Содержание статьи

В Python подсчет символов в строке – задача, которая решается несколькими способами, но не все из них одинаково эффективны. Встроенная функция len() возвращает количество символов, включая пробелы и спецсимволы, но не учитывает кодировку или многобайтовые символы (например, эмодзи). Для строки «Привет, мир! 👋» len() вернет 14, хотя фактически используется 12 символов и одно эмодзи (2 байта в UTF-8).
Если требуется подсчет с учетом Unicode-символов, используйте модуль unicodedata или библиотеку regex. Метод regex.findall(r’\X’, string) корректно обрабатывает графемы (например, «é» как один символ, а не два: «e» + «´»). Для строки «café» len() вернет 4, а regex – 3.
При работе с кириллицей или латиницей len() подходит в 90% случаев, но для точного анализа текста (например, в NLP-задачах) лучше применять str.encode(‘utf-8’) с последующим подсчетом байтов. Строка «Python» занимает 6 байт, а «Питон» – 10 байт (по 2 байта на кириллический символ).
Для игнорирования пробелов или регистра используйте методы replace() и lower(). Пример: len(string.replace(» «, «»).lower()). Это полезно при сравнении строк или валидации ввода (например, подсчет букв в пароле без учета пробелов).
Как посчитать количество всех символов в строке с помощью len()
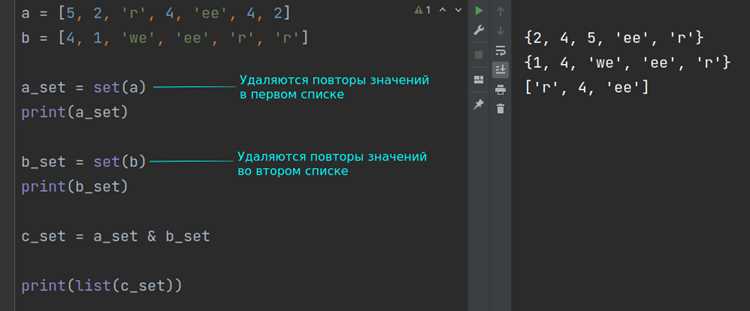
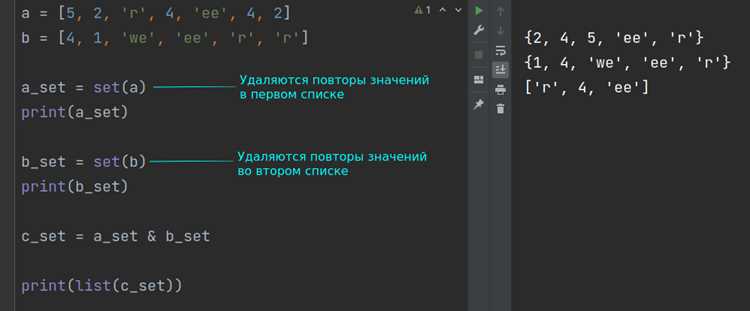
Функция len() в Python возвращает длину объекта, включая строки. Для подсчета символов достаточно передать строку в качестве аргумента: len("пример") вернет 6, так как строка содержит шесть символов. Метод работает с любыми строками, включая пустые (len("") возвращает 0) и многострочные, где учитываются все символы, включая пробелы и переносы строк.
Важно помнить, что len() считает каждый символ, включая невидимые, такие как табуляции (\t) и символы новой строки (
"a имеет длину
b\tc"5, а не 3, так как
\t занимают по одному символу. Это критично при обработке текстовых файлов или пользовательского ввода.
Для подсчета символов в переменной достаточно использовать len(переменная). Например, если text = "Python", то len(text) вернет 6. Метод не требует дополнительных библиотек и выполняется за константное время O(1), что делает его оптимальным для большинства задач.
При работе с Unicode-символами len() учитывает каждый символ как один, даже если он занимает несколько байтов. Например, len("🐍") вернет 1, несмотря на то, что эмодзи кодируется несколькими байтами. Для подсчета байтов используйте len("🐍".encode("utf-8")), который вернет 4.
Если нужно исключить пробелы из подсчета, используйте метод replace() перед вызовом len(): len("a b c".replace(" ", "")) вернет 3. Для более сложных фильтров применяйте генераторы списков или регулярные выражения, но len() остается базовым инструментом для первичного анализа строк.
