Содержание статьи

Redis – это высокопроизводительная база данных в памяти, которая хранит данные в виде ключ-значение и поддерживает сложные структуры: списки, множества, хэши и упорядоченные множества. В отличие от традиционных реляционных баз, Redis позволяет получать доступ к данным за миллисекунды, что особенно важно для систем с высокой нагрузкой.
Часто Redis используют для кэширования результатов запросов к базам данных, чтобы снизить нагрузку и ускорить обработку повторяющихся операций. Например, кэширование последних 1000 поисковых запросов на сайте может уменьшить время отклика на 80–90%.
Помимо кэширования, Redis применяется для организации очередей сообщений и задач. Это позволяет строить распределенные системы, где процессы быстро передают задачи друг другу без задержек и конфликтов данных.
Redis поддерживает механизмы сохранения данных на диск через RDB-снимки и AOF-журнал, что обеспечивает восстановление после сбоев. Настройка этих механизмов зависит от требований к скорости и надежности: можно сохранять данные каждые несколько секунд или фиксировать каждую операцию.
С помощью Redis удобно хранить сессии пользователей и временные данные, такие как токены авторизации или результаты вычислений. Это снижает нагрузку на основную базу и ускоряет работу веб-приложений без потери информации.
Как Redis хранит данные в памяти и ускоряет доступ

Redis полностью хранит данные в оперативной памяти, что позволяет обрабатывать запросы за микросекунды. Каждый ключ и значение располагаются в структурах данных, оптимизированных для быстрого поиска и изменения.
Основные механизмы ускорения доступа в Redis:
- Хэш-таблицы – используются для хранения ключей и обеспечения O(1) доступа к значениям.
- Списки и множества – реализованы через двусвязные списки и skip-листы для быстрого добавления, удаления и поиска элементов.
- Упорядоченные множества – позволяют хранить элементы с рейтингами и выполнять операции сортировки без перебора всех данных.
- Инкременты и счетчики – обеспечивают мгновенное обновление числовых значений без блокировок.
Для больших наборов данных Redis использует экспирацию ключей, удаляя устаревшие записи и освобождая память. Это позволяет поддерживать высокую производительность без ручного управления.
Рекомендации по использованию:
- Хранить часто используемые данные в Redis, чтобы сократить время обращения к основной базе.
- Использовать подходящие структуры данных для конкретных задач – строки для кеша, списки для очередей, множества для уникальных элементов.
- Настроить лимиты памяти и политику удаления ключей (maxmemory-policy), чтобы предотвратить переполнение.
- Контролировать нагрузку через мониторинг INFO и команды MONITOR, чтобы выявлять узкие места в доступе к памяти.
Применение Redis для кэширования запросов к базе данных
Redis позволяет хранить результаты запросов к базе данных в памяти, сокращая время ответа и снижая нагрузку на основной сервер. Использование кэша особенно оправдано для часто повторяющихся операций с неизменяемыми данными.
Для кэширования создаются ключи, которые отражают параметры запроса, а значения хранят готовый результат. Для управления временем хранения используют TTL, устанавливая его в зависимости от частоты обновления данных. Например, данные о курсах валют можно держать в кэше 5 минут, а статическую справочную информацию – несколько часов.
Рекомендации по организации кэширования:
- Выделять критически важные запросы для кэширования, снижая нагрузку на базу данных.
- Использовать атомарные операции Redis, такие как SETNX и INCR, чтобы избежать конфликтов при одновременном обновлении кэша.
- Регулярно проверять актуальность данных и удалять устаревшие ключи, чтобы исключить выдачу неверной информации.
- Мониторить эффективность кэша с помощью показателя cache hit ratio, оценивая, какой процент запросов обслуживается напрямую из Redis.
- Подбирать структуру данных под тип результата: строки для одиночных записей, хэши для сложных объектов, списки для упорядоченных данных.
