Содержание статьи

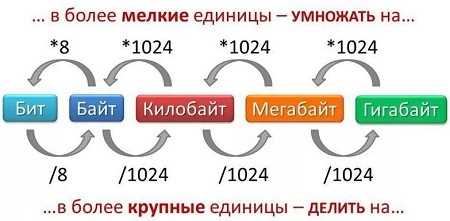
4 байта занимают 32 бита, что напрямую влияет на количество символов, которые можно сохранить в памяти. Для однобайтовых кодировок, таких как ASCII, каждый символ занимает ровно 1 байт, следовательно, в 4 байта помещается 4 символа. Это важно учитывать при работе с текстовыми файлами и базами данных.
В кодировке UTF-8 символы могут занимать от 1 до 4 байт. Например, латинские буквы и цифры используют 1 байт, большинство европейских символов – 2 байта, а иероглифы и эмодзи могут занимать 3–4 байта. Таким образом, максимальное количество символов в 4 байтах варьируется от 1 до 4, в зависимости от конкретных символов.
При проектировании структур данных или передачи сообщений в сетях необходимо заранее учитывать, сколько байт занимает каждый символ. Для латинского текста можно безопасно рассчитывать на 4 символа в 4 байтах, тогда как для многоязычных текстов или смайликов стоит проверять размер конкретных символов, чтобы избежать ошибок переполнения или потери данных.
Сколько бит содержится в 4 байтах
1 байт состоит из 8 бит. Соответственно, 4 байта содержат 32 бита. Это количество определяет, сколько информации можно хранить или передавать в пределах этого объема памяти.
В программировании и сетевых протоколах важно понимать, что 32 бита могут представлять не только 4 однобайтовых символа, но и одно целое число размером до 4 байт или комбинацию меньших объектов. Для точного расчета символов необходимо учитывать кодировку текста.
| Единица измерения | Количество бит | Комментарий |
|---|---|---|
| 1 байт | 8 бит | Стандартный размер для большинства символов ASCII |
| 2 байта | 16 бит | Подходит для большинства европейских символов в UTF-16 |
| 4 байта | 32 бит | Максимальный размер одного символа в UTF-32 или 4 однобайтовых символа ASCII |
Рекомендуется при проектировании систем учитывать, что 32 бита позволяют хранить комбинации символов различной длины. Для ASCII текста это всегда 4 символа, а для Unicode – меньше, если используются многобайтовые символы.
Максимальное количество символов в 4 байтах для ASCII
В кодировке ASCII каждый символ занимает ровно 1 байт. Соответственно, 4 байта позволяют хранить 4 ASCII-символа. Это относится к стандартному набору символов: латинские буквы, цифры, знаки препинания и управляющие символы.
При работе с текстом, ограниченным ASCII, можно точно рассчитывать объем памяти и количество символов в буфере. Например, строка из 4 символов ‘ABCD’ полностью помещается в 4 байта, без необходимости дополнительного выделения памяти.
Рекомендуется при проектировании баз данных и протоколов обмена сообщениями учитывать, что для ASCII текстов расчет символов по байтам всегда прямой: 1 символ = 1 байт. Это позволяет эффективно управлять памятью и предотвращает переполнение буферов.
Влияние кодировки UTF-8 на количество символов
В кодировке UTF-8 символы могут занимать от 1 до 4 байт. Латинские буквы и цифры используют 1 байт, большинство европейских букв с диакритикой – 2 байта, а символы из других алфавитов и эмодзи могут занимать 3 или 4 байта. Таким образом, 4 байта могут хранить от 1 до 4 символов в зависимости от их типа.
При работе с UTF-8 важно проверять длину строки в байтах, а не в символах. Например, строка из одного китайского иероглифа может занимать все 4 байта, а четыре латинские буквы – столько же. Это влияет на выделение памяти для текстовых буферов и передачу данных по сети.
Рекомендуется использовать функции подсчета байт, а не символов, при ограничении объема данных, чтобы избежать обрезки многобайтовых символов и ошибок кодирования. Для текстов с многоязычными символами 4 байта редко вместят более одного символа.
Разница между однобайтовыми и многобайтовыми символами
Однобайтовые символы занимают ровно 1 байт и представлены в кодировках ASCII или ISO-8859-1. Многобайтовые символы используют 2–4 байта и встречаются в Unicode (UTF-8, UTF-16). Разница отражается на объеме памяти и количестве символов, помещающихся в 4 байта.
Основные отличия:
- Размер в памяти: однобайтовый символ = 1 байт, многобайтовый = 2–4 байта.
- Диапазон символов: однобайтовый – латинские буквы, цифры и базовые знаки, многобайтовый – иероглифы, арабские, кириллические буквы и эмодзи.
- Подсчет символов: в однобайтовых кодировках число символов равно числу байт, в многобайтовых – необходимо учитывать длину каждого символа.
- Применение: однобайтовые подходят для ограниченного текста, многобайтовые необходимы для многоязычных и специальных наборов символов.
Для 4 байт однобайтовые символы позволяют хранить 4 символа, а многобайтовые – от 1 до 2, в зависимости от конкретных символов. При проектировании текстовых структур важно заранее определить кодировку и возможный набор символов.
Примеры символов, занимающих 1, 2, 3 и 4 байта
В кодировке UTF-8 размер символа определяется количеством байт, необходимых для его хранения. Примеры:
- 1 байт: латинские буквы A, B, C, цифры 0–9, базовые знаки препинания !, ?, ..
- 2 байта: европейские буквы с диакритикой é, ü, ñ, кириллические символы Б, Д, Ж.
- 3 байта: большинство иероглифов китайского и японского языков 汉, 字, 日, арабские буквы ع, ب, ي.
- 4 байта: редкие символы Unicode и эмодзи 🧩, 🏳️🌈, 🤖.
При выделении памяти для текста рекомендуется проверять байтовую длину каждого символа. Для 4 байт это позволяет точно определить, сколько символов можно сохранить: 4 символа по 1 байту, 2 символа по 2 байта или 1 символ, если он занимает 4 байта.
Как считать символы в памяти для разных языков