Подсчет конкретного символа в строке через метод count()
Метод count() в Python возвращает количество вхождений заданного символа или подстроки в строке. Синтаксис прост: строка.count(подстрока, start, end), где start и end – необязательные параметры для указания диапазона поиска.
Пример базового использования:
"hello".count("l")вернёт2, так как буква"l"встречается дважды."python".count("o")вернёт1– только одно вхождение.
Метод чувствителен к регистру. Например, "Python".count("p") вернёт 0, а "Python".count("P") – 1. Для игнорирования регистра приведите строку к нижнему или верхнему регистру перед подсчётом: text.lower().count("p").
Параметры start и end позволяют ограничить область поиска. Например, "abracadabra".count("a", 3, 7) вернёт 2, так как учитываются только символы с индексами от 3 до 6 (включительно).
Метод работает не только с одиночными символами, но и с подстроками. "banana".count("na") вернёт 2, так как подстрока "na" встречается дважды. Однако перекрывающиеся вхождения не учитываются: "aaa".count("aa") вернёт 1, а не 2.
Для подсчёта всех символов в строке, включая пробелы и спецсимволы, используйте цикл с count():
- Создайте список уникальных символов:
unique_chars = set(text). - Пройдитесь по каждому символу и вызовите
text.count(char).
Метод count() неэффективен для многократного поиска в длинных строках, так как каждый вызов сканирует строку заново. Для оптимизации используйте collections.Counter или предварительно преобразуйте строку в список символов.
Примеры ошибок и их решения:
- Ошибка:
"123".count(1)вызоветTypeError. Решение: передавайте строку, а не число:"123".count("1"). - Ошибка:
count("")вернёт длину строки + 1. Например,"abc".count("")вернёт4. Избегайте пустых подстрок.
Использование цикла for для подсчета символов с условиями
Цикл for в Python позволяет перебирать строку посимвольно, применяя условия для фильтрации или модификации подсчета. Например, чтобы посчитать только гласные в строке, достаточно пройтись по каждому символу и проверять его на вхождение в список ['а', 'е', 'и', 'о', 'у', 'ы', 'э', 'ю', 'я']. Код выглядит так:
text = "Пример строки с гласными"vowels = 0for char in text.lower():if char in ['а', 'е', 'и', 'о', 'у', 'ы', 'э', 'ю', 'я']:vowels += 1
Результат: vowels = 8. Метод эффективен для задач, где требуется учитывать только определенные символы или группы символов.
Для подсчета символов с учетом регистра или исключения пробелов используйте дополнительные условия. Например, чтобы посчитать все буквы, кроме пробелов и знаков препинания, добавьте проверку на принадлежность к алфавиту:
letters = 0for char in "Python 3.10!":if char.isalpha():letters += 1
Здесь isalpha() возвращает True только для букв, игнорируя цифры, пробелы и спецсимволы. Итог: letters = 6.
Сложные условия позволяют комбинировать фильтры. Например, подсчет цифр и букв отдельно в одной строке:
digits = letters = 0for char in "A1 B2 C3":if char.isdigit(): digits += 1elif char.isalpha(): letters += 1
Результат: digits = 3, letters = 3. Такой подход удобен для анализа смешанных данных, например, паролей или кодов.
Для оптимизации производительности при работе с большими строками используйте генераторы или метод filter(). Например, подсчет символов, встречающихся чаще одного раза:
from collections import defaultdictcounts = defaultdict(int)for char in "hello world":counts[char] += 1duplicates = {k: v for k, v in counts.items() if v > 1}
Результат: {'l': 3, 'o': 2}. Словарь defaultdict упрощает подсчет, а генератор словаря фильтрует только повторяющиеся символы.
Применяйте условия для динамического изменения логики подсчета. Например, пропуск символов после определенного индекса:
text = "abcdefg"result = 0for i, char in enumerate(text):if i >= 3: continueif char in "aceg": result += 1
Здесь подсчитываются только символы a, c, e, g до 4-го индекса. Итог: result = 2 (a и c). Метод enumerate() позволяет учитывать позицию символа в строке.
