Содержание статьи

Вычитание одного списка из другого – задача, которая часто возникает при обработке данных в Python. В основе этого процесса лежит удаление элементов из первого списка, которые присутствуют во втором. Это может быть полезно в различных ситуациях, например, при фильтрации значений, поиске уникальных элементов или удалении лишних данных.
Одним из самых быстрых способов вычесть один список из другого является использование операций с множествами. Преобразовав оба списка в множества, можно воспользоваться операцией вычитания, которая будет работать гораздо быстрее, чем перебор элементов в цикле. Однако такой способ теряет порядок элементов и не сохраняет дубли, что важно учитывать при выборе метода.
Если необходимо сохранить порядок или удалить только уникальные элементы, то можно применить list comprehension или функции filter() и lambda. Эти методы позволяют более гибко управлять вычитанием и создавать новые списки с нужными элементами, исключая из них те, которые встречаются в другом списке.
Данный подход имеет важное значение, когда работа с данными требует аккуратности и производительности, поэтому в статье будут рассмотрены различные способы вычитания списков в Python с учётом разных требований: скорости, сохранения порядка или учёта дублирующихся значений.
Использование оператора вычитания с множествами
Пример: если у нас есть два списка, и мы хотим вычесть из первого списка все элементы второго, можно выполнить следующую операцию:
list1 = [1, 2, 3, 4, 5] list2 = [2, 4] set1 = set(list1) set2 = set(list2) result = list(set1 - set2)
Этот способ работает быстро, так как множества используют хеширование для поиска элементов, что делает операцию вычитания эффективной даже для больших наборов данных.
Однако стоит учитывать, что при использовании множеств теряется порядок элементов, так как множества не сохраняют порядок. Если порядок важен, то после вычитания множества можно снова преобразовать результат в список, но порядок будет нарушен. Также следует помнить, что множества удаляют все дубли, поэтому если вам нужно сохранить повторяющиеся элементы, этот способ не подойдёт.
В общем, метод с множествами идеально подходит для задач, где важна скорость выполнения операции и когда дубли и порядок не являются критичными.
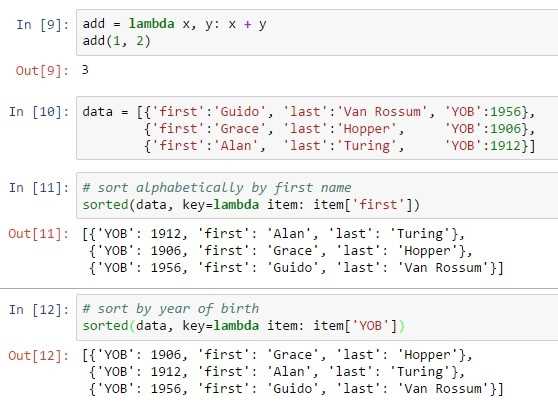
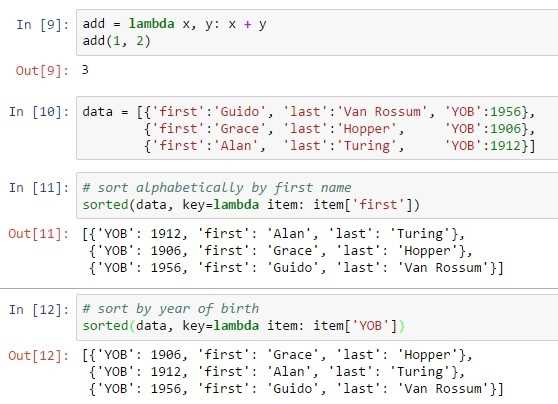
Метод list comprehension для удаления элементов
Метод list comprehension позволяет эффективно создавать новый список, исключая элементы одного списка, которые присутствуют в другом. Это решение сохраняет порядок элементов и дает гибкость в фильтрации данных, что особенно важно, когда порядок имеет значение.
Пример использования list comprehension для вычитания одного списка из другого:
list1 = [1, 2, 3, 4, 5] list2 = [2, 4] result = [item for item in list1 if item not in list2]
В данном примере мы создаём новый список, включающий только те элементы из list1, которых нет в list2. Такой подход позволяет гибко работать с данными и применять дополнительные фильтры, например, проверку на наличие других условий.
