Содержание статьи

Регулярные выражения (RegEx) позволяют находить, проверять и изменять текст с точностью до символа. Они используют шаблоны, состоящие из обычных символов и специальных метасимволов, которые задают правила поиска. Например, шаблон \d{3}-\d{2}-\d{4} проверяет строки формата социальных номеров в США.
В программировании регулярные выражения применяются для валидации данных, поиска ключевых слов, парсинга логов и массовой замены текста. В Python функция re.match() проверяет соответствие шаблону с начала строки, а re.findall() возвращает все совпадения. В JavaScript метод string.match() выполняет аналогичные задачи.
Правильное использование квантификаторов и группировки позволяет обрабатывать сложные структуры текста без лишних циклов. Например, выражение (https?:\/\/[^\s]+) извлекает ссылки из текста, игнорируя пробелы. Методы тестирования регулярных выражений, такие как онлайн-редакторы и встроенные функции, помогают избегать ошибок при составлении шаблонов.
Знание базовых метасимволов, квантификаторов и флагов ускоряет обработку данных и упрощает анализ больших текстовых массивов. Освоение этих инструментов позволяет решать задачи от простой проверки формата номера телефона до сложного парсинга логов или HTML-кода.
Регулярные выражения в программировании: основы и примеры
Регулярные выражения представляют собой последовательность символов, задающих шаблон для поиска и обработки текста. Основные элементы включают:
- Символы: буквенные и цифровые символы соответствуют самим себе.
- Метасимволы: точки (.), звездочки (*), плюс (+) и вопрос (?) управляют совпадениями.
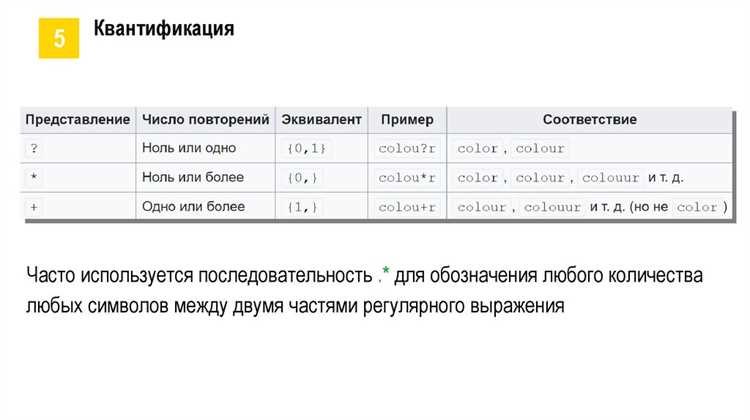
- Квантификаторы: задают количество повторений символов или групп, например {2,5} ищет от 2 до 5 повторов.
- Группы и скобки: позволяют объединять символы для совместной обработки или захвата подстрок.
- Классы символов: [a-z], \d, \w упрощают поиск определенных наборов символов.
- Флаги: модифицируют поведение поиска, например i – игнорирование регистра, g – глобальный поиск.
Примеры использования регулярных выражений:
- Проверка формата email: ^[\w.-]+@[\w.-]+\.\w{2,4}$ – проверяет наличие букв, цифр, точки и домена.
- Извлечение телефонов: \+?\d{1,3}[-\s]?\(?\d{1,4}\)?[-\s]?\d{3,4}[-\s]?\d{3,4} – захватывает международные и локальные форматы.
- Парсинг URL: https?:\/\/[^\s]+ – находит ссылки, начинающиеся с http или https.
- Замена пробелов на подчеркивания: \s+ заменяется на _ с помощью re.sub() или string.replace().
- Выбор слов, начинающихся с заглавной буквы: \b[A-ZА-ЯЁ][a-zа-яё]*\b – выделяет имена и названия.
Для разработки сложных выражений рекомендуется тестировать шаблоны на разных примерах текста, использовать комментарии внутри выражений ((?x) в Python) и минимизировать жадные квантификаторы, чтобы избежать захвата лишних данных.
Как составлять простые шаблоны для поиска текста

Простые шаблоны в регулярных выражениях строятся на прямом совпадении символов и ограниченном наборе метасимволов. Для поиска слова «код» достаточно шаблона код, который найдет все точные совпадения в строке.
Для учета разных вариантов символов используются классы символов. Например, [Кк]од найдет как Код, так и код. Аналогично, [0-9] ищет любую цифру, а [a-zA-Z] – любую букву латинского алфавита.
Метасимвол . заменяет любой один символ. Шаблон c.d найдет cad, c1d или c-d. Для поиска конкретных повторов символов применяются квантификаторы: * – любое количество, включая ноль, + – один или более раз, ? – ноль или один раз.
Использование якорей ^ и $ позволяет ограничить поиск началом или концом строки. Пример: ^Привет найдет строки, начинающиеся с Привет, а мир$ – строки, заканчивающиеся на мир.
Для группировки символов и создания подшаблонов применяются скобки (). Пример: (кот|пес) найдет кот или пес в тексте. Комбинирование этих правил позволяет составлять простые, но точные шаблоны для поиска конкретных текстовых фрагментов.
