Содержание статьи

При обучении нейронных сетей ключевым ограничением становятся вычислительные ресурсы и объём данных. Использование всей обучающей выборки за один шаг требует значительного объёма памяти и увеличивает время обновления весов. Мини батч обучение решает эту задачу за счёт разбиения датасета на небольшие фрагменты фиксированного размера, которые последовательно подаются в модель. На практике чаще всего применяются размеры мини батчей от 16 до 512 объектов, в зависимости от архитектуры сети и доступной видеопамяти.
Каждый мини батч используется для вычисления градиентов и обновления параметров модели, что позволяет находить компромисс между шумными обновлениями при поэлементном обучении и высокими требованиями к ресурсам при полном пакетном подходе. Такой режим особенно востребован при работе с глубокими сверточными и трансформерными моделями, где даже один проход по всей выборке может занимать минуты или часы.
Мини батч обучение напрямую влияет на динамику сходимости: малый размер батча увеличивает разброс градиентов и может помочь выйти из локальных минимумов, тогда как крупные батчи обеспечивают более предсказуемое направление обновления весов. На практике рекомендуется начинать с размера, кратного степени двойки (например, 32 или 64), и корректировать его в зависимости от скорости обучения, загрузки GPU и поведения функции потерь.
Понимание принципов мини батч обучения позволяет осознанно настраивать процесс тренировки нейронных сетей, избегать лишних затрат памяти и добиваться устойчивого обучения даже на больших и неоднородных наборах данных.
Мини-батч обучение нейронных сетей: что это и как применяется
На практике мини-батч формируется случайным образом из датасета и имеет фиксированный размер. В задачах компьютерного зрения и обработки текста чаще всего используются значения от 32 до 256 примеров. Размер подбирается с учётом объёма видеопамяти, сложности модели и времени одного шага обучения. При работе на GPU мини-батчи позволяют задействовать параллельные вычисления, снижая простой вычислительных блоков.
Мини-батч обучение применяется во всех популярных фреймворках глубокого обучения. В PyTorch и TensorFlow данный режим используется по умолчанию, так как он обеспечивает стабильное обновление весов без необходимости загружать весь датасет в память. В задачах с миллионами объектов это является единственным практичным вариантом обучения.
| Подход | Размер обрабатываемых данных | Частота обновления весов |
|---|---|---|
| Поэлементное обучение | 1 объект | После каждого примера |
| Мини-батч обучение | 16–512 объектов | Несколько раз за эпоху |
| Пакетное обучение | Вся выборка | 1 раз за эпоху |
Мини-батчи особенно полезны при обучении глубоких сетей с большим числом параметров. Они позволяют контролировать баланс между скоростью одного шага, стабильностью градиентов и требованиями к памяти, что делает данный подход стандартом для большинства прикладных задач машинного обучения.
Что такое мини-батч и как он формируется из обучающей выборки
Формирование мини-батчей начинается с подготовки обучающей выборки. Данные приводятся к единому формату, нормализуются и сохраняются в структуре, допускающей быстрый доступ к отдельным объектам. После этого выборка разбивается на группы одинакового размера, за исключением последнего батча, который может содержать меньше элементов.
- Перемешивание данных перед началом каждой эпохи для снижения корреляции между примерами
- Фиксация размера мини-батча, кратного 2, для оптимальной загрузки GPU
- Исключение неполных батчей при необходимости строгой размерности входных тензоров
Размер мини-батча напрямую влияет на количество обновлений весов за эпоху. Например, при выборке из 10 000 объектов и размере батча 100 модель выполнит 100 шагов обновления. Уменьшение размера батча увеличивает число итераций, что может изменить траекторию обучения.
- Загрузка индексов объектов из обучающей выборки
- Формирование последовательных или случайных групп заданного размера
- Подача каждого мини-батча в модель для прямого и обратного прохода
На практике рекомендуется начинать с размера мини-батча, который полностью помещается в память устройства, а затем корректировать его с учётом времени одной итерации и поведения функции потерь в процессе обучения.
Чем мини-батч отличается от пакетного и поэлементного обучения
Способ разбиения обучающей выборки определяет, как часто нейронная сеть обновляет свои параметры и какие ресурсы потребляет в процессе обучения. Мини-батч обучение занимает промежуточное положение между поэлементным и пакетным подходами, сочетая особенности обоих режимов.
