Дерево иерархии – структура данных, в которой каждый элемент, кроме корня, имеет ровно одного родителя и любое количество дочерних элементов. В C такое дерево обычно реализуется с помощью структур и указателей. Правильная организация узлов позволяет эффективно выполнять поиск, вставку и удаление элементов.
Каждый узел дерева хранит данные и ссылки на дочерние элементы. На практике часто используют динамическое выделение памяти через malloc или calloc, чтобы добавлять узлы во время работы программы. Для удобства к каждому узлу добавляют счетчик дочерних элементов или массив указателей на потомков.
Пошаговое создание дерева включает определение структуры узла, инициализацию корня, добавление дочерних элементов и функции для обхода. Обход может выполняться в глубину (DFS) или в ширину (BFS), что важно для сортировки и поиска информации внутри дерева.
В этой статье рассмотрены конкретные примеры кода и методы работы с памятью, позволяющие избежать утечек и ошибок сегментации. Практические рекомендации включают использование вспомогательных функций для добавления и удаления узлов, проверку корректности ссылок и тестирование структуры на простых наборах данных.
Определение структуры узла дерева в C
Для создания дерева иерархии в C необходимо определить структуру узла, которая будет содержать данные и ссылки на дочерние элементы. Чаще всего используется структура с полем для хранения значения и указателями на левый и правый дочерние узлы для бинарного дерева:
typedef struct Node {
int data;
struct Node* left;
struct Node* right;
} Node;
Если требуется дерево с произвольным количеством потомков, структура узла может включать массив указателей или динамически формируемый список детей:
typedef struct Node {
int data;
struct Node** children;
int childCount;
} Node;
Важно выделять память для каждого узла с помощью malloc и освобождать её после использования, чтобы избежать утечек. Инициализация указателей дочерних элементов в NULL позволяет безопасно проверять наличие потомков перед доступом к ним.
При работе с данными внутри узла рекомендуется выбирать типы данных в соответствии с потребностями: int, float, char* или структуры, содержащие несколько полей. Такая организация облегчает реализацию функций вставки, удаления и обхода дерева.
Инициализация корневого элемента
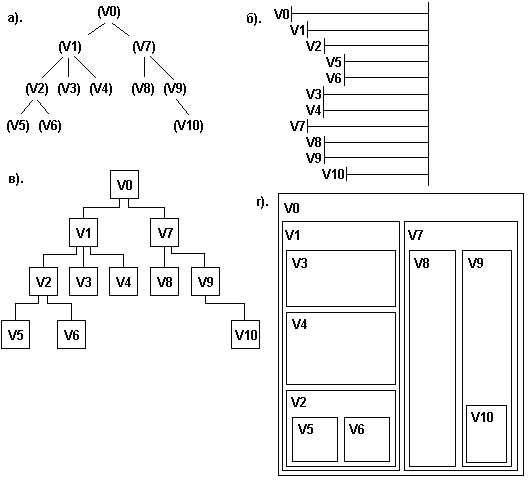
Корневой элемент дерева создаётся как первый узел, от которого будут отталкиваться все остальные. В C это обычно структура с указателями на дочерние узлы и хранимыми данными.
Для инициализации корня следует выделить память с помощью функции malloc и сразу задать значения полей. Например, если узел содержит целое значение и два дочерних указателя, их можно обнулить:
Node* root = (Node*)malloc(sizeof(Node));
root->data = 10;
root->left = NULL;
root->right = NULL;
После выделения памяти важно проверить, что malloc вернул ненулевой указатель. Это предотвратит ошибки при работе с деревом:
if (root == NULL) { printf("Ошибка выделения памяти"); exit(1); }
Корневой элемент теперь готов к добавлению дочерних узлов, а структура дерева полностью определена для дальнейшей работы. Присвоение начальных значений позволяет избежать неопределённого поведения при обращении к полям узла.
