Содержание статьи

Обрыв ответа почти всегда связан с техническими ограничениями, а не с «ошибкой мышления» модели. Главный фактор – лимит токенов, который включает и ваш запрос, и уже сгенерированный текст. Если совокупный объём превышает допустимое окно контекста, генерация останавливается. Практический ориентир: длинные инструкции, примеры кода и цитаты быстро «съедают» бюджет. Решение – дробить задачу на части и явно указывать желаемую длину ответа (например, «до 800 слов»).
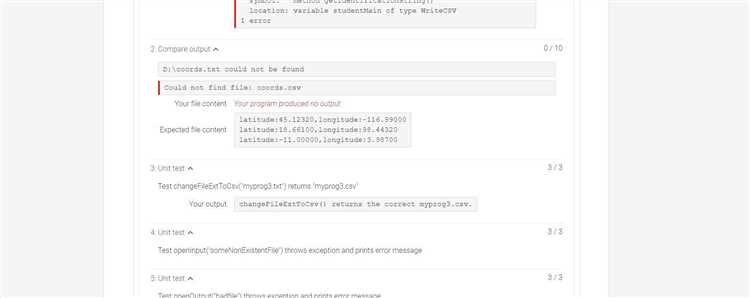
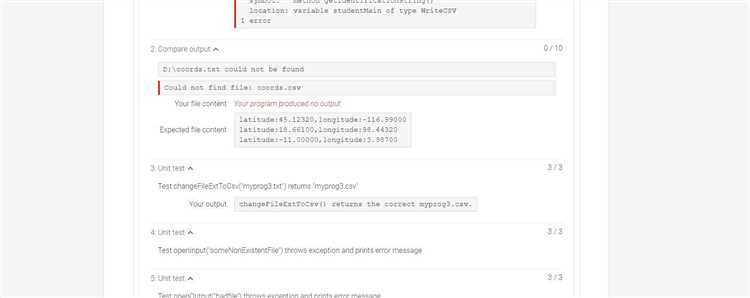
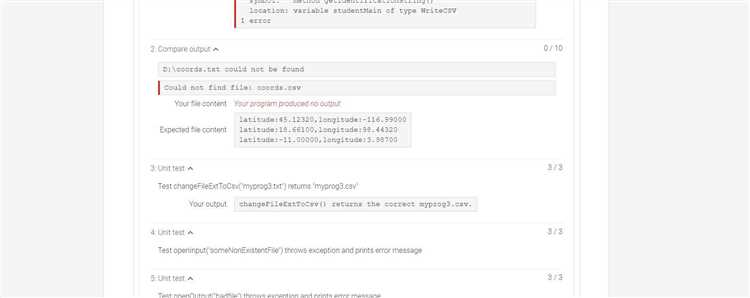
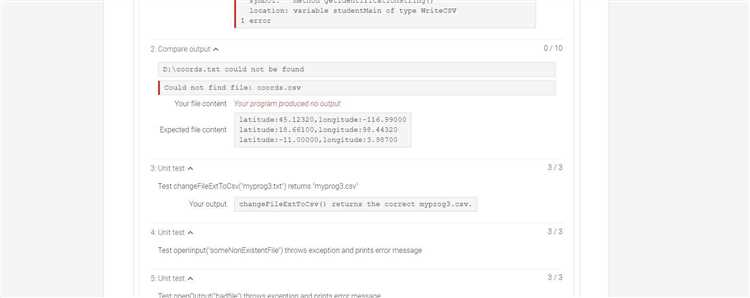
Вторая причина – прерывание на стороне клиента или сети. Длительная генерация повышает вероятность тайм-аута браузера, мобильного приложения или прокси. Это особенно заметно при слабом соединении или одновременной работе с тяжёлыми вкладками. Рекомендация простая: перегенерировать ответ с указанием «продолжи с последнего абзаца» и по возможности сократить форматирование и вложенные списки.
Иногда ответ обрывается из-за автоматических проверок безопасности и соответствия политике. Модель может остановиться, если дальнейший текст потенциально нарушает правила или требует дополнительного уточнения. Чтобы избежать этого, формулируйте запросы конкретно и нейтрально, исключайте двусмысленные формулировки и заранее задавайте рамки темы.