Использование метасимволов для точного совпадения

Метасимволы позволяют задать точные правила поиска в регулярных выражениях. Символ . заменяет любой одиночный символ, что удобно при неизвестных символах в слове. Пример: т.к найдет так, т1к, т-к.
Якоря ^ и $ ограничивают позицию совпадения. ^дом ищет строки, начинающиеся с дом, а книга$ – строки, заканчивающиеся на книга.
Метасимволы для классов символов помогают точнее определять допустимые символы. [abc] соответствует одному символу из набора a, b, c. [0-9] выбирает любую цифру, [а-яА-Я] – любую букву кириллицы.
Экранирование с помощью \ используется для поиска специальных символов. Чтобы найти точку, необходимо писать \., иначе она будет работать как метасимвол. Аналогично \*, \+ и \?.
Квантификаторы *, +, ? и {n,m} уточняют количество повторений символов или групп. Пример: \d{2,4} найдет от 2 до 4 цифр подряд. Сочетание метасимволов и квантификаторов позволяет строить точные шаблоны для поиска сложных текстовых фрагментов.
Применение квантификаторов для повторений символов
Квантификаторы определяют количество повторений символов или групп в регулярных выражениях. Символ * соответствует нулю или более повторов, + – одному или более, ? – нулю или одному. Например, го+д найдет год, гоод, гооод.
Фигурные скобки {n}, {n,} и {n,m} задают точное количество или диапазон повторений. Пример: \d{3} найдет ровно три цифры, а \d{2,4} – от двух до четырех.
Для проверки повторений символов в строке можно использовать группы. Пример: (ab){2,3} найдет abab и ababab, но не ab один раз. Группы позволяют комбинировать несколько символов и применять к ним один квантификатор.
Жадные квантификаторы захватывают максимум возможных символов, поэтому для точного совпадения иногда применяют модификатор ? после квантификатора, превращая его в ленивый. Пример: «.*?» найдет минимальный фрагмент текста в кавычках.
Правильное использование квантификаторов ускоряет обработку текста и сокращает количество лишних совпадений, особенно при анализе логов, проверке форматов и парсинге больших текстовых массивов.
Группировка и захват подстрок в выражениях
Группировка в регулярных выражениях выполняется с помощью круглых скобок (). Она позволяет объединять несколько символов или подвыражений для совместного применения квантификаторов или извлечения данных. Пример: (abc){2} найдет abcabc.
Захват подстрок используется для получения частей текста, соответствующих определенным группам. В Python группы доступны через метод group(), а в JavaScript через match(). Пример: шаблон (\d{2})-(\d{2})-(\d{4}) разделяет дату 25-10-2025 на день, месяц и год.
Для необязательного захвата применяется синтаксис (?:…). Такие группы не создают отдельного захватываемого блока, что упрощает обработку при сложных шаблонах. Пример: (?:http|https)://[^\s]+ находит ссылки без создания лишних подгрупп.
Именованные группы упрощают работу с подстроками. Синтаксис (?P<имя>…) в Python или (?<имя>…) в JavaScript позволяет обращаться к группам по имени: (?P<день>\d{2})-(?P<месяц>\d{2})-(?P<год>\d{4}).
Группировка и захват подстрок упрощают разбор сложных текстовых данных, выделение отдельных элементов и дальнейшую их обработку в коде без дополнительных операций по разбиению строк.
Поиск и замена текста с помощью регулярных выражений
Регулярные выражения позволяют не только находить текст, но и заменять его по заданным шаблонам. В Python используется метод re.sub(), в JavaScript – string.replace() с регулярным выражением.
Примеры типичных операций:
| Задача | Регулярное выражение | Замена |
|---|---|---|
| Замена всех пробелов на подчеркивания | \s+ | _ |
| Удаление всех цифр из текста | \d | «» |
| Форматирование дат из 20251028 в 28-10-2025 | (\d{4})(\d{2})(\d{2}) | \3-\2-\1 |
| Замена нескольких пробелов на один | \s{2,} | |
| Добавление скобок к телефонным номерам | (\d{3})(\d{3})(\d{4}) | (\1) \2-\3 |
Для точного поиска и замены рекомендуется использовать якоря ^ и $, а также группы для разделения частей текста. Флаги i и g позволяют учитывать регистр и применять замену глобально по всей строке. Проверка результата на нескольких примерах помогает избежать случайных замен и ошибок формата.
Проверка формата данных: email, телефон, дата
Регулярные выражения позволяют валидировать текстовые данные перед обработкой. Для проверки email используется шаблон ^[\w.-]+@[\w.-]+\.\w{2,4}$, который проверяет наличие имени пользователя, символа @ и домена с расширением от 2 до 4 символов.
Телефонные номера можно проверять через шаблоны, учитывающие международный и локальный формат. Пример: \+?\d{1,3}[-\s]?\(?\d{1,4}\)?[-\s]?\d{3,4}[-\s]?\d{3,4} позволяет распознать номера с кодом страны, скобками, дефисами и пробелами.