Добавление дочерних узлов в дерево
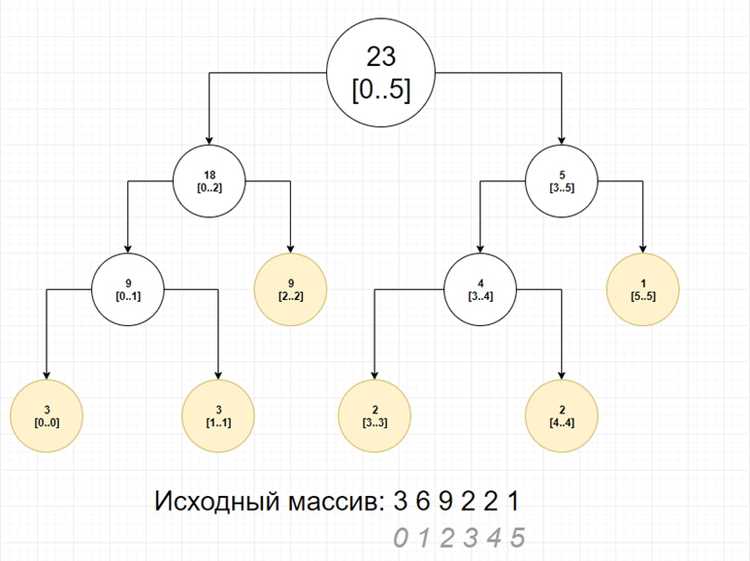
Для добавления дочернего узла необходимо создать новую структуру узла и присвоить ей данные. В C это выполняется через выделение памяти с помощью функции malloc и инициализацию полей структуры.
Пример структуры узла с указателями на детей:
typedef struct Node {
int data;
struct Node* left;
struct Node* right;
} Node;
Создание нового дочернего узла выполняется через функцию, которая принимает значение данных и возвращает указатель на инициализированный узел:
Node* createNode(int value) {
Node* newNode = (Node*)malloc(sizeof(Node));
if(newNode != NULL) {
newNode->data = value;
newNode->left = NULL;
newNode->right = NULL;
}
return newNode;
}
После создания узла его присваивают соответствующему полю родителя. Для бинарного дерева это left или right. Для многодетовых деревьев используют массив указателей или связный список детей.
Пример добавления в бинарное дерево:
parent->left = createNode(5);
parent->right = createNode(10);
Важно проверять, что место для нового дочернего узла свободно, чтобы избежать перезаписи существующих узлов. Для динамических структур с массивом детей контролируют текущий размер и расширяют память при необходимости.
Для многодетовых деревьев удобно использовать функцию добавления, которая добавляет узел в конец списка детей родителя, обеспечивая сохранение структуры и целостности дерева.
Поиск узла по значению в дереве

Пример функции на C для поиска узла с заданным значением:
struct Node* findNode(struct Node* root, int value) {
if (root == NULL) return NULL;
if (root->data == value) return root;
struct Node* child = root->firstChild;
while (child != NULL) {
struct Node* result = findNode(child, value);
if (result != NULL) return result;
child = child->nextSibling;
}
return NULL;
}
В этом примере структура Node содержит поле data для значения, firstChild для первого дочернего узла и nextSibling для следующего узла на том же уровне.
Итеративный поиск выполняется с использованием стека или очереди, что позволяет избежать глубокой рекурсии при больших деревьях. Для поиска в ширину (BFS) используют очередь, добавляя в неё всех дочерних узлов текущего узла и проверяя их значения.
Важно учитывать, что при деревьях с большим числом узлов рекурсивный DFS может привести к переполнению стека, поэтому для крупных структур рекомендуется итеративный подход.
После нахождения узла можно получать доступ к его данным и дочерним элементам, что позволяет выполнять операции модификации или анализа поддеревьев.
Удаление узла и корректировка связей
Удаление узла в дереве требует пересмотра связей между родителем и дочерними элементами. Для начала необходимо определить тип узла: листовой или внутренний. Листовой узел удаляется напрямую с освобождением памяти и корректировкой указателя родителя на NULL.
