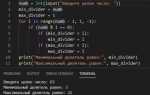
Содержание статьи

CSV-файлы часто приходят из разных источников: выгрузки аналитики, экспорт данных из CRM, результаты мониторинга. Форматы могут отличаться – набор столбцов, кодировка, разделители. Python позволяет привести такие файлы к единообразию и собрать их в один набор данных без ручной сверки.
При работе с несколькими CSV важно заранее определить правила: какие столбцы должны быть в итоговом файле, как обрабатывать отсутствующие значения, требуется ли сортировка строк. Эти решения влияют на порядок объединения и выбор инструментов – pandas или стандартного модуля csv.
На практике часто используют подход с предварительным сканированием директории, автоматическим чтением всех файлов и последующим объединением в общий DataFrame. Такой метод удобен при регулярных обновлениях данных, так как список файлов формируется динамически. Далее результат сохраняется в единый CSV, доступный для дальнейшей обработки и анализа.
Подготовка списка файлов для объединения через glob

Модуль glob позволяет сформировать перечень CSV без ручного перебора. Шаблон выбирается исходя из структуры каталогов и формата имен файлов. Такой подход избавляет от риска пропустить файл или включить лишний.
Практичная последовательность действий:
- Определить директорию, где находятся все CSV. Желательно использовать абсолютный путь, чтобы исключить зависимости от текущей рабочей директории.
- Сформировать шаблон, например «*.csv» или «report_*.csv», если в каталоге присутствуют файлы других типов.
- Получить список файлов с помощью glob.glob() и проверить, что в перечень попадает нужный набор данных.
Проверка списка перед обработкой важна, поскольку отдельные файлы могут отличаться датой создания, размером или кодировкой. Для удобства можно вывести количество найденных файлов и их имена, отсортировав результат по алфавиту.
Чтение нескольких CSV с помощью pandas.read_csv

После получения списка путей к CSV файлам удобнее всего прочитать каждый файл через pandas.read_csv(). Функция позволяет задать параметры, которые устраняют расхождения между источниками данных: разделитель, кодировка, типы столбцов.
Часто возникает необходимость указать:
- sep – если файлы используют точку с запятой или табуляцию;
- encoding – для корректной загрузки кириллических данных, например «utf-8» или «cp1251»;
- dtype – чтобы избежать автоматического преобразования числовых значений в строки или наоборот;
- parse_dates – для точной обработки дат, особенно если формат нестандартный.
Файлы удобно загружать в цикл, создавая список DataFrame. Такой список затем передаётся в функцию объединения. Перед добавлением в общий список полезно проверить количество строк и столбцов, чтобы убедиться, что каждый файл загружен корректно и не содержит неожиданных изменений структуры.
Обработка расхождений в заголовках столбцов перед объединением
CSV из разных систем часто имеют отличия в названиях полей: разный регистр, пробелы, лишние символы или альтернативные варианты одного и того же обозначения. Без предварительного выравнивания объединение приводит к появлению дублирующих столбцов, поэтому заголовки требуется привести к единому виду.
На практике используют следующие приёмы:
- нормализация регистра, например перевод всех названий в нижний;
- удаление пробелов в начале и конце строки;
- замена пробелов и дефисов на подчёркивание для стабильного доступа к столбцам;
- создание словаря соответствий, если разные источники используют свои обозначения одного поля (например, «price» и «cost»).
Перед объединением удобно вывести список уникальных заголовков для каждого файла и сравнить их. Если обнаружены расхождения, стоит применить единые правила преобразования или выполнить переименование через DataFrame.rename(). Такой подход предотвращает разрыв структуры при дальнейшей сборке данных.