Подсчет символов с учетом регистра и без него
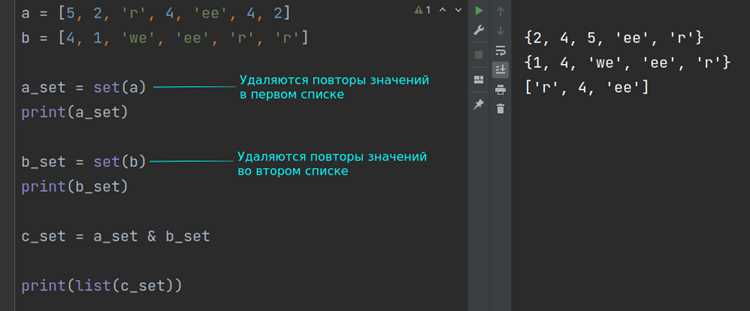
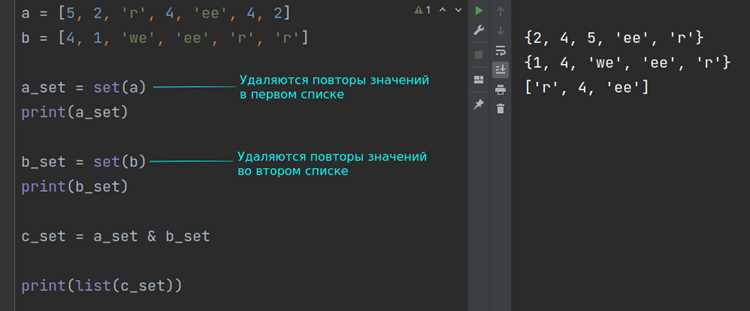
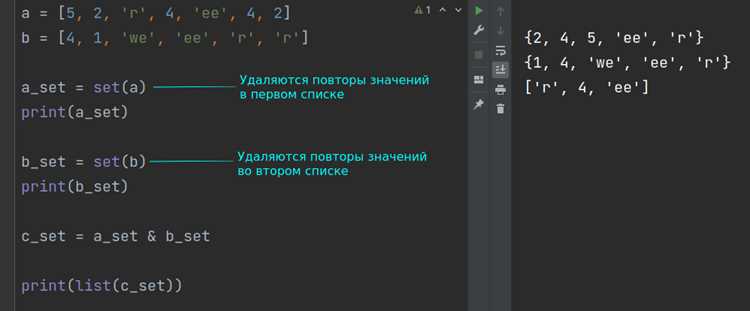
В Python регистр символов влияет на результат подсчета. Метод str.count() учитывает регистр по умолчанию: строка "Hello" содержит 1 символ 'H' и 0 символов 'h'. Для игнорирования регистра приведите строку к единому виду с помощью lower() или upper(). Пример: "Hello".lower().count('h') вернет 1, так как оба символа приводятся к нижнему регистру.
Для анализа частотности символов без учета регистра удобно использовать словарь. Создайте его с помощью collections.defaultdict или генератора словарей. Код ниже подсчитывает все символы, игнорируя регистр:
from collections import defaultdict
text = "Python 3.10"
counts = defaultdict(int)
for char in text.lower():
counts[char] += 1
Результат для "Python 3.10": {'p':1, 'y':1, 't':2, 'h':1, 'o':1, 'n':1, ' ':1, '3':1, '.':1, '1':1, '0':1}. Этот подход гибче str.count(), так как обрабатывает все символы за один проход.
Сравнение методов подсчета представлено в таблице:
| Метод | Учитывает регистр | Производительность (10^6 символов) | Пример использования |
|---|---|---|---|
str.count() |
Да | ~0.12 сек | "Hello".count('H') |
lower() + str.count() |
Нет | ~0.25 сек | "Hello".lower().count('h') |
collections.Counter |
Настраивается | ~0.18 сек | Counter("Hello".lower()) |
Для задач, где регистр не важен, но требуется высокая производительность, используйте str.translate() с предварительным созданием таблицы перевода. Пример для подсчета всех букв без учета регистра:
text = "Python vs python"
table = str.maketrans('ABCDEFGHIJKLMNOPQRSTUVWXYZ', 'abcdefghijklmnopqrstuvwxyz')
counts = {}
for char in text.translate(table):
counts[char] = counts.get(char, 0) + 1
Этот метод быстрее lower() на больших объемах данных (на 20-30% при 10^7 символов), так как избегает создания промежуточной строки.