При поэлементном обучении модель обрабатывает один объект за шаг. Обновление весов происходит после каждого примера, что приводит к высокой вариативности градиентов и увеличивает число итераций. Такой режим может быть полезен при крайне ограниченной памяти, но плохо масштабируется на большие датасеты.
- 1 объект на шаг обучения
- Максимальное количество обновлений весов за эпоху
- Высокая чувствительность к шуму в данных
Пакетное обучение использует всю обучающую выборку целиком. Градиенты вычисляются один раз за эпоху, что требует значительных объёмов памяти и делает шаг обучения длительным. При росте размера датасета данный подход становится практически неприменимым.
- Вся выборка обрабатывается за один шаг
- Минимальное число обновлений весов
- Сильная зависимость от объёма оперативной памяти
Мини-батч обучение делит данные на группы фиксированного размера и выполняет обновление весов несколько раз за эпоху. Это снижает требования к памяти по сравнению с пакетным подходом и уменьшает разброс градиентов по сравнению с поэлементным режимом.
- Обработка 16–512 объектов за шаг
- Баланс между числом итераций и затратами ресурсов
- Возможность параллельных вычислений на GPU
На практике мини-батчи используются по умолчанию в большинстве фреймворков, так как они позволяют контролировать нагрузку на оборудование и предсказуемо управлять процессом обучения нейронных сетей.
Как размер мини-батча влияет на обновление весов модели
Размер мини-батча определяет, сколько обучающих примеров участвует в расчёте градиента на одном шаге обучения. При использовании малого батча градиент формируется на ограниченном наборе данных, из-за чего направление обновления весов может заметно колебаться между итерациями. Это приводит к более частым изменениям параметров модели в пределах одной эпохи.
Увеличение размера мини-батча снижает разброс градиентов, так как усреднение происходит по большему числу примеров. В результате шаг обновления весов становится более предсказуемым, но сами обновления выполняются реже. Например, при размере батча 256 и выборке из 25 600 объектов модель обновит параметры всего 100 раз за эпоху.
Размер батча напрямую связан со значением шага обучения. При переходе к более крупным мини-батчам часто требуется уменьшать learning rate, чтобы избежать резких скачков функции потерь. На практике распространён подход пропорционального масштабирования, при котором увеличение батча в 2 раза сопровождается снижением шага обучения.
Малые мини-батчи (16–32 объекта) позволяют быстрее реагировать на изменения в данных, но увеличивают нагрузку на оптимизатор и могут замедлять обучение из-за большого числа итераций. Крупные батчи (128–512 объектов) снижают количество обновлений весов, однако требуют больше видеопамяти и могут приводить к менее гибкой адаптации параметров модели.
Оптимальный размер мини-батча подбирается экспериментально с учётом архитектуры сети, объёма данных и характеристик оборудования. В большинстве практических задач начальным ориентиром служит значение, которое полностью заполняет память GPU без перехода к выгрузке данных в оперативную память.
Связь мини-батчей с алгоритмами градиентного спуска
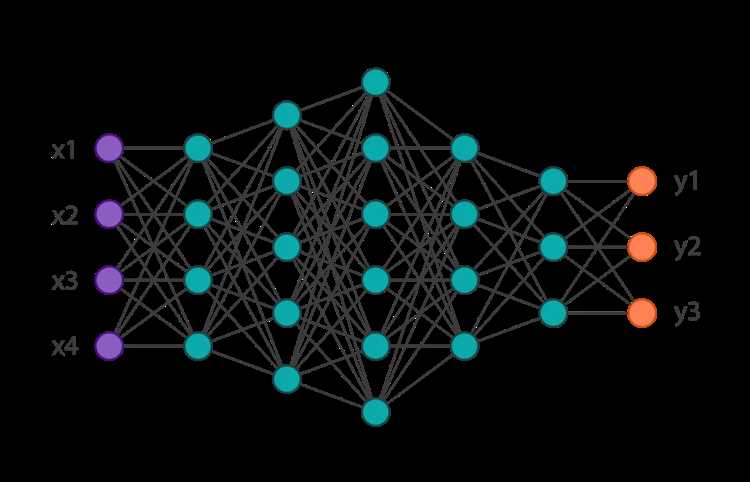
Мини-батчи напрямую определяют, каким образом алгоритм градиентного спуска оценивает направление изменения весов модели. Вместо вычисления градиента по всей обучающей выборке используется приближение, рассчитанное на ограниченном наборе примеров. Такое приближение применяется в стохастическом и мини-батч вариантах градиентного спуска.
