Содержание статьи

Python по умолчанию выполняет код в одном потоке, что ограничивает использование многоядерных процессоров. На современных системах с 4, 8 и более ядрами это может приводить к простою ресурсов при обработке задач, требующих значительных вычислений, таких как обработка больших массивов данных, моделирование или сложные алгоритмы анализа.
Для распределения нагрузки между ядрами применяется модуль multiprocessing, который создает независимые процессы, обходящие ограничения глобальной блокировки интерпретатора (GIL). В отличие от потоков, каждый процесс работает в отдельной памяти, что увеличивает скорость выполнения параллельных вычислений.
Использование пулов процессов позволяет задавать фиксированное количество параллельных задач, контролировать загрузку системы и обмениваться результатами через очереди и пайпы. Это особенно важно при работе с большими данными, где чрезмерное создание процессов может привести к падению производительности.
Библиотеки concurrent.futures и joblib предоставляют упрощенные интерфейсы для распараллеливания функций и итераций по коллекциям. concurrent.futures.ProcessPoolExecutor подходит для независимых функций, а joblib.Parallel эффективен при повторяющихся вычислениях с массивами данных.
Практика показывает, что оптимальное использование нескольких ядер достигается при комбинировании управления процессами, минимизации межпроцессного обмена данными и измерении времени выполнения. Это позволяет сократить время обработки на 50–80% в задачах, требующих интенсивных вычислений, без снижения стабильности работы Python-приложений.
Почему Python по умолчанию использует одно ядро

Python использует глобальную блокировку интерпретатора (GIL), которая ограничивает выполнение байткода одним потоком одновременно. Это решение облегчает управление памятью и предотвращает гонки данных при работе с объектами CPython, но блокирует параллельное использование нескольких ядер для вычислительно тяжелых задач.
Основные последствия GIL:
- Процессорная нагрузка в многопоточных приложениях часто не превышает 25–50% на 4-ядерных системах.
- Использование потоков для параллельных вычислений не ускоряет выполнение, а может привести к дополнительным задержкам из-за переключения контекста.
Рекомендации для обхода ограничений:
- Применять multiprocessing для создания независимых процессов, которые работают на разных ядрах без ограничений GIL.
- Для математических и числовых задач использовать библиотеки с внутренними реализациями на C, поддерживающими многопоточность (NumPy, SciPy), где GIL освобождается во время выполнения вычислений.
- Оценивать задачи на CPU- или IO-зависимость и выбирать соответствующий инструмент параллелизации.
Понимание причин однопоточности Python помогает правильно проектировать приложения, чтобы максимально использовать все ядра процессора и избежать потерь производительности на вычислительных задачах.
Разница между потоками и процессами в Python
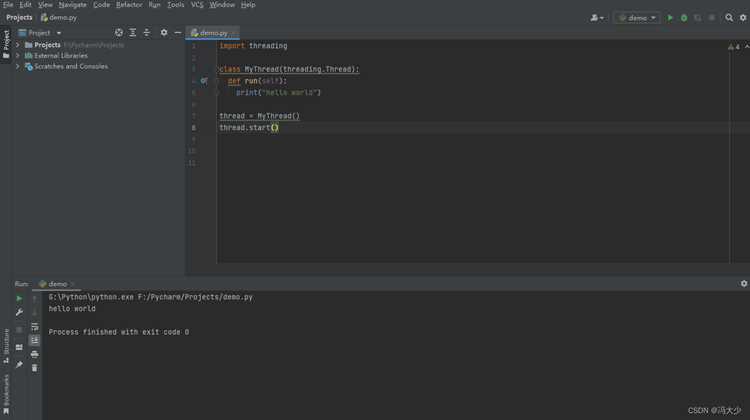
В Python различие между потоками (threads) и процессами (processes) критично для параллельного выполнения. Потоки делят память и ресурсы основного процесса, но ограничены глобальной блокировкой интерпретатора (GIL). Процессы создают отдельные пространства памяти, что позволяет использовать все ядра независимо.
Основные характеристики потоков и процессов можно сравнить по ключевым параметрам:
| Характеристика | Потоки (threading) | Процессы (multiprocessing) |
|---|---|---|
| Память | Общая память, обмен данными через объекты | Отдельная память, обмен через очереди и пайпы |
| Влияние GIL | Все потоки блокируются GIL при выполнении байткода | GIL не влияет, каждый процесс выполняется независимо |
| Использование CPU | Не ускоряет CPU-интенсивные задачи | Полноценно использует все ядра процессора |
| Создание | Быстрое, низкая нагрузка на память | Дольше создаются, потребляют больше ресурсов |
| Применение | Математические вычисления, обработка больших данных, параллельные алгоритмы |
Рекомендации по выбору:
- Для IO-зависимых задач выбирайте потоки, они позволяют обрабатывать несколько операций одновременно без затрат на создание процессов.
- Для CPU-зависимых задач используйте процессы, чтобы загрузить все ядра и сократить время вычислений.
- Комбинируйте подходы при смешанных задачах: потоки для сетевых операций, процессы для интенсивных вычислений.
Модуль multiprocessing для параллельного выполнения