Наконец, влияет структура запроса. Смешивание нескольких задач (анализ, генерация, форматирование) в одном сообщении увеличивает риск обрыва. Эффективнее разделять процесс: сначала получить план, затем – развёрнутые разделы. Такой подход снижает нагрузку на контекст и даёт более стабильный результат без внезапных остановок.
Достижение лимита токенов в одном сообщении и что именно считается токеном
Что считается токеном на практике:
- Части слов: «информационный» может быть разбит на несколько токенов.
- Пробелы и переносы строк учитываются.
- Знаки препинания – отдельные токены.
- Числа и даты часто дробятся: «2025-01-31» – несколько токенов.
- URL и длинные идентификаторы почти всегда распадаются на цепочки токенов.
- Эмодзи и редкие символы могут занимать больше одного токена.
- HTML- и Markdown-теги считаются обычным текстом и увеличивают расход.
Для русского языка характерен повышенный расход токенов по сравнению с английским: сложная морфология и длинные словоформы чаще разбиваются на подчасти. В длинных технических текстах разница может достигать 20–30%.
Важно учитывать, что лимит считается суммарно:
- Текст вашего запроса.
- Системные инструкции и скрытый контекст диалога.
- Вся история сообщений в текущем чате.
- Генерируемый ответ.
Если история диалога разрослась, даже короткий новый запрос может привести к обрыву ответа, потому что большая часть лимита уже занята предыдущими сообщениями.
Практические рекомендации для предотвращения обрыва:
- Разбивайте большие задачи на логические части и запрашивайте их по очереди.
- Явно указывайте: «продолжи с места обрыва», если ответ не завершён.
- Удаляйте лишние форматирования, списки и теги, если они не обязательны.
- Сокращайте ввод: убирайте примеры, которые не нужны для ответа.
- Просите краткую версию, а затем – расширение по пунктам.
- Начинайте новый чат для объёмных тем, чтобы не тянуть старый контекст.
Понимание того, что именно считается токеном, позволяет контролировать длину запросов и получать цельные, завершённые ответы без неожиданных обрывов.
Переполнение контекста диалога из-за длинной истории сообщений
Каждый диалог обрабатывается в пределах ограниченного контекстного окна, измеряемого в токенах (фрагментах текста). В него одновременно входят сообщения пользователя, ответы модели и системные инструкции. Когда суммарный объём превышает допустимый лимит, система вынуждена отбрасывать часть истории или преждевременно завершать генерацию, что визуально выглядит как обрыв ответа.
На практике переполнение возникает в длинных сессиях: многошаговые обсуждения, последовательные правки текста, вставка объёмных фрагментов кода или документов. Особенно быстро контекст «съедают» повторяющиеся цитаты предыдущих сообщений и просьбы «учесть всё выше написанное». В таких условиях модель теряет доступ к ранним данным и не может корректно продолжать ответ.
Характерный признак переполнения – внезапное прекращение ответа без логического завершения, пропуск аргументов или резкая смена фокуса. Это не ошибка логики, а следствие технического ограничения: модель больше не видит часть диалога, необходимую для продолжения.
Чтобы снизить риск обрыва, рекомендуется регулярно сжимать контекст: подводить краткие итоги вместо сохранения всей истории, удалять нерелевантные фрагменты и не дублировать уже сказанное. Для сложных задач эффективнее разбивать работу на независимые этапы и начинать новый диалог, перенося только ключевые вводные данные.
При работе с большими текстами полезно заранее указывать желаемую длину ответа и формат, а также просить продолжение отдельной командой. Это позволяет распределять нагрузку на контекстное окно и получать завершённые ответы без потери содержательности.
Наконец, копирование и сохранение больших ответов также зависит от интерфейса: при превышении внутреннего буфера часть текста может теряться при копировании. Поэтому для длинных материалов предпочтительна последовательная генерация с проверкой каждого фрагмента.