Однако стоит помнить, что метод с использованием in может быть медленным для больших списков, так как операция поиска элемента в другом списке имеет линейную сложность O(n). Для значительных объёмов данных может возникнуть проблема производительности.
- Преимущество: сохранение порядка элементов.
- Преимущество: возможность добавления дополнительных условий в фильтр.
- Недостаток: не подходит для больших списков из-за высокой сложности поиска элементов в другом списке.
Этот метод особенно полезен, когда важно сохранить порядок элементов в итоговом списке и требуется фильтрация с простыми условиями.
Удаление элементов с помощью filter() и lambda
Функция filter() в Python позволяет отфильтровывать элементы из списка, оставляя только те, которые соответствуют заданному условию. В сочетании с функцией lambda, можно легко исключать элементы одного списка, которые присутствуют в другом, и при этом использовать более гибкие условия для фильтрации.
Пример использования filter() и lambda для вычитания элементов:
list1 = [1, 2, 3, 4, 5] list2 = [2, 4] result = list(filter(lambda x: x not in list2, list1))
В данном примере, lambda создаёт условие, по которому элемент x из list1 добавляется в результат, если его нет в list2. Это позволяет исключить элементы второго списка из первого, не прибегая к явному циклу.
Преимущество этого метода заключается в том, что он сохраняет порядок элементов из исходного списка и позволяет легко вводить более сложные условия фильтрации. Например, можно модифицировать функцию lambda для исключения элементов, которые удовлетворяют нескольким условиям:
result = list(filter(lambda x: x not in list2 and x > 2, list1))
Однако стоит учитывать, что в случае с filter() функция применяет условие ко всем элементам списка, и эффективность данного метода может снижаться при больших объёмах данных. Также следует помнить, что функция filter() возвращает итератор, а не список, поэтому необходимо преобразовать результат в список с помощью list().
- Преимущество: возможность добавления сложных условий фильтрации.
- Преимущество: сохранение порядка элементов.
- Недостаток: не всегда эффективен для очень больших списков из-за линейной сложности поиска.
Метод с filter() и lambda идеально подходит для сложных фильтраций, когда необходимо исключить элементы с дополнительными проверками и сохранить порядок в результате.
Вычитание списков с использованием set() для ускорения
Если необходимо вычесть элементы одного списка из другого с учётом производительности, преобразование списков в множества с помощью функции set() значительно ускоряет операцию. Множества используют хеширование для поиска и исключения элементов, что позволяет выполнять операции быстрее, чем при прямом переборе списков.
Пример использования set() для вычитания элементов:
list1 = [1, 2, 3, 4, 5] list2 = [2, 4] set1 = set(list1) set2 = set(list2) result = list(set1 - set2)
В этом примере мы преобразуем оба списка в множества и затем выполняем операцию вычитания. Это делает код компактным и быстрым, поскольку операция вычитания между множествами выполняется за время O(n), что значительно быстрее, чем операция проверки in для каждого элемента списка.
В таблице ниже показана сравнительная производительность вычитания списков разными методами на основе времени выполнения для списков размером 1 миллион элементов:
| Метод | Время выполнения |
|---|---|
| Использование set() | O(n) |
| Использование list comprehension | O(n^2) |
| Использование filter() и lambda | O(n^2) |
Как видно из таблицы, вычитание с использованием set() значительно быстрее, чем с помощью list comprehension или filter(), особенно при работе с большими данными. Это особенно важно в случае, когда нужно обработать огромные списки и время на выполнение критично.
Однако стоит помнить, что использование множества имеет несколько ограничений: множества не сохраняют порядок элементов и не могут содержать дубли. Поэтому если порядок элементов важен, или нужно сохранить все повторяющиеся значения, такой метод не подойдёт.
- Преимущество: значительное ускорение операции для больших списков.
- Преимущество: компактность кода.
- Недостаток: потеря порядка элементов и удаление дубликатов.
Метод с set() подходит, когда важна скорость выполнения операции, а порядок и дубли элементов не играют ключевой роли.
Как избежать дублирования при вычитании списков
При вычитании одного списка из другого часто возникает проблема с дублированием элементов. Это особенно актуально, когда список содержит повторяющиеся значения, и важно сохранить только уникальные элементы в итоговом результате.
