Содержание статьи

Ссылка в объекте метаданных – это не абстрактное поле, а конкретный технический элемент, от которого зависит навигация, связность данных и корректная интеграция систем. В реальных проектах ссылки извлекают из HTML-метатегов, JSON-LD, Open Graph, HTTP-заголовков API или свойств файлов (EXIF, XMP). Каждый источник использует собственную структуру и формат, поэтому универсального способа получения ссылки не существует.
На практике чаще всего приходится работать с атрибутами content, href и ключами вроде url, @id или sameAs. Например, в JSON-LD ссылка может быть скрыта в массиве объектов, а в Open Graph – представлена как канонический URL страницы. Ошибка в выборе поля или неправильная интерпретация формата приводит к дублированию ссылок, потере связей между объектами или некорректной индексации.
Отдельного внимания требуют метаданные, получаемые из API и файлов. В API ссылка часто передаётся в служебных секциях ответа (links, _embedded), а в файлах – хранится в XMP-пакетах или пользовательских тегах. Для корректного извлечения необходимо заранее определить стандарт метаданных, кодировку и способ доступа, иначе данные будут считаны частично или искажены.
Эта статья сосредоточена на прикладных способах получения ссылки из разных типов объектов метаданных с учётом их структуры, ограничений и типичных ошибок. Все рекомендации ориентированы на практическое использование в разработке, SEO, парсинге и интеграции данных.
Определение типа объекта метаданных и формата хранения ссылки
Первый шаг – точно установить, с каким объектом метаданных ведётся работа: HTML-документ, структурированные данные, API-ответ или файл с встроенными свойствами. Тип объекта напрямую определяет, где именно может храниться ссылка и каким способом к ней получить доступ. Например, в HTML ссылка чаще всего находится в метатегах link и meta, а в структурированных данных – в виде значений ключей.
Для веб-страниц необходимо проверить наличие стандартов Open Graph, Twitter Cards и JSON-LD. В Open Graph ссылка обычно хранится в поле og:url, в Twitter Cards – в twitter:url, а в JSON-LD – в атрибутах url или @id. Формат значения всегда строковый, но может быть абсолютным, относительным или частью массива, что влияет на способ обработки.
При работе с API важно определить, передаётся ли ссылка как бизнес-данные или как элемент навигации. В REST-API ссылки часто находятся в секциях links, _links или _embedded, а в GraphQL – внутри вложенных объектов, формируемых схемой запроса. Неправильная интерпретация уровня вложенности приводит к извлечению неполной или служебной ссылки.
В файлах ссылки хранятся в метаданных форматов XMP, EXIF или пользовательских тегах. Для изображений это может быть поле CreatorWorkURL, для PDF – свойства документа или встроенные XMP-блоки. Перед извлечением необходимо определить стандарт метаданных и инструмент чтения, иначе доступ к ссылке будет невозможен или данные окажутся искажёнными.
Чёткое определение типа объекта и формата хранения ссылки позволяет сразу выбрать корректный метод извлечения, избежать лишнего парсинга и сократить количество ошибок при обработке метаданных.
Получение ссылки из HTML-метаданных страницы (meta, link)
HTML-метаданные располагаются внутри тега head и не участвуют напрямую в визуальном отображении страницы, но именно здесь чаще всего хранится каноническая или служебная ссылка. В первую очередь следует анализировать теги link, так как они предназначены для явного указания URL и имеют атрибут href, содержащий искомое значение.
Наиболее значимым является тег link rel=»canonical», в котором хранится основной URL страницы. Извлекать необходимо значение href без модификаций, предварительно проверив, что ссылка абсолютная. Если указан относительный путь, его требуется нормализовать на основе текущего домена и протокола.
Теги meta также могут содержать ссылки, но в менее очевидной форме. В Open Graph и других расширениях URL передаётся через атрибут content, например в meta property=»og:url». Важно учитывать, что такие теги могут дублироваться или конфликтовать между собой, поэтому приоритет следует отдавать каноническим и явно заданным значениям.
При автоматическом извлечении необходимо фильтровать теги по атрибутам rel, name и property, игнорируя служебные ссылки на иконки, стили и prefetch-ресурсы. Неправильная фильтрация приводит к извлечению нерелевантных URL, не связанных с логикой страницы.
Для надёжного результата рекомендуется проверять соответствие найденной ссылки текущему документу, отсутствие параметров отслеживания и корректный HTTP-статус. Это позволяет исключить устаревшие или технические URL, ошибочно указанные в метаданных.
Извлечение ссылки из структурированных данных JSON-LD
JSON-LD размещается в HTML-документе внутри тега script с типом application/ld+json и описывает объект в виде графа. Ссылка в таком формате не всегда хранится в одном фиксированном поле, поэтому извлечение начинается с анализа типа объекта, указанного в @type. Для разных типов используются разные ключи URL.
Наиболее распространённые поля, содержащие ссылку, – url, @id и sameAs. Ключ @id часто выполняет роль уникального идентификатора и может быть основной ссылкой на объект, даже если поле url отсутствует. Значение sameAs обычно представлено массивом и требует выбора релевантного URL по домену или назначению.