Для даты в формате ДД-ММ-ГГГГ или ДД/ММ/ГГГГ используется выражение (0[1-9]|[12][0-9]|3[01])[-/](0[1-9]|1[0-2])[-/](\d{4}). Оно проверяет допустимые значения дня и месяца и фиксирует четырехзначный год.
Использование группирования и якорей ^ и $ гарантирует точное совпадение всего текста с шаблоном. Для динамических форматов рекомендуется тестировать шаблоны на разнообразных примерах и комбинировать квантификаторы для обработки необязательных символов.
Игнорирование регистра и специальные флаги

Регулярные выражения поддерживают флаги, которые изменяют поведение поиска. Наиболее часто используемые флаги:
- i – игнорирование регистра символов. Пример: /привет/i найдет Привет, ПРИВЕТ и привет.
- g – глобальный поиск. Совпадения ищутся по всей строке, а не только первое. Пример: /\d+/g вернет все числа в тексте.
- m – многострочный режим. Якоря ^ и $ применяются к каждой строке, а не ко всей строке целиком.
- s – точка . совпадает с любым символом, включая перевод строки.
- x – расширенный режим (Python), позволяет добавлять пробелы и комментарии в шаблон для читаемости.
Флаги можно комбинировать для более гибкого поиска. Пример: /^error\d+/igm найдет все строки, начинающиеся с error с любым регистром, включая многострочный текст.
Рекомендуется использовать флаги только при необходимости, чтобы избегать нежелательных совпадений. Проверка шаблона на нескольких примерах позволяет убедиться, что комбинация флагов работает корректно и возвращает ожидаемые результаты.
Отладка регулярных выражений и тестирование на примерах
Отладка регулярных выражений необходима для точного совпадения с текстом и предотвращения ошибок. Используются онлайн-редакторы и встроенные функции языков программирования, например re.debug() в Python или консольные методы в JavaScript.
Тестирование проводится на реальных или максимально приближенных к реальности данных. Пример: для проверки шаблона email создаются строки с корректными и некорректными адресами, чтобы убедиться, что шаблон различает их.
При сложных выражениях рекомендуется:
- Разбивать шаблон на части и проверять каждую отдельно.
- Использовать группы для захвата подстрок и проверять их содержимое.
- Применять жадные и ленивые квантификаторы для контроля объема совпадений.
- Добавлять комментарии в расширенном режиме (x в Python) для читаемости.
- Проверять шаблон с разными флагами, например i или g, чтобы убедиться в правильности глобального поиска и игнорировании регистра.
Регулярные выражения, проверенные на множестве примеров, сокращают вероятность ошибок при работе с реальными данными и ускоряют обработку текстовых массивов.
Вопрос-ответ:
Что такое регулярные выражения и для чего они используются в программировании?
Регулярные выражения — это шаблоны для поиска, проверки и изменения текста. Их применяют для валидации данных, извлечения информации из строк, обработки логов и массовой замены текста. Например, с помощью шаблона \d{3}-\d{2}-\d{4} можно проверить формат социального номера.
Какие основные метасимволы нужны для точного поиска?
Метасимволы задают правила сопоставления символов. Точка . заменяет любой символ, звездочка * — ноль или более повторов, плюс + — один и более повторов, вопрос ? — ноль или один. Якоря ^ и $ ограничивают начало и конец строки, а классы символов [a-z], \d, \w позволяют выбирать конкретные наборы символов.
Как применять квантификаторы для повторений символов?
Квантификаторы управляют количеством повторений символов или групп. * соответствует нулю или более повторов, + — одному и более, {n,m} задает диапазон. Пример: \d{2,4} найдет последовательности от двух до четырех цифр, а (ab){2,3} — комбинации abab и ababab.
Какие методы позволяют тестировать и отлаживать регулярные выражения?
Для отладки используют онлайн-редакторы и встроенные функции языков программирования, например re.debug() в Python. Рекомендуется проверять шаблон на разных примерах текста, разбивать сложные выражения на части, использовать группы для захвата подстрок и контролировать поведение квантификаторов, чтобы убедиться в точности совпадений.
Как проверить формат email, телефона и даты с помощью регулярных выражений?
Для email используют шаблон ^[\w.-]+@[\w.-]+\.\w3[01])[-/](0[1-9]), чтобы отбирать допустимые дни и месяцы и фиксировать четырехзначный год.
Как правильно использовать группы и квантификаторы в регулярных выражениях для извлечения конкретных данных из текста?
Группы создаются с помощью круглых скобок () и позволяют объединять несколько символов или подвыражений, к которым применяются квантификаторы. Квантификаторы, такие как *, +, ? или {n,m}, задают количество повторений. Например, шаблон (\d{2})-(\d{2})-(\d{4}) разбивает дату 28-10-2025 на отдельные части: день, месяц и год. Группы можно использовать для извлечения этих значений и дальнейшей обработки в коде, а квантификаторы позволяют учитывать переменное количество символов или цифр, упрощая работу с текстом различных форматов. Для сложных случаев рекомендуется тестировать шаблон на нескольких примерах и использовать жадные или ленивые квантификаторы в зависимости от задачи.