Содержание статьи

Микросервисная архитектура разделяет приложение на отдельные модули, каждый из которых выполняет конкретную функцию и может развиваться независимо. Такой подход упрощает масштабирование, позволяет внедрять новые технологии для отдельных компонентов и ускоряет обновления без остановки всего сервиса.
Для взаимодействия микросервисов обычно используют REST API или gRPC, что обеспечивает четкое разделение ответственности и упрощает интеграцию. При проектировании важно определить границы сервисов по бизнес-логике и минимизировать их зависимость друг от друга, чтобы изменения одного компонента не нарушали работу остальных.
Выбор технологий для каждого микросервиса зависит от задач: базы данных могут отличаться по типу – SQL для транзакционных сервисов, NoSQL для аналитических и кэширования. Также стоит предусмотреть централизованное логирование и мониторинг, чтобы быстро выявлять сбои и узкие места в системе.
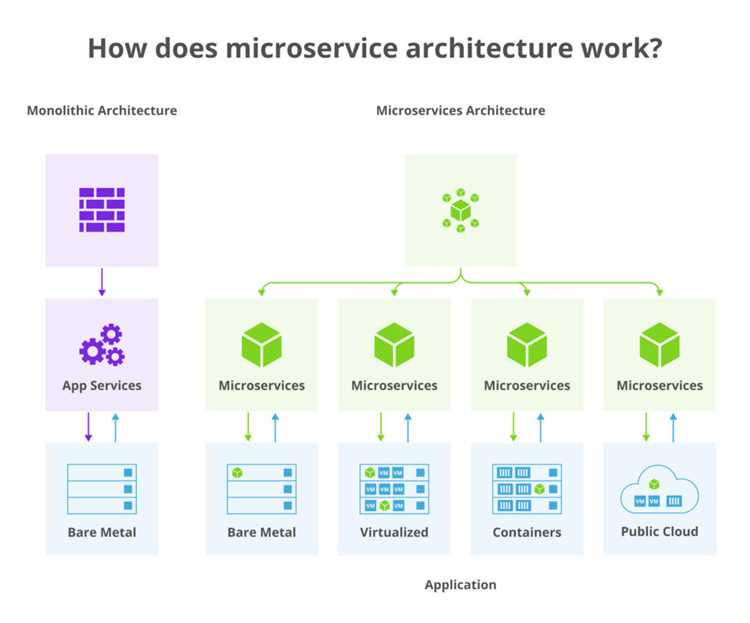
Микросервисы позволяют создавать гибкие и масштабируемые приложения, но требуют дисциплины в проектировании, контроле версий API и управлении конфигурациями. Практика показывает, что использование контейнеризации и оркестраторов, таких как Docker и Kubernetes, значительно упрощает развертывание и поддержку распределенной архитектуры.
Микросервис в программировании: принципы работы и применение

Разделение ответственности обеспечивает минимизацию зависимостей между сервисами. Каждый микросервис хранит собственную базу данных и предоставляет четко определенные API. Это снижает вероятность ошибок при изменениях и упрощает внедрение новых функций без остановки всей системы.
При разработке микросервисов важно учитывать масштабируемость и устойчивость к сбоям. Контейнеризация с использованием Docker и управление через Kubernetes позволяют быстро развертывать новые экземпляры сервисов, распределять нагрузку и контролировать состояние компонентов. Метрики, логирование и распределенный трейсинг обеспечивают своевременное обнаружение проблем и анализ производительности.
Выбор технологий для микросервисов определяется конкретной задачей: транзакционные сервисы чаще используют SQL, аналитические и кэширующие – NoSQL. Версионирование API и стратегия отката позволяют безопасно внедрять изменения и поддерживать совместимость между различными частями системы.
Как выделить микросервисы из монолитного приложения
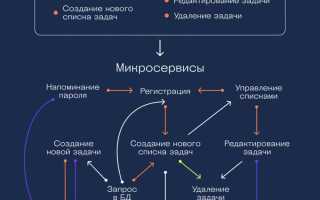
Выделение микросервисов начинается с анализа бизнес-логики монолита. Необходимо определить независимые функциональные блоки, которые могут работать автономно, и оценить их границы данных и зависимостей. Рекомендуется строить диаграммы взаимодействия компонентов для визуализации связей.
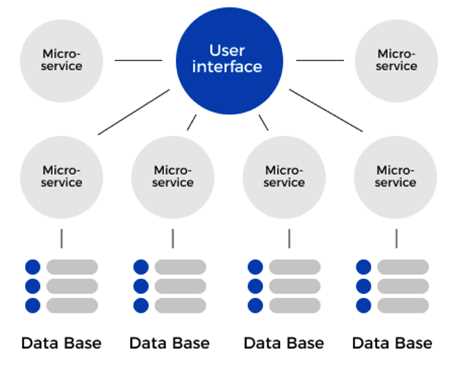
Каждый микросервис должен иметь собственное хранилище данных, чтобы избежать общей базы, создающей жесткую связность. Важно выявить точки интеграции между модулями и спроектировать четкие API для обмена информацией.