Перед извлечением необходимо убедиться, что JSON-LD не вложен в массив объектов верхнего уровня. В этом случае требуется перебор элементов и фильтрация по @type. Ошибкой является чтение первого найденного URL без проверки соответствия нужному объекту.
| Тип объекта (@type) | Ключ со ссылкой | Особенности извлечения |
|---|---|---|
| WebPage | url, @id | Обычно содержит канонический URL страницы |
| Organization | url, sameAs | sameAs может содержать несколько внешних ссылок |
| Product | url | Часто вложен в Offer или AggregateOffer |
| Article | url, mainEntityOfPage | mainEntityOfPage может быть объектом с @id |
После извлечения ссылка должна быть проверена на абсолютность и соответствие протоколу страницы. Если URL относительный или отсутствует схема, его необходимо нормализовать. Такой подход позволяет корректно использовать данные JSON-LD в поисковой оптимизации, парсинге и интеграции с внешними системами.
Чтение ссылки из Open Graph и Twitter Cards
Open Graph и Twitter Cards реализуются через теги meta и предназначены для передачи URL страницы внешним платформам. Основной источник ссылки в Open Graph – тег meta property=»og:url», в котором хранится канонический адрес ресурса. Значение всегда считывается из атрибута content и не должно интерпретироваться как относительный путь.
При извлечении ссылки из Open Graph необходимо соблюдать строгий порядок приоритета:
- сначала og:url как основной идентификатор страницы;
- затем link rel=»canonical», если og:url отсутствует;
- в последнюю очередь – текущий URL документа.
Twitter Cards используют собственные метатеги, но логика хранения ссылки аналогична. Основное поле – meta name=»twitter:url». На практике этот тег часто отсутствует, поэтому система автоматически использует значение og:url или канонический URL страницы.
При автоматической обработке метаданных следует учитывать типичные особенности:
- на странице может присутствовать несколько тегов og:url с разными значениями;
- значение ссылки может отличаться от фактического адреса из-за трекинговых параметров;
- Twitter Cards могут полностью полагаться на Open Graph без явного указания URL.
Для получения корректной ссылки рекомендуется выполнять последовательную проверку источников и нормализацию результата:
- извлечь значение og:url;
- проверить наличие схемы и домена;
- удалить UTM- и рекламные параметры при необходимости;
- сопоставить ссылку с текущим хостом страницы.
Такой алгоритм позволяет получать стабильный и воспроизводимый URL из Open Graph и Twitter Cards независимо от качества разметки страницы.
Получение ссылки из метаданных ответа API
В API ссылка чаще всего передаётся не в основном наборе данных, а в метаданных ответа, предназначенных для навигации и связывания ресурсов. В REST-архитектуре такие ссылки располагаются в секциях links, _links или в HTTP-заголовках Location и Link. Перед извлечением необходимо определить формат ответа и версию спецификации.
В JSON-ответах ссылки могут быть представлены как строки или как объекты с указанием отношения и метода. Например, в HATEOAS каждая ссылка сопровождается атрибутом rel, который определяет её назначение. Извлекать следует только ссылки с бизнес-значением, такие как self, canonical или related, игнорируя служебные переходы.
Отдельного внимания требуют API с постраничной навигацией. Ссылки на следующую и предыдущую страницу обычно передаются в метаданных ответа и не связаны напрямую с объектом. При парсинге важно не смешивать навигационные URL с основной ссылкой ресурса, чтобы избежать логических ошибок.
В GraphQL ссылки редко выделяются явно и чаще всего являются значениями полей объектов. В этом случае необходимо анализировать схему и документацию, чтобы определить, какое поле действительно представляет ссылку на сущность, а не вспомогательный идентификатор.
После извлечения ссылка должна быть проверена на полноту, актуальность версии API и соответствие среде выполнения. Использование URL из тестовой или устаревшей среды без валидации приводит к некорректным интеграциям и ошибкам при обращении к ресурсу.
Извлечение ссылки из метаданных файлов (PDF, изображений)
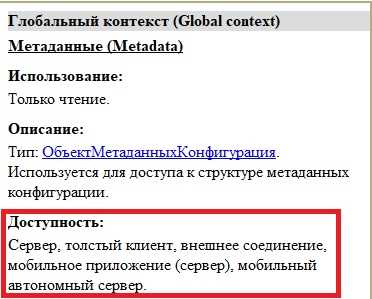
Файлы хранят ссылки в служебных метаданных, которые не отображаются при просмотре содержимого. Для изображений это в первую очередь стандарты EXIF и XMP, для PDF – свойства документа и встроенные XMP-пакеты. Перед извлечением необходимо определить, какой стандарт используется, так как поля и способы доступа различаются.
В изображениях ссылка чаще всего находится в XMP-метаданных, так как EXIF имеет ограниченный набор полей. Типичные ключи – CreatorWorkURL, WebStatement и пользовательские namespace-поля. Значение может быть закодировано в UTF-8 и содержать лишние пробелы или управляющие символы, которые требуется очистить.