Использование Redis для очередей сообщений и задач
Redis применяется для построения очередей сообщений и задач благодаря быстрым операциям с памятью и поддержке списков и упорядоченных множеств. С помощью Redis можно организовать распределенные системы обмена данными между процессами или сервисами.
Основные механизмы:
- Списки Redis используют команды LPUSH и RPOP для добавления и извлечения задач, реализуя структуру очереди FIFO.
- Упорядоченные множества (ZSET) позволяют ставить задачи в очередь с приоритетами, используя баллы для сортировки.
- Pub/Sub механизм обеспечивает мгновенную рассылку сообщений подписчикам без хранения истории, подходя для событийных систем.
Рекомендации при использовании:
- Определять тип очереди: простая FIFO для последовательных задач или приоритетная для критичных операций.
- Использовать атомарные команды Redis, чтобы избежать гонок при одновременном доступе к очереди несколькими процессами.
- Настраивать мониторинг длины очереди и времени обработки задач, чтобы выявлять узкие места и предотвращать накопление необработанных задач.
- Сохранять критичные задачи на диск через AOF или RDB, чтобы избежать потери при перезапуске сервера.
- Применять Lua-скрипты для сложных операций с очередями, чтобы гарантировать атомарность и целостность данных.
Работа с типами данных Redis: строки, списки, множества

Redis поддерживает несколько базовых типов данных, каждый из которых подходит для конкретных задач хранения и обработки информации.
Строки – универсальный тип для хранения текстовых или числовых значений. Поддерживаются операции установки и получения значения (SET, GET), инкременты и декременты (INCR, DECR). Используются для кэширования одиночных записей, счетчиков и токенов.
Списки реализованы как двусвязные и позволяют добавлять элементы в начало или конец (LPUSH, RPUSH) и извлекать их (LPOP, RPOP). Применяются для организации очередей задач, потоков событий или истории действий пользователя.
Множества хранят уникальные элементы и обеспечивают быстрые операции добавления, удаления и проверки наличия элемента (SADD, SREM, SISMEMBER). Подходят для хранения тегов, уникальных идентификаторов и списков участников.
Рекомендации по выбору типа данных:
- Использовать строки для одиночных значений и счетчиков.
- Выбирать списки для очередей и упорядоченных последовательностей.
- Применять множества для уникальных коллекций и быстрого поиска по элементам.
- Для операций с большим количеством элементов учитывать ограничения памяти и использовать SCAN вместо SMEMBERS для перебора.
Настройка автоматического сохранения данных на диск
Redis предоставляет два основных метода сохранения данных на диск: RDB-снимки и AOF (Append Only File). RDB создает периодические снимки всей базы, а AOF записывает каждую операцию изменения данных в лог-файл.
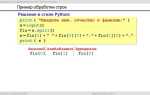
RDB подходит для восстановления базы в случае сбоя с допустимой потерей последних изменений. В конфигурации redis.conf задаются правила сохранения, например: save 900 1 означает создание снимка каждые 900 секунд при изменении хотя бы одного ключа.
AOF обеспечивает более точное восстановление, записывая все команды изменения в файл. Опция appendfsync регулирует частоту записи: always, everysec или no, что влияет на баланс между скоростью и надежностью.
Рекомендации по настройке:
- Использовать RDB для резервных снимков с интервалом 5–15 минут при большой базе данных.
- Включить AOF для критичных данных, чтобы минимизировать потерю информации.
- Регулярно комбинировать RDB и AOF, используя BGREWRITEAOF для уменьшения размера лог-файла.
- Контролировать использование диска и частоту сохранений, чтобы избежать перегрузки системы.
Использование Redis для хранения сессий пользователей
Redis хранит сессии пользователей как ключи с уникальными идентификаторами, а значениями выступают данные сессии: токены, настройки или временные параметры. Это обеспечивает мгновенный доступ и обработку большого числа сессий одновременно.
Для управления временем жизни сессий используют TTL через команды EXPIRE или SETEX, что позволяет автоматически удалять неактивные сессии. Хэши Redis подходят для сложных сессий, где каждое поле обновляется отдельно без пересохранения всей записи.