Классический градиентный спуск использует всю выборку для одного шага обновления параметров, что делает вычисление градиента точным, но крайне затратным по времени и памяти. Мини-батч подход снижает вычислительную нагрузку, позволяя выполнять десятки или сотни шагов обновления в рамках одной эпохи.
Большинство современных оптимизаторов, включая Adam, RMSprop и Adagrad, рассчитаны именно на работу с мини-батчами. Они накапливают статистику градиентов между итерациями и корректируют шаг обучения с учётом текущего мини-батча. Размер батча влияет на то, насколько быстро обновляются эти внутренние параметры оптимизатора.
При малых мини-батчах градиенты обладают большей вариативностью, что увеличивает роль адаптивных методов оптимизации. В таких условиях оптимизаторы с накоплением моментов чаще показывают стабильную динамику снижения функции потерь. Крупные батчи, напротив, приближают поведение алгоритма к классическому градиентному спуску.
На практике рекомендуется подбирать размер мини-батча совместно с выбором оптимизатора и шагом обучения. Например, при использовании Adam чаще применяются батчи 32–128 объектов, тогда как при SGD без моментов целесообразно начинать с меньших значений и постепенно увеличивать их по мере стабилизации обучения.
Как выбирать размер мини-батча под задачу и объём данных
Размер мини-батча определяется одновременно требованиями к вычислительным ресурсам и спецификой задачи. Для моделей с большим числом параметров и ограниченной видеопамятью оптимальный размер обычно составляет 32–128 объектов. Это позволяет проводить достаточное количество обновлений весов за эпоху и сохранять вариативность градиентов для устойчивого обучения.
В задачах с огромными датасетами, например, с миллионами изображений или текстовых последовательностей, целесообразно увеличивать размер мини-батча до 256–512 объектов. Это снижает количество итераций за эпоху и уменьшает суммарное время обучения, при условии, что оборудование справляется с нагрузкой.
Малые батчи подходят для тонкой настройки весов в начале обучения или при нестабильной функции потерь. Они создают шумные градиенты, что помогает выходить из локальных минимумов. Крупные батчи обеспечивают более стабильное направление градиента, но могут замедлять адаптацию модели к новым паттернам в данных.
При выборе размера мини-батча рекомендуется ориентироваться на следующие критерии:
- Объём видеопамяти и доступная оперативная память
- Сложность архитектуры и количество параметров модели
- Длительность одного шага обучения и допустимое время эпохи
- Чувствительность модели к шуму градиентов
Оптимальный размер обычно подбирается экспериментально: начинают с значения, полностью помещающегося в память, а затем корректируют с учётом скорости сходимости, стабильности функции потерь и качества финальной модели.
Влияние мини-батчей на стабильность обучения нейросети
Размер мини-батча напрямую влияет на вариативность градиентов и, как следствие, на стабильность процесса обучения. Малые батчи создают шумные оценки градиентов, что приводит к колебаниям функции потерь между итерациями. Это может ускорять выход из локальных минимумов, но увеличивает риск нестабильного или медленного сходимости.
Крупные мини-батчи обеспечивают усреднённые градиенты, благодаря чему обновления весов становятся более предсказуемыми. Функция потерь изменяется плавнее, уменьшается риск перепрыгивания через минимумы. Однако слишком большие батчи могут замедлить адаптацию модели к новым паттернам и увеличивают требования к памяти.
На практике оптимальный размер мини-батча выбирается с учётом компромисса между шумностью градиентов и стабильностью обучения. Для глубоких сверточных сетей часто используют батчи 64–128 объектов, что позволяет сочетать плавность обновлений и достаточную вариативность для эффективного поиска оптимума.
Также важен баланс с шагом обучения. Малые батчи требуют уменьшения learning rate, чтобы избежать резких колебаний весов, а большие – постепенного увеличения для ускорения сходимости. Регулярная проверка функции потерь на валидационной выборке помогает корректировать размер батча и шаг обучения в процессе тренировки.
Использование мини-батчей при обучении на GPU и CPU
Мини-батчи позволяют оптимально использовать вычислительные ресурсы как на GPU, так и на CPU. На GPU параллельная обработка тензоров работает быстрее при размере батча, кратном степени двойки, например 32, 64 или 128 объектов. Это обеспечивает полную загрузку блоков CUDA и снижает простой вычислительных ядер.