Для внутреннего узла алгоритм сложнее. Если у узла есть один дочерний элемент, указатель родителя перенаправляется на этого ребёнка, а память исходного узла освобождается. При наличии двух детей применяется замена значением ближайшего по порядку узла – либо максимального в левом поддереве, либо минимального в правом поддереве. После копирования значения удаляемый узел преобразуется в лист или узел с одним ребёнком, и применяется соответствующая процедура.
Пример структуры узла и функции удаления:
| Структура | Функция удаления |
|---|---|
typedef struct Node {
int value;
struct Node* left;
struct Node* right;
} Node;
|
Node* deleteNode(Node* root, int key) {
if (!root) return NULL;
if (key < root->value) root->left = deleteNode(root->left, key);
else if (key > root->value) root->right = deleteNode(root->right, key);
else {
if (!root->left) {
Node* temp = root->right;
free(root);
return temp;
} else if (!root->right) {
Node* temp = root->left;
free(root);
return temp;
}
Node* temp = findMin(root->right);
root->value = temp->value;
root->right = deleteNode(root->right, temp->value);
}
return root;
}
|
Функция findMin возвращает узел с минимальным значением в поддереве. После удаления важно корректно обновлять указатели родителя, чтобы структура дерева оставалась непрерывной и не создавались «висячие» ссылки.
Регулярная проверка дерева после операций удаления помогает предотвратить потерю доступа к поддеревьям и гарантирует корректное функционирование последующих вставок и поиска.
Реализация обхода дерева: прямой и обратный
Обход дерева необходим для обработки всех узлов в заданной последовательности. В C обход часто реализуется рекурсивно, используя указатели на дочерние элементы.
Прямой обход (pre-order) посещает узел до его дочерних элементов. Алгоритм:
- Обработать текущий узел.
- Рекурсивно обойти левое поддерево.
- Рекурсивно обойти правое поддерево.
Пример функции на C:
void preorder(Node* node) {
if (node == NULL) return;
printf("%d ", node->value);
preorder(node->left);
preorder(node->right);
}Обратный обход (post-order) посещает дочерние элементы перед узлом. Алгоритм:
- Рекурсивно обойти левое поддерево.
- Рекурсивно обойти правое поддерево.
- Обработать текущий узел.
Пример функции на C:
void postorder(Node* node) {
if (node == NULL) return;
postorder(node->left);
postorder(node->right);
printf("%d ", node->value);
}Для больших деревьев можно использовать стек вместо рекурсии. Это предотвращает переполнение стека при глубокой рекурсии. При прямом обходе элементы помещаются в стек по обратному порядку: сначала правый потом левый, чтобы левый обрабатывался первым.
Выбор типа обхода зависит от задачи: прямой подходит для копирования дерева или генерации структуры, обратный – для удаления узлов или вычислений значений снизу вверх.
Для отображения дерева на экране необходимо реализовать обход структуры с рекурсией или использованием стека. В простейшем случае рекурсивная функция принимает указатель на текущий узел и уровень глубины, позволяя визуально отделять ветви от корня.
Пример функции печати для дерева с указанием отступов по глубине:
void printTree(Node* node, int depth) {
if (node == NULL) return;
for (int i = 0; i < depth; i++) printf(" ");
printf("%s\n", node->name);
for (int i = 0; i < node->childCount; i++)
printTree(node->children[i], depth + 1);
}
В данном примере каждый уровень дерева сдвигается вправо на два пробела. Для узлов с несколькими детьми используется цикл, чтобы пройтись по всем ветвям. Такой подход позволяет наглядно увидеть иерархию и структуру подузлов.
Сохранение и загрузка дерева из файла

Для сохранения структуры дерева в C используется бинарная или текстовая сериализация узлов. В бинарном формате сохраняются указатели и значения узлов, что ускоряет запись и чтение, но требует строгого соответствия структуры при загрузке. Текстовый формат проще для отладки и изменения вручную.
Пример последовательности действий для бинарного сохранения:
- Открыть файл в режиме записи:
FILE *file = fopen("tree.dat", "wb"); - Рекурсивно обойти дерево и записать каждый узел:
- Сначала значение узла:
fwrite(&node->value, sizeof(int), 1, file); - Количество дочерних узлов:
fwrite(&node->children_count, sizeof(int), 1, file); - Вызвать функцию для каждого дочернего узла.