В PDF-документах ссылки могут храниться в нескольких местах. Помимо явных свойств документа, URL нередко размещается в XMP-блоке как значение полей dc:source или xmp:Identifier. Ошибкой является попытка извлечения ссылки только из аннотаций или текста, игнорируя метаданные.
При автоматической обработке файлов важно учитывать, что метаданные могут отсутствовать, быть частично повреждены или перезаписаны при экспорте. Поэтому извлечённую ссылку следует проверять на валидность, абсолютность и соответствие ожидаемому домену.
Корректное чтение метаданных файлов позволяет получать источник или канонический URL ресурса без анализа содержимого, что особенно важно при работе с большими архивами и медиахранилищами.
Проверка корректности и доступности полученной ссылки
После извлечения ссылка из метаданных требует обязательной технической проверки. Наличие URL в объекте не гарантирует его пригодность для использования. Проверка должна начинаться с анализа формата и структуры адреса до выполнения сетевых запросов.
На первом этапе необходимо убедиться в синтаксической корректности ссылки:
- наличие схемы http или https;
- отсутствие пробелов, HTML-сущностей и управляющих символов;
- корректная кодировка специальных символов;
- преобразование относительных путей в абсолютные URL.
Далее выполняется проверка доступности ресурса на уровне HTTP:
- отправка запроса методом HEAD или GET;
- анализ кода ответа (200, 301, 302, 404, 410);
- фиксация цепочек редиректов и конечного URL;
- проверка соответствия домена ожидаемому источнику.
Особое внимание следует уделять редиректам. Постоянные перенаправления 301 допустимы, но множественные или циклические редиректы указывают на ошибку в метаданных. Временные коды 302 и 307 не подходят для определения канонического адреса.
На завершающем этапе рекомендуется проверить логическую релевантность ссылки:
- соответствует ли URL типу объекта метаданных;
- не содержит ли служебные или тестовые поддомены;
- не относится ли к устаревшей версии ресурса;
- не блокируется ли доступ роботами или авторизацией.
Такая последовательная проверка позволяет отсеять некорректные, временные и технические URL, обеспечивая использование только валидных и доступных ссылок.
Типовые ошибки при работе со ссылками в объектах метаданных
Часто игнорируется тип объекта метаданных. Например, ссылка из поля sameAs принимается за основной URL, хотя фактически указывает на внешний профиль или зеркальный ресурс. Аналогичная проблема возникает при использовании ссылок пагинации из API вместо ссылки на сам объект.
Неправильная обработка относительных ссылок приводит к формированию некорректных URL. Отсутствие нормализации по протоколу и домену особенно критично при работе с HTML-метаданными и JSON-LD, где относительные пути встречаются регулярно.
Ещё одна ошибка – отсутствие валидации доступности. Ссылки могут указывать на устаревшие, тестовые или закрытые ресурсы, возвращающие коды 404 или 403. Использование таких URL без проверки приводит к сбоям интеграций и ошибкам индексации.
Нередко не учитываются конфликты между источниками метаданных. Значения og:url, canonical и @id могут различаться, и выбор без установленного приоритета делает результат непредсказуемым. Для надёжной работы необходимо заранее определить правила выбора и проверки ссылки.
Вопрос-ответ:
Почему ссылка из JSON-LD и canonical на странице могут отличаться и какую из них использовать?
Различие возникает из-за ошибок разметки или разного назначения полей. В JSON-LD ссылка часто указывается как идентификатор объекта (@id), тогда как link rel=»canonical» отражает адрес HTML-документа. Если задача связана с обработкой страницы, приоритет отдаётся canonical. Если требуется идентификация сущности (товара, организации, статьи), корректнее использовать ссылку из JSON-LD при условии, что она возвращает валидный HTTP-ответ и соответствует текущему домену.
Можно ли считать og:url надёжным источником ссылки для автоматического парсинга?
og:url подходит для автоматического извлечения, если на странице нет дублирующихся значений и он совпадает с фактическим адресом ресурса. На практике og:url иногда содержит параметры отслеживания или устаревший URL. Поэтому его следует проверять на совпадение с canonical и дополнительно валидировать через HTTP-запрос.
Где искать ссылку в ответе API, если поле url отсутствует?
В таких случаях необходимо проверить метаданные ответа. В REST-API ссылка часто находится в секциях links или _links с отношением self. Также стоит анализировать HTTP-заголовки, особенно Location и Link. Если используется GraphQL, ссылка может быть вложена в объект и определяться схемой, а не именем поля.
Почему из метаданных файла не удаётся извлечь ссылку, хотя она есть в описании?
Описание файла и его метаданные — разные уровни данных. Ссылка может присутствовать в тексте документа, но отсутствовать в XMP или EXIF. Также метаданные часто удаляются при экспорте или сжатии. Для получения ссылки необходимо убедиться, что она записана именно в метаданные и что используемый инструмент поддерживает нужный стандарт.