Модуль multiprocessing позволяет создавать независимые процессы в Python, которые работают на разных ядрах без ограничений GIL. Каждый процесс имеет собственное пространство памяти, что предотвращает гонки данных при вычислениях.
Основные компоненты модуля:
- Process – создание отдельного процесса для выполнения функции.
- Pool – управление пулом процессов для распределения задач и ограничения числа одновременно работающих процессов.
- Queue и Pipe – безопасный обмен данными между процессами.
- Value и Array – совместное использование простых данных между процессами.
Пример практического применения:
- Обработка больших массивов данных, когда функция применяется к каждому элементу независимо.
- Вычислительные задачи, такие как генерация числовых моделей или симуляций, распределяемые по ядрам.
- Распараллеливание функций, вызываемых многократно с разными параметрами, с помощью Pool.map.
Рекомендации:
- Использовать пул процессов вместо создания каждого процесса вручную для контроля загрузки CPU.
- Минимизировать передачу больших объектов между процессами через очереди или пайпы, чтобы снизить накладные расходы на сериализацию.
- При объединении результатов использовать Pool.apply_async или очереди, чтобы избежать блокировки выполнения.
Создание и управление пулом процессов
Пул процессов (Pool) в модуле multiprocessing позволяет задавать фиксированное количество процессов для параллельного выполнения задач. Это снижает накладные расходы на создание процессов и контролирует загрузку CPU.
Создание пула выполняется через Pool(processes=N), где N – количество одновременно работающих процессов. Если значение не указано, Python использует число доступных ядер.
Методы управления задачами в пуле:
- map(func, iterable) – применяет функцию к каждому элементу последовательности и возвращает список результатов после завершения всех задач.
- apply(func, args) – выполняет функцию с указанными аргументами в одном процессе, блокируя основной поток до завершения.
- apply_async(func, args, callback) – асинхронное выполнение функции, можно указать callback для обработки результата после завершения.
- close() – запрещает добавление новых задач в пул.
- join() – ожидает завершения всех процессов в пуле после вызова close().
Рекомендации по использованию:
- Выбирать число процессов исходя из числа ядер и объема вычислений: слишком много процессов создают накладные расходы на переключение контекста.
- Использовать map для обработки больших последовательностей, когда важен порядок результатов, и apply_async для динамических задач с разными временем выполнения.
- Минимизировать передачу больших объектов между процессами через очередь, отдавая предпочтение работе с локальными данными.
Обмен данными между процессами

В Python процессы имеют отдельные пространства памяти, поэтому прямой доступ к объектам между ними невозможен. Для передачи данных применяются специальные механизмы: Queue, Pipe, Value и Array.
Queue реализует потокобезопасную очередь FIFO. Процессы могут помещать данные в очередь через put() и получать через get(). Это удобно для распределения задач и сбора результатов.
Pipe создаёт двустороннее соединение между двумя процессами. Используется для прямой передачи данных без промежуточного хранения, поддерживает методы send() и recv().
Value и Array позволяют совместно использовать простые типы данных и массивы, синхронизируя доступ через блокировки. Это подходит для счетчиков, флагов и небольших наборов числовых данных.
Рекомендации по обмену данными:
- Для больших объектов использовать Queue с пакетной отправкой данных, чтобы уменьшить накладные расходы на сериализацию.
- Для синхронизации состояния между процессами применять Value и блокировки, избегая гонок данных.
- Выбирать Pipe при необходимости передачи данных только между двумя процессами без очередей.
- Минимизировать частый обмен больших объемов данных, лучше обрабатывать их локально и передавать только результаты.
Использование concurrent.futures для многопроцессорности

Модуль concurrent.futures предоставляет удобный интерфейс для параллельного выполнения задач с использованием процессов через ProcessPoolExecutor. Каждый процесс выполняется независимо, что позволяет использовать все ядра процессора и обходить ограничения GIL.
Основные методы ProcessPoolExecutor:
- submit(func, *args, **kwargs) – отправка одной функции на выполнение, возвращает объект Future для контроля статуса и получения результата.
- map(func, iterable) – распараллеливает применение функции к коллекции элементов, возвращает результаты в исходном порядке.
- shutdown(wait=True) – завершает работу пула после выполнения всех задач, освобождая ресурсы.
Практические советы:
- Использовать submit для динамических задач с различным временем выполнения, чтобы обработка медленных задач не блокировала быстрые.
- Метод map подходит для больших последовательностей однотипных операций, когда важен порядок результатов.
- Оптимальное число процессов выбирать с учетом числа ядер и объема вычислений: избыточное количество процессов снижает производительность из-за переключения контекста.
- Минимизировать передачу больших объектов между процессами через аргументы функций, лучше работать с локальными данными и возвращать только результаты.
Распараллеливание задач с помощью joblib