При разделении следует учитывать частоту изменений и нагрузку на каждый компонент. Модули с высокой динамикой или интенсивными вычислениями лучше выделять отдельно, чтобы их масштабирование не влияло на остальные сервисы. Одновременно стоит планировать мониторинг и логирование, чтобы отслеживать корректность работы новых сервисов и взаимодействие с остальной системой.
Реализация этапами снижает риски: сначала выделяют критически независимые сервисы, тестируют их отдельно, затем постепенно декомпозируют менее автономные функции. Такой подход позволяет минимизировать простои и сохранить стабильность монолита во время перехода на микросервисную архитектуру.
Организация взаимодействия микросервисов через API

Взаимодействие микросервисов строится на четко определенных API, которые обеспечивают обмен данными и контроль состояния компонентов. Наиболее распространенные подходы включают REST, использующий HTTP и JSON, и gRPC, обеспечивающий бинарный протокол и низкую задержку. Выбор протокола зависит от требований к производительности и объему передаваемых данных.
Для документирования и тестирования API рекомендуется использовать OpenAPI или Protocol Buffers. Это облегчает интеграцию, позволяет автоматически генерировать клиентские библиотеки и проверять соответствие контракту.
Рассмотрим базовые элементы взаимодействия в виде таблицы:
| Элемент | Назначение | Рекомендации |
|---|---|---|
| Эндпоинт | Определяет адрес сервиса и метод доступа | Использовать уникальные URI и версионирование API |
| Запрос | Передача данных сервису | Минимизировать объем данных, использовать стандартизированные форматы JSON или Protobuf |
| Ответ | Возврат результата операции | Включать код состояния и подробное описание ошибок |
| Аутентификация | Контроль доступа к сервису | Применять токены JWT или OAuth2 для каждого запроса |
| Логирование и мониторинг | Отслеживание работы сервисов | Использовать распределенные трассировки и метрики по каждому API |
Соблюдение этих принципов позволяет создать предсказуемую систему взаимодействия микросервисов, упрощает масштабирование и сокращает риск ошибок при интеграции новых компонентов.
Выбор технологий для разработки отдельных микросервисов

При разработке микросервисов важно подбирать технологии с учетом характера задач и требований к производительности. Для вычислительных сервисов подходят языки с высокой скоростью выполнения, такие как Go или Rust. Для веб-сервисов с богатой экосистемой и готовыми библиотеками часто используют Java, C# или Python.
Выбор базы данных зависит от типа данных и частоты операций. Транзакционные микросервисы оптимально использовать с реляционными базами SQL, например PostgreSQL или MySQL. Для сервисов с большими объемами логов или аналитики лучше применять NoSQL базы – MongoDB, Cassandra или Redis.
Для обмена данными между микросервисами предпочтительно использовать стандартизированные протоколы. REST на базе JSON подходит для большинства задач, а gRPC и Protobuf – для высокопроизводительных сервисов с низкой задержкой и частыми вызовами.
Инструменты для развертывания и оркестрации контейнеров, такие как Docker и Kubernetes, обеспечивают контроль конфигураций и масштабирование. Также рекомендуется использовать системы CI/CD для автоматизации сборки, тестирования и релизов отдельных микросервисов, чтобы ускорить внедрение изменений без сбоев в работе всей системы.
Методы хранения данных в микросервисной архитектуре
Каждый микросервис должен управлять собственным хранилищем данных, чтобы исключить прямые зависимости между сервисами. Реляционные базы SQL, такие как PostgreSQL или MySQL, подходят для транзакционных сервисов с целостностью данных и сложными запросами. Для аналитики, кэширования или хранения неструктурированных данных используют NoSQL базы – MongoDB, Cassandra, Redis.
Для обеспечения консистентности данных между сервисами применяют паттерны Event Sourcing и CQRS. Event Sourcing фиксирует все изменения состояния через события, а CQRS разделяет операции чтения и записи, позволяя оптимизировать нагрузку и ускорять обработку запросов.
Репликация и шардирование помогают масштабировать хранилища и распределять нагрузку. При выборе метода важно учитывать частоту обновлений и требования к доступности: горячие данные можно хранить в памяти через Redis, а исторические – в долговременных хранилищах с архивацией.
Для взаимодействия микросервисов с базами рекомендуется использовать API-слой или сервисную шину данных, что предотвращает прямой доступ к чужим таблицам и упрощает изменение структуры хранилищ без нарушения работы системы.
