\b - Использование функций поиска и извлечения:
re.search()– проверка наличия шаблона в строке.re.findall()– получение всех совпадений в файле.re.sub()– замена найденных шаблонов на другой текст.- Обработка совпадений для дальнейшего анализа, например, сохранение в массивы или запись в CSV.
Практические рекомендации:
- Сначала тестируйте регулярное выражение на небольших фрагментах текста.
- Используйте необязательные группы
(...)?и классы символов[ ]для гибкости шаблонов. - Для больших файлов избегайте одновременной загрузки всего текста в память, применяйте итеративную обработку построчно.
- Документируйте сложные шаблоны с пояснениями, чтобы облегчить поддержку.
Регулярные выражения позволяют быстро фильтровать, проверять и извлекать данные из текстовых файлов, превращая неструктурированный текст в пригодный для анализа формат.
Использование библиотек для парсинга в Python и JavaScript
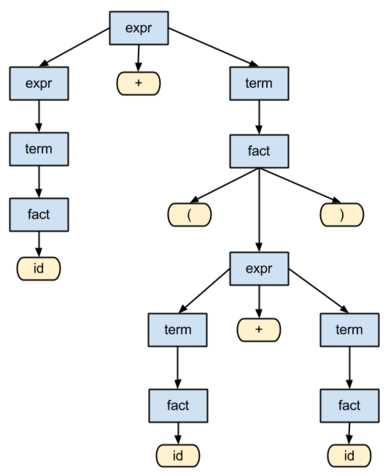
В Python для парсинга HTML чаще всего применяются библиотеки BeautifulSoup и lxml. BeautifulSoup предоставляет простой интерфейс для поиска элементов по тегам, классам и атрибутам, а lxml ускоряет обработку больших документов благодаря движку на C. Для работы с веб-страницами, где требуется эмуляция браузера, используют библиотеку Selenium или Playwright. Requests и aiohttp применяются для получения HTML-кода страниц синхронно и асинхронно соответственно.
В JavaScript популярны Cheerio и Puppeteer. Cheerio позволяет выполнять выборку элементов через селекторы jQuery-подобного синтаксиса и подходит для обработки статического HTML. Puppeteer управляет полнофункциональным браузером Chromium, что дает возможность парсить динамический контент, генерируемый JavaScript. Для запросов к API и получения HTML используют fetch и Axios.
При выборе библиотеки важно учитывать объем данных и способ их генерации. Для статического HTML в Python достаточно BeautifulSoup или lxml, в JavaScript – Cheerio. Для динамически создаваемого контента применяют Selenium, Playwright или Puppeteer. Комбинация HTTP-запросов и парсинга DOM через эти библиотеки позволяет создавать точные и стабильные скрипты извлечения данных.
Оптимизация парсинга включает использование асинхронных запросов, минимизацию количества загрузок страницы и работу с ограниченным набором селекторов. В Python aiohttp совместно с lxml или BeautifulSoup обеспечивает высокую скорость, в JavaScript асинхронные функции с fetch или Puppeteer позволяют контролировать последовательность загрузки элементов и уменьшить нагрузку на сервер.
При парсинге рекомендуется заранее анализировать структуру HTML, определять ключевые селекторы и проверять страницы на наличие антибот-механизмов. Логирование ошибок и сохранение промежуточных данных помогают предотвратить потерю информации при сбоях. Использование специализированных библиотек сокращает время разработки и повышает точность извлечения контента.
Обработка ошибок и некорректных данных при парсинге

Следующий элемент – отлов исключений. В языках вроде Python или JavaScript рекомендуется оборачивать критические участки кода в блоки try-catch (или try-except), чтобы программа не прерывалась при первой встреченной ошибке. Исключения нужно логировать с указанием позиции в исходном файле и типа нарушения, что облегчает исправление источника данных.
Некорректные элементы лучше не игнорировать полностью, а применять стратегии восстановления. Для текстовых данных допустимо удаление неподходящих символов или замена их на безопасные аналоги. Для структурированных форматов допустимо заполнение отсутствующих полей дефолтными значениями или пропуск только повреждённых записей.
При парсинге больших объёмов данных эффективна реализация контрольных точек. Сохранять состояние после обработки каждой партии элементов позволяет возобновить работу без повторной загрузки всего файла при критической ошибке.
Важно использовать тестовые наборы с намеренно некорректными данными. Это помогает выявить слабые места парсера и убедиться, что обработка ошибок работает как предусмотрено, не вызывая утечек памяти или зависаний.
Наконец, автоматическое уведомление о критических ошибках повышает прозрачность работы парсера. Логи, отчёты или алерты позволяют оперативно реагировать на сбои и корректировать источник данных без остановки основной системы.
Сравнение парсинга API и веб-страниц

Парсинг API работает с структурированными данными, чаще всего в формате JSON или XML. Запросы отправляются на конечные точки сервера, и в ответ приходит строго организованная информация. Это снижает вероятность ошибок при извлечении данных и ускоряет процесс, так как не требуется анализ HTML-структуры страницы.
Преимущества API-парсинга: высокая точность данных, поддержка обновлений со стороны сервиса, возможность фильтрации и пагинации на уровне запроса. Например, для получения последних котировок акций через API брокера можно запросить только нужные символы и диапазоны дат, без лишней информации.
Парсинг веб-страниц опирается на анализ HTML-документа, извлекая данные из тегов, классов или идентификаторов. Этот метод применим, когда API отсутствует или ограничен. Однако изменения разметки страницы могут нарушить работу парсера, что требует регулярного обновления кода.
Особенности веб-парсинга: возможность получать любые видимые данные, включая текст, ссылки и изображения, но с повышенной нагрузкой на обработку HTML и повышенным риском блокировки со стороны сайта. Для уменьшения риска часто используют задержки между запросами и ротацию прокси.
При выборе метода важно учитывать стабильность источника, объем данных и требования к точности. Если сервис предоставляет API, предпочтительнее использовать его. Если API отсутствует, веб-парсинг остается единственным вариантом, но требует дополнительных механизмов контроля ошибок и изменений разметки.
Автоматизация сбора информации с помощью скриптов-парсеров