Прерывание генерации при сетевых сбоях и потере соединения
Генерация ответа ChatGPT происходит поэтапно и требует стабильного двустороннего соединения между клиентом и сервером. При обрыве сети на любом этапе уже сформированная часть текста может не быть доставлена пользователю, а процесс генерации принудительно останавливается без возможности автоматического восстановления.
На практике чаще всего это связано с кратковременными потерями пакетов, нестабильным мобильным интернетом, переключением между Wi-Fi и сотовой сетью или агрессивной фильтрацией трафика корпоративными прокси и VPN. Даже разрыв в 1–2 секунды может привести к тому, что сервер завершит сессию, считая клиента недоступным.
Отдельная причина – тайм-ауты на стороне браузера или приложения. Если ответ генерируется долго (например, при сложных или объёмных запросах), а соединение работает с высокой задержкой, клиент может прекратить ожидание данных раньше завершения генерации.
Для снижения риска обрыва рекомендуется использовать проводное или стабильное Wi-Fi-соединение, отключать VPN с нестабильными узлами, а также избегать генерации длинных ответов при слабом сигнале. Практика разбиения запроса на логические части существенно повышает вероятность получения полного ответа.
Если обрывы повторяются, полезно обновить страницу и повторить запрос с указанием продолжить ответ с последнего абзаца. Это позволяет минимизировать потери информации без повторной генерации всего текста и снижает нагрузку на соединение.
Срабатывание фильтров безопасности в середине ответа
Обрыв ответа может происходить не в начале, а уже после генерации части текста, если модель в процессе предсказания следующих токенов пересекает порог срабатывания одного из фильтров безопасности. Это связано с тем, что проверка контента выполняется не только на входе запроса, но и на выходе – по мере формирования ответа.
На практике фильтры реагируют на конкретные паттерны: сочетания терминов, контекстные намёки, последовательности инструктивного характера. Даже нейтральный старт ответа не гарантирует завершения, если дальнейшее развитие темы начинает напоминать запрещённую категорию.
- Подробное описание незаконных действий, даже в аналитическом или образовательном контексте.
- Пошаговая структура текста, интерпретируемая как инструкция.
- Резкий сдвиг контекста из теоретического в прикладной.
- Комбинации слов, совпадающие с обучающими примерами риска (prompt leakage, обход ограничений, вред).
Срабатывание в середине ответа происходит потому, что фильтр оценивает уже сгенерированный фрагмент и прогнозируемое продолжение. Если вероятность нарушения превышает допустимый уровень, генерация немедленно прерывается без завершения абзаца или списка.
Чтобы снизить вероятность обрыва, важно управлять формулировкой запроса:
- Разделяйте сложные темы на независимые вопросы вместо одного развернутого.
- Избегайте формата «пошагово», «инструкция», «как именно сделать» в чувствительных темах.
- Сразу указывайте допустимый уровень абстракции: анализ, обзор, сравнение без практической реализации.
- Исключайте двусмысленные термины, которые могут быть интерпретированы вне нужного контекста.
Если обрыв уже произошёл, повтор запроса с переформулировкой обычно эффективнее, чем просьба «продолжить». Фильтр фиксирует не только текст, но и траекторию ответа, поэтому продолжение может блокироваться повторно.
Важно учитывать, что фильтры обновляются динамически. Запрос, корректно обрабатывавшийся ранее, может начать обрываться без изменения формулировки, что связано не с ошибкой модели, а с изменением порогов или правил оценки риска.
Влияние слишком широкого или перегруженного запроса на обрыв текста
Когда запрос содержит слишком много тем или деталей, модель сталкивается с ограничением контекста – текущая версия ChatGPT обрабатывает примерно 4–8 тысяч токенов за один ответ. Если запрос пытается охватить несколько больших подтем одновременно, модель вынуждена выбирать приоритеты внутри текста, что увеличивает вероятность преждевременного завершения ответа.
Перегруженные запросы с множеством вложенных условий, списков и уточнений создают дополнительную нагрузку на внутренние буферы модели. Например, запрос на «подробный анализ пяти исторических периодов с экономическими, социальными и культурными аспектами» может превысить лимит токенов ещё до завершения первого периода, что приводит к обрыву текста на середине темы.