Подходы к тестированию и отладке микросервисов
Тестирование микросервисов строится на нескольких уровнях. Юнит-тесты проверяют отдельные функции внутри сервиса и обеспечивают корректность бизнес-логики. Для проверки взаимодействия между сервисами используют интеграционные тесты, имитирующие вызовы API и сценарии обмена данными.
Контейнеризация позволяет запускать микросервисы в изолированной среде, что облегчает отладку и автоматическое тестирование. Рекомендуется применять тестовые среды с поддельными сервисами (mock) и базами данных для минимизации влияния на продуктивную систему.
Нагрузочное тестирование и стресс-тестирование выявляют узкие места и помогают определить предел масштабирования каждого сервиса. Метрики производительности, логирование и распределённый трейсинг позволяют отслеживать время отклика, ошибки и цепочки вызовов, упрощая поиск проблем в распределённой архитектуре.
Для управления тестами и релизами полезно внедрять CI/CD пайплайны с автоматическим прогоном тестов, что снижает риск внедрения ошибок и ускоряет выпуск новых версий сервисов.
Применение микросервисов в реальных проектах и примеры
Микросервисы применяются для масштабируемых веб-приложений, систем обработки больших данных и распределенных сервисов. Они позволяют разрабатывать, развертывать и обновлять отдельные компоненты без остановки всей системы.
Примеры использования:
- Электронная коммерция: отдельные микросервисы для каталога товаров, корзины, платежей и уведомлений.
- Платежные системы: раздельные сервисы для верификации транзакций, обработки платежей, генерации отчетов и мониторинга безопасности.
- Социальные сети: микросервисы для ленты новостей, уведомлений, обмена сообщениями и управления профилями пользователей.
- Облачные платформы: отдельные сервисы для аутентификации, управления ресурсами, хранения данных и логирования.
Рекомендации при внедрении:
- Сначала выделять сервисы с наибольшей автономностью, чтобы минимизировать влияние на существующую систему.
- Использовать контейнеризацию и оркестраторы для автоматизации развертывания и масштабирования.
- Применять централизованное логирование и мониторинг, чтобы отслеживать состояние всех микросервисов.
- Планировать версионирование API и стратегию отката изменений для обеспечения совместимости сервисов.
Вопрос-ответ:
Что такое микросервис и чем он отличается от монолитного приложения?
Микросервис — это отдельный компонент приложения, выполняющий конкретную функцию и работающий независимо от других модулей. В отличие от монолита, где вся логика объединена в одном приложении, микросервисы разделены по бизнес-областям, что позволяет обновлять и масштабировать их отдельно, не затрагивая всю систему.
Как выбрать границы микросервисов при декомпозиции монолита?
Границы микросервисов определяются бизнес-функциями и уровнем независимости данных. Рекомендуется выделять модули с минимальными зависимостями, которые могут функционировать автономно. Также учитывают частоту изменений и нагрузку: сервисы с высокой активностью или интенсивными вычислениями лучше отделять, чтобы масштабирование одного компонента не влияло на остальные.
Какие протоколы лучше использовать для обмена данными между микросервисами?
Для взаимодействия между микросервисами применяют REST с JSON или gRPC с Protobuf. REST подходит для большинства веб-приложений, обеспечивает совместимость и простоту интеграции. gRPC используют для сервисов с высокой частотой вызовов и требованиями к минимальной задержке, благодаря бинарному протоколу и поддержке стриминга.
Как организовать хранение данных в микросервисной архитектуре?
Каждый микросервис должен иметь собственное хранилище данных. Транзакционные сервисы используют реляционные базы SQL, аналитические и кэш-сервисы — NoSQL. Для согласованности данных применяют паттерны Event Sourcing и CQRS, а для масштабирования — репликацию и шардирование. Важно избегать прямого доступа одного сервиса к таблицам другого и использовать API для обмена данными.
Какие методы тестирования применяются для микросервисов?
Тестирование строится на нескольких уровнях: юнит-тесты проверяют отдельные функции сервиса, интеграционные тесты проверяют взаимодействие между сервисами, нагрузочные тесты выявляют пределы производительности. Контейнеризация и мок-сервисы позволяют тестировать микросервисы изолированно. Логирование, метрики и распределённый трейсинг помогают отслеживать ошибки и производительность в реальном времени.
Какие преимущества дает микросервисная архитектура по сравнению с монолитом?
Микросервисная архитектура позволяет разделять приложение на независимые компоненты, каждый из которых выполняет конкретную функцию и управляет собственными данными. Это снижает риск сбоев при внесении изменений, упрощает масштабирование отдельных сервисов и ускоряет внедрение новых функций. Кроме того, можно использовать разные технологии для разных компонентов, подбирая инструменты под конкретные задачи, что повышает гибкость разработки и обслуживания. Важно организовать четкие API и логирование, чтобы поддерживать согласованность системы и отслеживать ошибки.