Автоматизация сбора информации с помощью парсеров включает в себя использование скриптов для извлечения данных с веб-страниц, API и локальных файлов. Это существенно ускоряет обработку информации, особенно при работе с большими объемами данных. Для парсинга HTML-страниц наиболее часто используют библиотеки, такие как BeautifulSoup и lxml для Python, которые позволяют легко извлекать и обрабатывать нужные элементы по тегам, классам или аттрибутам.
Для взаимодействия с веб-сайтами, чаще всего применяется библиотека requests, которая позволяет отправлять HTTP-запросы и получать HTML-контент страниц. В случае, когда сайт использует динамическую загрузку данных через JavaScript, используется Selenium или Playwright, которые позволяют взаимодействовать с браузером и извлекать информацию после её загрузки.
После получения HTML-контента, парсер анализирует структуру страницы и извлекает информацию с помощью CSS-селекторов или XPath-выражений. Для сохранения собранных данных используют форматы, такие как JSON, CSV или базы данных (например, SQLite или PostgreSQL), что позволяет удобно хранить и обрабатывать информацию в дальнейшем.
Одним из важных аспектов при разработке скриптов-парсеров является соблюдение правил веб-сайтов, указанных в robots.txt. Он регулирует, какие страницы и данные могут быть собраны. Также стоит учитывать частотные ограничения запросов, чтобы избежать блокировки со стороны серверов. Эффективность парсинга можно повысить за счет многопоточности, ограничивая количество одновременных запросов и устанавливая интервалы между ними.
Для повышения стабильности работы парсера важно обрабатывать ошибки сети, выполнять повторные попытки в случае сбоя соединения и логировать процесс. Это позволит быстрее выявлять и устранять проблемы. Также полезно автоматизировать регулярный сбор данных, создавая задачи в планировщиках, таких как cron на Linux или Task Scheduler на Windows.
Вопрос-ответ:
Что такое парсер в программировании?
Парсер — это программа или часть программы, которая анализирует текстовую информацию, преобразуя её в структуру, которую можно обработать машинно. В программировании парсер часто используется для работы с исходным кодом, чтобы разбить его на элементы (лексемы), которые проще интерпретировать или трансформировать в более удобный формат.
Как работает парсер?
Парсер разбивает входной текст на составляющие, такие как слова, символы или блоки кода. Затем с помощью заранее заданных правил он формирует из этих частей более сложную структуру данных, которая уже может быть использована в дальнейшей обработке. Например, парсер для обработки HTML или XML преобразует текст в дерево элементов, где каждый элемент имеет свои атрибуты и содержание.
Какие типы парсеров бывают?
Существует несколько типов парсеров. Один из самых распространенных — это лексический парсер, который занимается разбором на уровне отдельных символов и слов. Синтаксический парсер работает с более сложными структурами, например, с предложениями или блоками кода, чтобы проверить их правильность по заданной грамматике. Также существуют комбинированные парсеры, которые выполняют как лексический, так и синтаксический разбор.
Для чего нужны парсеры в программировании?
Парсеры широко используются в программировании для анализа и обработки текстовых данных. Они необходимы для создания компиляторов, которые разбирают исходный код и превращают его в исполнимую программу. Парсеры также используются в системах обработки данных, таких как веб-скрейпинг, для извлечения информации с сайтов. Еще один пример — парсеры для обработки команд пользователя в интерфейсах или чат-ботах.
Какие проблемы могут возникнуть при работе с парсером?
Основная проблема при работе с парсерами — это сложность написания правильных правил для разбора данных. Если парсер неправильно обрабатывает входные данные, это может привести к ошибкам в программе или неправильному результату. Также парсеры могут столкнуться с проблемами при обработке нестандартных или испорченных данных, что требует дополнительных механизмов для их корректной обработки или игнорирования ошибок.
Что такое парсер и зачем он нужен в программировании?
Парсер — это программа или алгоритм, который анализирует текст, данные или код и преобразует их в структуру, удобную для дальнейшей обработки. В программировании парсер используется для того, чтобы понять синтаксис и структуру входных данных, будь то текстовый файл, код на языке программирования или даже запросы к базе данных. Например, парсер может анализировать HTML-код веб-страницы и извлекать из него нужную информацию, такую как ссылки, изображения или текст.
Как работает парсер на практике? Можешь привести пример?
Парсер работает по принципу последовательного анализа входных данных. Сначала он разбивает текст или код на части — токены, затем проверяет их соответствие синтаксическим правилам. Если все правильно, он строит из этих частей дерево, которое можно использовать для дальнейшей работы. Пример: если парсер анализирует HTML, он разобьет код на теги и атрибуты, а затем представит это как дерево, где каждый узел — это отдельный элемент HTML-страницы. Например, парсер может «увидеть» тег и разобрать его как ссылку, извлекая URL из атрибута href.