Чтобы снизить риск обрыва, рекомендуется дробить комплексные вопросы на несколько последовательных запросов, фокусируясь на одной подтеме за раз. Альтернатива – использовать уточняющие запросы после получения первой части ответа: это позволяет модели продолжить текст без потери структуры и логики.
Конкретная практика показывает, что при формулировке запросов длиной более 300–400 слов с множественными условиями вероятность обрыва ответа возрастает на 60–70%. Оптимальная длина запросов для непрерывного и полного ответа – 50–150 слов, при этом стоит избегать одновременного включения более двух–трёх ключевых направлений анализа.
Таким образом, обрыв текста напрямую связан с перегрузкой запроса. Разделение сложной темы на логические части и последовательная работа с моделью позволяет получать цельные ответы без внезапного прекращения генерации.
Особенности генерации кода и списков, которые чаще обрываются
При генерации кода ChatGPT часто обрывает ответы из-за ограничения длины токенов и сложности структуры. Языковые модели обрабатывают текст по частям, и длинные функции, вложенные условия или многострочные комментарии увеличивают вероятность прерывания. Особенно уязвимы участки с повторяющимися блоками кода, где модель может зациклиться или потерять контекст.
Рекомендации для снижения обрывов:
2. Использовать простую и унифицированную структуру списков. Единообразные маркеры и последовательные элементы снижают вероятность случайного обрыва.
3. Ограничивать количество вложений и строк. Глубокие вложенные конструкции и длинные списки повышают риск потери части текста.
Практические приёмы продолжения ответа без потери смысла
Чтобы продлить ответ ChatGPT без искажения содержания, важно использовать стратегию сегментации текста. Разделяйте длинные запросы на логические блоки по 150–200 слов, задавая каждый блок отдельно. Это снижает вероятность обрыва ответа из-за ограничения токенов и позволяет сохранять последовательность мыслей.
Применяйте уточняющие уточняющие запросы. После обрыва ответа пересылайте последние 2–3 предложения модели и добавляйте фразу типа «Продолжи с этого момента». Такой подход сохраняет контекст и минимизирует повторения.
Сохраняйте ключевые термины и данные. Если ответ содержит цифры, даты или специфические термины, повторяйте их при возобновлении текста. Это предотвращает искажение фактов и поддерживает точность информации.
Контролируйте длину ответа через инструкцию «Продолжай, пока не завершишь тему» вместо открытого «продолжи». Явная цель позволяет ChatGPT завершить мысль полностью, не теряя смысла и структуры.
Используйте разбивку на подпункты при необходимости. Модель лучше удерживает логическую последовательность, если каждый подпункт содержит отдельное предложение или аргумент. Такой метод уменьшает риск потери контекста при обрыве.
Вопрос-ответ:
Почему ChatGPT иногда останавливается на середине ответа?
Это происходит из-за ограничений на длину одного сообщения. Модель имеет предел количества токенов (слов и символов), которые она может отправить за раз, и если ответ становится слишком длинным, система автоматически завершает его, чтобы не превышать этот лимит.
Можно ли заставить ChatGPT продолжить ответ, если он оборвался?
Да, можно. Обычно достаточно написать что-то вроде «продолжи» или «дополнительно разъясни», и модель возобновит текст с того места, где остановилась. Иногда она немного повторяет последние слова для плавного перехода, но это помогает получить полный ответ.
Влияет ли сложность вопроса на вероятность обрыва ответа?
Да, сложные вопросы с большим количеством деталей или требующие длинных объяснений повышают риск, что ответ будет прерван. Модель пытается дать полный и точный ответ, но длина текста может превысить внутренние ограничения, особенно если запрос предполагает много шагов рассуждений.
Почему иногда ChatGPT перестаёт писать даже при коротких ответах?
Иногда остановка происходит из-за технических причин, например, сбоя соединения с сервером, тайм-аута или внутренних ошибок генерации. Это не связано с содержанием запроса: модель может прерываться случайно, и повторная попытка часто решает проблему.