Склеивание файлов в один DataFrame с pandas.concat
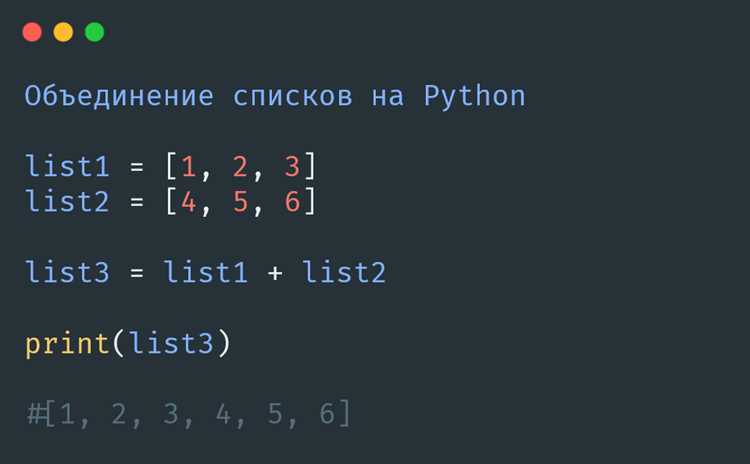
После подготовки списка DataFrame удобнее всего объединить их с помощью pandas.concat(). Функция собирает данные построчно и сохраняет порядок источников, что важно при дальнейшей обработке.
Для объединения используется простой вызов: pandas.concat(list_of_dfs, ignore_index=True). Параметр ignore_index создаёт непрерывную нумерацию строк в итоговом наборе, исключая повторение индексов из отдельных файлов.
Если структура столбцов различается, можно указать join=»inner» для сохранения только общих полей или join=»outer» для включения всех столбцов. Второй вариант удобен при постепенном расширении схемы данных. При внешнем объединении пропуски лучше заполнить заранее определённым значением через DataFrame.fillna().
Перед сохранением итогового DataFrame имеет смысл проверить количество строк, набор столбцов и типы данных, чтобы убедиться, что все исходные файлы были обработаны корректно.
Сохранение результата в единый CSV с указанием параметров записи
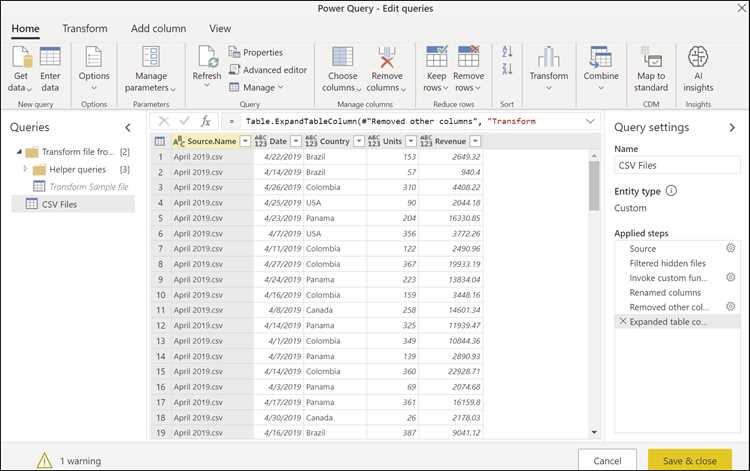
Ключевые параметры, которые стоит определить заранее:
- index=False – исключает сохранение индекса, чтобы в итоговом файле не появлялась дополнительная колонка;
- sep – выбор разделителя, чаще всего «,» или «;», в зависимости от требований системы, которая будет читать файл;
- encoding – распространённые варианты: «utf-8» для универсальности, «utf-8-sig» для корректного открытия в Excel;
- line_terminator – полезен при необходимости строгого контроля формата строк, например при выгрузке в системы, требующие «\n» вместо «\r\n».
Перед сохранением рекомендуется проверить порядок столбцов и их названия, чтобы итоговый файл соответствовал ожидаемой структуре. Если набор данных большой, стоит убедиться, что выбранная кодировка поддерживается целевой платформой.
Объединение файлов построчно при помощи стандартного модуля csv
Для простых задач объединения CSV без сторонних библиотек подходит стандартный модуль csv. Он позволяет построчно читать файлы и сразу записывать их в общий файл, что экономит память при работе с большими наборами данных.