Для того чтобы избежать дублирования при вычитании списков, можно воспользоваться несколькими подходами. Один из них – это преобразование списков в множества перед вычитанием. Множества автоматически исключают дубли, но, как было сказано ранее, этот метод лишает вас порядка элементов. Если сохранение порядка важно, можно использовать другие подходы.
Пример вычитания списков с сохранением уникальности элементов с помощью set():
list1 = [1, 2, 2, 3, 4, 5] list2 = [2, 4, 4] set1 = set(list1) set2 = set(list2) result = list(set1 - set2)
В данном примере дубли из обоих списков исключаются при преобразовании в множества. Это решение быстро и эффективно, но теряется порядок элементов.
Если важно сохранить порядок и при этом избежать дублирования, можно использовать list comprehension, который проверяет наличие каждого элемента в результирующем списке:
list1 = [1, 2, 2, 3, 4, 5] list2 = [2, 4] result = [] [result.append(item) for item in list1 if item not in list2 and item not in result]
В этом примере мы вручную контролируем добавление элементов в итоговый список, исключая повторяющиеся элементы, которые уже были добавлены в результат. Такой подход сохраняет порядок и удаляет дубли, но работает медленнее, чем использование множеств, особенно для больших списков.
Ещё один способ – использовать filter() с lambda, комбинируя его с проверкой на наличие элемента в итоговом списке:
list1 = [1, 2, 2, 3, 4, 5] list2 = [2, 4] result = list(filter(lambda x: x not in list2 and x not in result, list1))
Этот метод работает аналогично, проверяя каждый элемент на уникальность и исключая его из результата, если он уже встречался. Он также сохраняет порядок элементов, но может быть менее эффективным при больших данных.
- Преимущество множеств: автоматическое исключение дубликатов, быстрое выполнение.
- Преимущество list comprehension: сохранение порядка и возможность фильтрации с проверкой на уникальность.
- Преимущество filter(): компактность кода и сохранение порядка, но сниженная производительность при большом объёме данных.
В зависимости от задачи и объёма данных можно выбрать наиболее подходящий метод, но всегда важно помнить о компромиссах между производительностью и сохранением порядка или уникальности элементов.
Вычитание списков с сохранением порядка элементов
Когда необходимо вычесть один список из другого и при этом сохранить порядок элементов, нельзя использовать множества, так как они не поддерживают порядок. Для таких случаев подойдёт метод list comprehension или использование filter() с дополнительной проверкой. Эти подходы позволяют исключить элементы из первого списка, сохраняя их порядок в итоговом результате.
Пример вычитания списков с сохранением порядка с использованием list comprehension:
list1 = [1, 2, 3, 4, 5] list2 = [2, 4] result = [item for item in list1 if item not in list2]
В этом примере мы создаём новый список, включающий все элементы из list1, за исключением тех, которые присутствуют в list2. Порядок элементов сохраняется, и дубликаты также исключаются, если они были в исходном списке.
Ещё один способ – использование функции filter() в сочетании с lambda. Этот метод также позволяет сохранить порядок элементов:
list1 = [1, 2, 3, 4, 5] list2 = [2, 4] result = list(filter(lambda x: x not in list2, list1))
Этот подход работает аналогично, но имеет преимущество в компактности кода. Тем не менее, при работе с большими списками эффективность может снижаться, так как для каждого элемента проверяется его наличие в list2.
Для сохранения порядка элементов и исключения дубликатов можно добавить проверку на уникальность элементов прямо в процесс формирования нового списка:
list1 = [1, 2, 2, 3, 4, 5] list2 = [2, 4] result = [] [result.append(item) for item in list1 if item not in list2 and item not in result]
Здесь, помимо вычитания элементов из list2, мы также исключаем повторяющиеся элементы, добавляя их в результат только если они ещё не встречались. Этот метод сохраняет порядок элементов и гарантирует уникальность значений в итоговом списке, но его производительность может снизиться для больших данных из-за повторных проверок на уникальность.
- Преимущество list comprehension: сохранение порядка и гибкость в фильтрации.
- Преимущество filter(): компактность и ясность кода.
- Недостаток: возможное снижение производительности при больших списках, особенно если требуется проверка на уникальность.
Если важно сохранить порядок и уникальность элементов при вычитании списков, использование list comprehension с дополнительной проверкой уникальности будет оптимальным решением, однако для больших данных стоит учитывать производительность.