Рекомендации по работе с сессиями:
- Обновлять TTL при активности пользователя, чтобы поддерживать сессию активной только при взаимодействии.
- Сохранять минимально необходимые данные, чтобы уменьшить потребление памяти.
- Использовать репликацию или AOF для сохранности критичных данных при сбое сервера.
- Разделять сессии по namespace, если система обслуживает несколько приложений или микросервисов.
- Мониторить количество активных сессий и использование памяти для своевременного масштабирования Redis.
Мониторинг и управление производительностью Redis

Для поддержания высокой производительности Redis необходимо контролировать использование памяти, количество операций в секунду и скорость отклика. Основные инструменты мониторинга включают команды INFO, MONITOR и встроенные метрики в системах наблюдения.
В таблице приведены ключевые показатели и рекомендации по их контролю:
| Показатель | Описание | Рекомендации |
|---|---|---|
| used_memory | Объем оперативной памяти, используемой Redis | Следить, чтобы не превышать лимит maxmemory; при необходимости включить политику удаления ключей. |
| instantaneous_ops_per_sec | Количество операций в секунду | Сравнивать с ожидаемой нагрузкой; при превышении рассматривать масштабирование или оптимизацию кода. |
| connected_clients | Количество подключенных клиентов | Ограничивать с помощью maxclients и балансировать нагрузку через пул клиентов. |
| expired_keys | Количество удаленных по истечении TTL ключей | Контролировать, чтобы старые ключи удалялись своевременно и не нагружали память. |
| keyspace_hits / keyspace_misses | Статистика попаданий и промахов кэша | Поддерживать высокий коэффициент hit ratio для ускорения работы приложений. |
Рекомендации по управлению производительностью:
- Использовать slowlog для выявления медленных команд.
- Регулярно проверять распределение ключей по пространству имен, чтобы избежать «горячих» ключей.
- Настроить репликацию и шардирование для равномерного распределения нагрузки.
- Обновлять версию Redis, чтобы использовать оптимизации и новые команды, улучшающие производительность.
Вопрос-ответ:
Для чего конкретно используют Redis в веб-приложениях?
Redis применяют для ускорения работы веб-приложений через кэширование данных, хранение сессий пользователей, управление очередями задач и сообщений. Он позволяет снизить нагрузку на основную базу данных и обеспечивать мгновенный доступ к часто запрашиваемой информации.
Какие типы данных поддерживает Redis и в каких случаях их использовать?
Redis поддерживает строки, списки, множества, упорядоченные множества и хэши. Строки подходят для одиночных значений и счетчиков, списки — для очередей и последовательностей, множества — для хранения уникальных элементов, хэши — для сложных объектов с несколькими полями, а упорядоченные множества — для задач с приоритетами и сортировкой.
Как Redis сохраняет данные на диск и можно ли настроить частоту сохранения?
Redis использует RDB-снимки и AOF-журналы. RDB делает периодические снимки всей базы, а AOF записывает каждую операцию изменения данных. Частоту сохранения можно настраивать в конфигурации через интервал создания снимков или режим записи AOF, что позволяет балансировать между скоростью работы и сохранностью информации.
Можно ли использовать Redis для хранения сессий пользователей и как это сделать правильно?
Да, Redis подходит для хранения сессий. Каждая сессия создается как ключ с уникальным идентификатором, а значения содержат данные сессии. Для управления временем жизни используют TTL через команды EXPIRE или SETEX. Рекомендуется хранить только необходимые данные, обновлять TTL при активности пользователя и контролировать объем памяти для поддержания стабильной работы.
Какие методы мониторинга Redis помогают выявлять узкие места в производительности?
Для анализа производительности используют команды INFO и MONITOR, а также slowlog для выявления медленных операций. Основные показатели: использование памяти, количество операций в секунду, число активных клиентов и попадания в кэш. Мониторинг этих параметров помогает определить горячие ключи, оценить нагрузку и принять меры для масштабирования или оптимизации работы сервера.