- Закрыть файл:
fclose(file);
Для загрузки дерева из бинарного файла:
- Открыть файл в режиме чтения:
FILE *file = fopen("tree.dat", "rb"); - Рекурсивно создавать узлы, читая значение и количество дочерних элементов:
- Чтение значения узла:
fread(&node->value, sizeof(int), 1, file); - Чтение количества детей:
fread(&node->children_count, sizeof(int), 1, file); - Создание и привязка дочерних узлов с рекурсивным вызовом функции.
- Закрыть файл после завершения:
fclose(file);
Для текстового формата удобно использовать отступы или специальные символы для обозначения уровня вложенности. Пример записи:
NodeValue Child1Value GrandChildValue Child2Value
При загрузке из текстового файла читаются строки, определяется уровень отступа, создаются узлы и связываются с родительским узлом. Такой подход упрощает ручную проверку и модификацию дерева.
Рекомендуется проверять успешность операций fopen, fread и fwrite, а также корректно освобождать память при загрузке дерева, чтобы избежать утечек.
Вопрос-ответ:
Что такое дерево иерархии в C и как оно отличается от обычного массива?
Дерево иерархии — это структура данных, где каждый элемент (узел) может иметь несколько дочерних элементов. В отличие от массива, который хранит данные линейно, дерево позволяет представлять сложные зависимости и связи между элементами, обеспечивая быстрый поиск и вставку узлов в любой части структуры.
Как правильно определить структуру узла дерева в C?
Узел дерева обычно реализуется с помощью структуры struct. Она включает поле для значения узла, указатель на родителя и массив или список указателей на дочерние узлы. Например, для дерева с переменным числом детей можно использовать динамический массив или связный список для хранения дочерних указателей.
Какие методы обхода дерева применяются и в чем их различие?
В C чаще всего используют прямой (pre-order) и обратный (post-order) обход. Прямой обход обрабатывает текущий узел перед дочерними, что удобно для копирования дерева. Обратный обход сначала обрабатывает все дочерние узлы, а потом текущий, что полезно при удалении дерева, чтобы сначала освободить память всех потомков.
Как реализовать сохранение дерева в файл и восстановление из него?
Сохранение дерева требует записи структуры узлов и их связей. Можно использовать рекурсивный обход, записывая значения узлов и количество детей. Для восстановления читают данные последовательно, создают узлы и заново устанавливают связи. Важно сохранять порядок дочерних узлов, чтобы восстановленное дерево совпадало с исходным.
Какие ошибки чаще всего встречаются при удалении узлов дерева в C?
Чаще всего возникают ошибки из-за неправильного обновления указателей на родителя и дочерние элементы. Если удалить узел, не переназначив связи, можно потерять доступ к целым ветвям дерева или вызвать утечки памяти. Также важно освобождать память рекурсивно для всех потомков, чтобы избежать зависших указателей.
Как правильно определить структуру узла для дерева в C?
Для создания дерева в C нужно заранее определить структуру узла, которая будет хранить данные и указатели на дочерние элементы. Обычно используется структура с полями для значения узла и массива или списка указателей на потомков. Например, для бинарного дерева достаточно двух указателей — на левый и правый дочерние узлы. Для дерева с произвольным количеством детей можно использовать динамический массив указателей или связанный список. При этом важно учитывать выделение памяти и её освобождение после удаления узлов, чтобы избежать утечек памяти.
Каким образом можно реализовать добавление дочернего узла к существующему элементу дерева?
Добавление дочернего узла начинается с поиска родительского узла, к которому нужно прикрепить новый элемент. После этого выделяется память для нового узла и заполняются его поля. В случае бинарного дерева проверяется, свободен ли левый или правый указатель, и присваивается соответствующий. В деревьях с произвольным количеством потомков новый узел можно добавлять в конец массива или списка указателей на детей. Важно следить за корректной работой указателей и при необходимости увеличивать размер динамического массива, чтобы не выйти за пределы выделенной памяти.