Библиотека joblib предоставляет простой интерфейс для распараллеливания повторяющихся вычислений в Python. Основной инструмент – Parallel совместно с delayed, который позволяет распределять функции по доступным ядрам без ручного управления процессами.
Основные возможности joblib:
- Автоматическое определение числа доступных ядер и распределение задач между ними.
- Поддержка асинхронного выполнения через Parallel(n_jobs=N), где N – количество одновременно работающих процессов.
- Простое объединение результатов в список или массив, без необходимости явной сериализации и передачи данных.
Пример использования:
- Импортировать функции: from joblib import Parallel, delayed.
- Создать функцию для вычисления, которую нужно распараллелить.
- Вызвать Parallel(n_jobs=4)(delayed(func)(args) for args in iterable), чтобы распределить задачи по 4 ядрам.
Рекомендации по применению:
- Использовать joblib для вычислительно интенсивных циклов или обработки больших массивов данных.
- Минимизировать передачу больших объектов в функции, лучше работать с индексами или ссылками на локальные данные.
- Совмещать с numpy или pandas для распараллеливания операций над массивами и таблицами.
Отладка и измерение загрузки нескольких ядер
Для оценки работы многопроцессорных программ в Python применяются инструменты мониторинга CPU и встроенные средства измерения времени выполнения. Библиотека psutil позволяет отслеживать загрузку каждого ядра, использование памяти и состояние процессов.
Методы измерения времени выполнения:
- time.time() – базовый способ измерения общего времени выполнения функции.
- time.perf_counter() – высокая точность, подходит для кратких и повторяющихся вычислений.
- Использование concurrent.futures.as_completed или Pool.apply_async с колбэками для контроля времени выполнения отдельных процессов.
Отладка многопроцессорных приложений включает:
- Проверку корректного завершения всех процессов через join() и shutdown().
- Использование логирования для отслеживания ошибок в отдельных процессах.
- Сбор статистики по загрузке CPU и памяти для выявления узких мест и избыточного создания процессов.
Рекомендации по оптимизации:
- Сравнивать время выполнения с разным числом процессов, чтобы определить оптимальное использование ядер.
- Избегать передачи больших объектов между процессами без необходимости.
- Использовать psutil.cpu_percent(percpu=True) для анализа распределения нагрузки и выявления неравномерной загрузки ядер.
Вопрос-ответ:
Почему Python не использует все ядра процессора по умолчанию?
Python ограничен глобальной блокировкой интерпретатора (GIL), которая разрешает выполнение байткода только одним потоком за раз. Из-за этого даже на многоядерной системе многопоточность не ускоряет CPU-интенсивные задачи. Для параллельной работы с несколькими ядрами используют отдельные процессы, которые обходят ограничения GIL.
В чем разница между потоками и процессами в Python при распараллеливании?
Потоки работают внутри одного процесса и используют общую память, но ограничены GIL, поэтому не ускоряют вычисления на нескольких ядрах. Процессы создают отдельные пространства памяти и могут выполняться одновременно на разных ядрах. Потоки подходят для задач ввода-вывода, процессы — для математических вычислений и обработки больших данных.
Как правильно создать пул процессов в Python?
Для создания пула используют класс Pool из модуля multiprocessing. Указывают количество процессов через параметр processes. Задачи распределяются с помощью методов map или apply_async. После завершения работы нужно вызвать close() и join(), чтобы корректно завершить процессы и освободить ресурсы.
Какие способы обмена данными между процессами наиболее надежные?
Для обмена данными между процессами используют Queue, Pipe, Value и Array. Очереди безопасны для передачи множества объектов, пайпы удобны для двустороннего соединения между двумя процессами. Value и Array позволяют совместно использовать простые данные с блокировкой для предотвращения гонок.
Как измерить загрузку нескольких ядер и проверить, что параллельные задачи работают правильно?
Для мониторинга CPU используют библиотеку psutil, метод cpu_percent(percpu=True) показывает загрузку каждого ядра. Для измерения времени выполнения используют time.perf_counter() для точных измерений. Также важно отслеживать завершение всех процессов через join() или shutdown() и логировать ошибки, чтобы убедиться в корректной работе параллельных задач.
Можно ли использовать потоки для ускорения вычислений на нескольких ядрах?
Нет, потоки в Python ограничены глобальной блокировкой интерпретатора (GIL), которая не позволяет одновременно выполнять байткод на разных ядрах. Для ускорения CPU-интенсивных задач нужно создавать отдельные процессы через модуль multiprocessing или использовать ProcessPoolExecutor из concurrent.futures, которые обходят GIL и выполняются независимо на разных ядрах.
Как выбрать количество процессов при использовании multiprocessing?
Оптимальное число процессов зависит от числа ядер и характера задач. Обычно используют количество процессов, равное числу доступных ядер, чтобы каждый процесс работал на отдельном ядре. При слишком большом количестве процессов возрастает нагрузка на переключение контекста, что снижает производительность. Для вычислений с интенсивной обработкой данных лучше сначала протестировать несколько вариантов, например, ядра ±1, и выбрать наилучший баланс скорости и загрузки системы.