Количество символов, помещающихся в памяти, зависит от используемой кодировки и конкретного языка. В однобайтовых кодировках, таких как ASCII, 1 символ = 1 байт. Для 4 байт это всегда 4 символа, независимо от текста.
В кодировках Unicode (UTF-8, UTF-16) символы могут занимать разное количество байт:
- Латиница и цифры: 1 байт на символ в UTF-8.
- Европейские буквы с диакритикой, кириллица: 2 байта на символ в UTF-8.
- Иероглифы, арабские и индийские символы: 3 байта на символ в UTF-8.
- Редкие символы и эмодзи: 4 байта на символ в UTF-8.
Для точного расчета символов в памяти следует измерять длину строки в байтах, а не в символах. Пример: 4 байта могут хранить 4 латинских буквы, 2 кириллических или 1 эмодзи. Такой подход предотвращает ошибки переполнения и обрезки текста.
Практическое использование 4 байт в программировании

4 байта широко применяются для хранения числовых и текстовых данных. В программировании это значение используется для:
- Целых чисел: стандартный тип int в большинстве языков занимает 4 байта и может хранить значения от -2 147 483 648 до 2 147 483 647.
- Символов ASCII: 4 байта позволяют хранить 4 символа, что удобно для небольших строк и идентификаторов.
- Флагов и битовых полей: 32 бита используются для хранения логических значений или настроек в виде битовых масок.
- Указателей в 32-битных системах: адрес памяти занимает 4 байта, что обеспечивает точное позиционирование данных.
Рекомендуется учитывать, что при работе с многобайтовыми кодировками, такими как UTF-8, количество символов в 4 байтах может быть меньше, чем 4. Для обработки текста и передачи данных следует проверять длину строки в байтах, чтобы избежать ошибок переполнения и некорректного отображения.
Вопрос-ответ:
Сколько символов ASCII помещается в 4 байта?
В кодировке ASCII каждый символ занимает 1 байт, поэтому в 4 байта помещается ровно 4 символа. Это относится к латинским буквам, цифрам и стандартным знакам препинания. Такой расчет помогает точно планировать размер буферов для текста.
Как кодировка UTF-8 влияет на количество символов в 4 байтах?
UTF-8 использует от 1 до 4 байт на символ. Латинские буквы и цифры занимают 1 байт, европейские буквы с диакритикой и кириллические символы — 2 байта, большинство иероглифов — 3 байта, а редкие символы и эмодзи — 4 байта. Поэтому в 4 байтах можно хранить от 1 до 4 символов в зависимости от выбранного текста.
Почему многобайтовые символы занимают больше места в памяти?
Многобайтовые символы представляют наборы, которых нет в ASCII. Для корректного отображения Unicode-символов системе нужно выделять 2, 3 или 4 байта. Это влияет на расчет памяти: 4 байта могут вместить несколько однобайтовых символов, но всего один многобайтовый, например эмодзи.
Как определить количество символов для текста на разных языках?
Необходимо измерять длину строки в байтах, а не в символах. Для ASCII текста 1 символ = 1 байт. Для UTF-8 текстов с кириллицей или иероглифами длина символов может быть 2–4 байта. Например, 4 байта в UTF-8 позволяют хранить 4 латинских буквы, 2 кириллических или 1 иероглиф.
Как практическое использование 4 байт влияет на программирование?
4 байта применяются для хранения целых чисел типа int, небольших строк ASCII, битовых флагов и указателей в 32-битных системах. При работе с текстами UTF-8 важно проверять длину строки в байтах, чтобы избежать обрезки многобайтовых символов и ошибок передачи данных.