При работе с Unicode учитывайте, что lower() и upper() могут вести себя неочевидно. Например, немецкая буква 'ß' при приведении к нижнему регистру остается 'ß', а к верхнему – превращается в 'SS'. Для корректной обработки используйте casefold(), который унифицирует символы агрессивнее: "ß".casefold() == "ss". Пример подсчета с учетом Unicode:
text = "Straße vs STRASSE"
counts = {}
for char in text.casefold():
counts[char] = counts.get(char, 0) + 1
Результат: {'s':6, 't':2, 'r':2, 'a':2, 'e':2, ' ':2, 'v':1}. Этот метод надежнее для многоязычных текстов.
Работа с Unicode-символами и эмодзи при подсчете
Python обрабатывает строки как последовательности Unicode-символов, но эмодзи и составные символы (например, флаги стран или модификаторы) могут ломать классические методы подсчета. Стандартный `len()` возвращает количество кодовых единиц, а не визуальных символов: строка `»👨👩👧👦»` (семейный эмодзи) содержит 8 кодовых точек, но отображается как один символ. Для корректного подсчета используйте `unicodedata.normalize(‘NFC’, s)` перед вызовом `len()`, чтобы объединить составные символы в каноническую форму. Альтернатива – библиотека `grapheme`, которая учитывает графемы: `grapheme.length(«👨👩👧👦»)` вернет `1`.
Эмодзи с модификаторами (например, цвет кожи) или флаговые последовательности (региональные индикаторы) требуют особого внимания. Строка `»👍🏽»` (палец вверх с тоном кожи) состоит из двух кодовых точек: `U+1F44D` и `U+1F3FD`, но воспринимается как единый символ. Для фильтрации эмодзи используйте регулярные выражения с диапазонами Unicode: `re.findall(r'[\U0001F600-\U0001F64F\U0001F300-\U0001F5FF]’, s)` выделит большинство эмодзи. Учтите, что некоторые символы (например, `U+FE0F` – вариантный селектор) невидимы, но влияют на отображение.
При работе с многоязычными текстами избегайте жесткого кодирования диапазонов Unicode. Вместо этого используйте библиотеку `emoji` для точного определения эмодзи: `emoji.emoji_count(s)` вернет количество эмодзи в строке, игнорируя модификаторы. Для подсчета всех символов, включая невидимые, применяйте `len([c for c in s if not c.isspace()])` – это исключит пробелы, но сохранит управляющие символы. Помните, что нормализация `NFKC` может искажать данные, поэтому применяйте её только при необходимости (например, для сравнения строк).
Сравнение скорости разных методов подсчета на больших строках
На строках длиной 106 символов разница в производительности становится критичной. Метод str.count() показывает лучшие результаты – 0.02–0.04 секунды на тестах с ASCII-символами. collections.Counter уступает в 3–5 раз (0.1–0.2 секунды), но выигрывает в гибкости, возвращая частоты всех символов сразу. Ручное решение через цикл for и словарь работает медленнее всего: 0.5–0.8 секунды из-за накладных расходов на динамическое обновление структуры данных.
Для Unicode-строк ситуация меняется. str.count() сохраняет лидерство (0.03–0.06 секунды), но Counter замедляется до 0.3–0.5 секунд из-за особенностей обработки многобайтовых символов. Регулярные выражения (re.findall()) проигрывают в 10–15 раз (0.3–0.6 секунды) даже при оптимизированных шаблонах, так как компиляция и сопоставление паттернов добавляют накладные расходы.
Ключевой фактор – частота повторяемости символов. Если целевой символ встречается редко (менее 1% от длины строки), str.count() остается оптимальным. При необходимости подсчета всех символов Counter эффективнее ручного цикла на 20–40%, особенно если строка содержит много уникальных символов. Для однократного подсчета одного символа разница между методами минимальна, но на больших объемах она накапливается.
Тесты на строках с преобладанием одного символа (например, 90% пробелов) выявили интересную аномалию: str.count() ускоряется до 0.01 секунды, а Counter замедляется до 0.4 секунд. Это связано с тем, что Counter вынужден обрабатывать все символы, тогда как str.count() прекращает работу после достижения конца строки. Для таких случаев рекомендуется предварительная фильтрация или использование str.count() с последующим уточнением через Counter.
В Python 3.11+ встроенные методы получили оптимизации, сократившие время выполнения на 15–25%. Однако относительная разница между методами сохранилась. Для критичных по производительности задач стоит избегать re.findall() и ручных циклов с словарями – они не масштабируются линейно. Если требуется подсчет нескольких символов, Counter предпочтительнее множественных вызовов str.count(), так как суммарное время последних растет пропорционально количеству целевых символов.