Практический порядок действий:
- Открыть итоговый файл для записи с newline=»» и нужной кодировкой.
- Создать csv.writer для записи строк.
- Для каждого исходного файла открыть его через csv.reader, пропустить заголовок после первой итерации, чтобы не дублировать его.
- Перебирать строки и записывать их в итоговый файл через writer.writerow().
- Закрыть все файлы после завершения цикла.
Такой метод особенно полезен, если исходные CSV занимают сотни мегабайт, поскольку он не требует загрузки всех данных в оперативную память. Также легко управлять разделителями и кодировкой для совместимости с другими системами.
Проверка итогового файла на корректность структуры и кодировки
После объединения нескольких CSV важно убедиться, что итоговый файл соответствует ожидаемой структуре и корректно отображает все данные. Ошибки в заголовках или кодировке могут привести к сбоям при дальнейшем анализе.
Практические шаги проверки:
- Открыть файл в текстовом редакторе с поддержкой выбранной кодировки и убедиться, что все символы отображаются правильно.
- Загрузить файл в Python с pandas.read_csv() и проверить количество строк и столбцов:
| Параметр | Описание |
|---|---|
| shape | Возвращает количество строк и столбцов для сверки с ожидаемыми значениями. |
| columns | Список заголовков столбцов для проверки соответствия исходным данным. |
| dtypes | Типы данных каждого столбца, чтобы убедиться в правильной интерпретации чисел, дат и строк. |
Дополнительно можно проверить первые и последние строки с head() и tail(), чтобы убедиться в отсутствии пустых или повреждённых записей. Если обнаружены проблемы, корректировку выполняют через повторное чтение и преобразование столбцов или изменение кодировки при сохранении.
Вопрос-ответ:
Как автоматически собрать список CSV файлов из папки для объединения?
Для сбора файлов используют модуль glob. Нужно указать путь к директории и шаблон, например «*.csv». Функция glob.glob() возвращает список всех файлов, соответствующих шаблону. Перед обработкой удобно отсортировать список и проверить, что включены только нужные файлы.
Можно ли объединять CSV с разными заголовками столбцов и как это сделать?
Если столбцы отличаются, перед объединением нужно привести их к единой структуре. Это делают с помощью переименования через DataFrame.rename(), нормализации регистра, удаления пробелов и замены специальных символов. Для автоматической обработки создают словарь соответствий между названиями столбцов разных файлов.
Что лучше использовать для объединения больших CSV файлов — pandas или стандартный csv?
Для больших наборов данных стандартный модуль csv позволяет построчно считывать и записывать данные, что экономит память. Pandas удобен при работе с таблицами, где нужно сразу анализировать или фильтровать данные, но при ограниченной памяти лучше использовать построчную обработку через csv.reader и csv.writer.
Как сохранить объединённый CSV с правильной кодировкой для Excel?
При сохранении через DataFrame.to_csv() нужно указать параметр encoding=»utf-8-sig». Это обеспечивает корректное отображение кириллицы в Excel. Дополнительно рекомендуется задать index=False, чтобы не добавлять лишнюю колонку с индексами.
Как проверить, что итоговый CSV файл не потерял строки и столбцы после объединения?
После объединения можно загрузить файл в pandas и проверить параметры: shape для количества строк и столбцов, columns для списка заголовков, dtypes для типов данных. Также полезно просмотреть первые и последние строки с помощью head() и tail() для обнаружения пропусков или некорректных значений.
Можно ли объединять CSV файлы с разными разделителями и как это правильно сделать в Python?
Да, можно. При чтении файлов с помощью pandas.read_csv() или стандартного csv.reader нужно указать параметр sep, соответствующий разделителю в каждом файле, например «,» или «;». Если файлы содержат разные разделители, их читают по отдельности с указанием нужного разделителя, затем объединяют в общий DataFrame через pandas.concat() или построчно через csv.writer. После объединения желательно сохранить итоговый CSV с единым разделителем, чтобы избежать проблем при последующем анализе.