На CPU производительность зависит от количества потоков и доступной оперативной памяти. Малые батчи (16–32 объекта) позволяют использовать многопоточность без перегрузки памяти, тогда как большие батчи могут потребовать распределённого вычисления или частичной загрузки данных с диска.
При обучении на GPU размер мини-батча влияет на скорость одного шага и частоту обновлений весов. Оптимальный батч должен максимально использовать видеопамять без её переполнения. Например, при видеопамяти 16 ГБ для модели ResNet-50 целесообразно использовать батчи 64–128 изображений размером 224×224 пикселя.
На CPU рекомендуется использовать динамическое формирование мини-батчей, чтобы подстраиваться под объём оперативной памяти и нагрузку процессора. Малые батчи позволяют чаще обновлять веса и ускоряют сходимость на небольших датасетах, тогда как крупные батчи повышают эффективность при обработке больших массивов данных.
Для гибридных систем часто применяют комбинированный подход: формируют мини-батчи с учётом загрузки GPU и CPU одновременно, распределяя вычисления так, чтобы избежать простоя одного из ресурсов и ускорить общий процесс обучения.
Типичные ошибки при работе с мини-батч обучением
Слишком маленькие мини-батчи также создают проблемы: высокочастотные шумные градиенты могут вызвать нестабильность функции потерь и замедлить сходимость модели. Часто это сопровождается необходимостью снижать шаг обучения, что увеличивает время тренировки.
Ещё одна ошибка – отсутствие перемешивания данных перед формированием мини-батчей. Это приводит к последовательной подаче однотипных примеров, из-за чего градиенты оказываются коррелированными, а модель хуже обучается на разнообразных паттернах.
Некорректная обработка последнего неполного батча может вызвать ошибки при вычислении градиентов или нарушить форму тензоров. Важно предусматривать обработку батчей с меньшим количеством объектов или отбрасывать их при строгих требованиях к размерности входа.
Неправильная комбинация размера мини-батча и шага обучения также снижает эффективность тренировки. При увеличении батча необходимо корректировать learning rate, иначе модель может застревать в локальных минимумах или показывать медленное уменьшение функции потерь.
Регулярная проверка поведения функции потерь и динамики градиентов позволяет выявлять и корректировать ошибки на ранних этапах обучения, обеспечивая стабильную и предсказуемую работу модели.
Вопрос-ответ:
Почему размер мини-батча влияет на скорость обучения нейросети?
Размер мини-батча определяет, сколько примеров используется для расчёта градиента на одном шаге. Малый батч генерирует более шумные градиенты, что увеличивает число обновлений весов за эпоху, но может замедлять сходимость из-за колебаний функции потерь. Большой батч снижает вариативность градиентов, делая обновления более предсказуемыми, но уменьшает количество шагов и требует больше памяти. Оптимальный размер подбирается с учётом архитектуры модели и доступного оборудования.
Как формируется мини-батч из обучающей выборки?
Мини-батч формируется путём случайного выбора группы объектов из всей обучающей выборки. Обычно данные перемешиваются перед каждой эпохой, чтобы исключить корреляцию между последовательными батчами. Размер группы фиксируется заранее, а последний неполный батч может быть меньше, что учитывается в реализации. Такой подход позволяет модели чаще обновлять параметры и снижает нагрузку на память по сравнению с обработкой всей выборки за один шаг.
В чём разница между мини-батч, поэлементным и пакетным обучением?
Поэлементное обучение обрабатывает один объект за шаг, обновляя веса после каждого примера. Это создаёт высокочастотные колебания градиентов, но требует меньше памяти. Пакетное обучение использует всю выборку для одного обновления, что обеспечивает точный градиент, но сильно нагружает память и замедляет шаги. Мини-батч обучение объединяет эти подходы: группа объектов среднего размера используется для расчёта градиента, что позволяет балансировать между частотой обновлений и потреблением ресурсов.
Какие ошибки чаще всего допускают при работе с мини-батчами?
Частые ошибки включают выбор слишком большого батча, превышающего доступную память, что вызывает сбои, и слишком маленького, что создаёт шумные градиенты и нестабильную функцию потерь. Также часто забывают перемешивать данные перед формированием батчей, что ухудшает обучение, или некорректно обрабатывают последний неполный батч, нарушая форму тензоров. Ещё одна ошибка — несогласованность размера батча и шага обучения, из-за чего модель может застревать или медленно снижать функцию потерь.