Содержание статьи

В Python для выбора случайного элемента из списка чаще всего используют модуль random. Функция random.choice() возвращает один элемент напрямую, без необходимости вручную генерировать индекс. Для списков до 106 элементов задержка выполнения обычно не превышает миллисекунды.
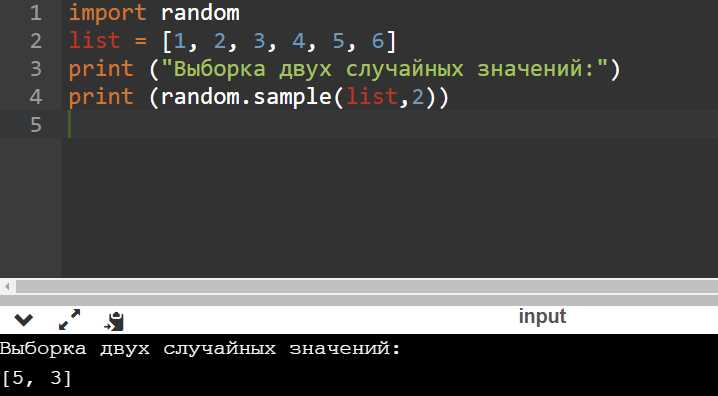
Если требуется выбрать несколько элементов без повторений, используют random.sample(). Она принимает два аргумента: список и количество элементов, и гарантирует уникальность результата. Для больших коллекций стоит учитывать, что время выполнения растет пропорционально размеру выборки.
Для ситуаций, где необходим контроль вероятности, подойдет random.choices(). Она позволяет назначить каждому элементу вес, что удобно при моделировании событий с разной вероятностью. Весовые коэффициенты задаются в виде списка чисел, сопоставленных элементам исходного списка.
В научных расчетах и при работе с массивами более 107 элементов используют numpy.random. Этот метод быстрее стандартного random и поддерживает генерацию сразу нескольких элементов с заданными распределениями.
Правильный выбор метода зависит от размера списка, необходимости уникальности элементов и требований к распределению вероятностей. Учет этих факторов позволяет избегать ошибок и повышает точность выборки.
Использование функции random.choice для одного элемента

Функция random.choice() возвращает случайный элемент из любого последовательного объекта: списка, кортежа или строки. Она работает за время O(1), поскольку обращается к элементу напрямую через индекс, сгенерированный случайным образом.
Пример использования: random.choice([10, 20, 30, 40]) вернет одно из чисел списка. Для строк random.choice(‘abcd’) возвращает один символ. Функция автоматически обрабатывает пустые последовательности, вызывая IndexError, что следует учитывать при динамически изменяемых списках.
Для повторного выбора одного элемента в цикле лучше сохранять исходный список и вызывать random.choice() на каждой итерации, вместо генерации нового списка. Это экономит память и ускоряет выполнение при больших коллекциях.
При тестировании или отладке рекомендуется использовать random.seed() для воспроизводимости результатов. Например, random.seed(42) перед вызовом random.choice() обеспечит одинаковую последовательность выбранных элементов при повторных запусках программы.
Выбор нескольких элементов с random.sample без повторений

Функция random.sample() позволяет выбрать несколько уникальных элементов из последовательности без повторений. Она принимает два аргумента: исходный список и количество элементов для выборки. Если размер выборки превышает длину списка, возникает ValueError.
Пример: random.sample([1, 2, 3, 4, 5], 3) может вернуть [2, 5, 1]. Порядок элементов в результате не совпадает с исходным списком, так как выборка случайная.
В таблице приведено сравнение поведения random.sample() в зависимости от размера выборки и исходного списка:
| Исходный список | Размер выборки | Пример результата | Комментарии |
|---|---|---|---|
| [10, 20, 30, 40, 50] | 2 | [30, 50] | Элементы уникальны, порядок случайный |
| [‘a’, ‘b’, ‘c’, ‘d’] | 4 | [‘b’, ‘d’, ‘a’, ‘c’] | Выбраны все элементы, перемешаны |
| [1, 2, 3] | 5 | – | Ошибка ValueError, размер выборки больше длины списка |
Для больших списков (>106 элементов) рекомендуется хранить список в памяти и вызывать random.sample() напрямую, так как копирование или сортировка перед выборкой увеличивает время выполнения. Для воспроизводимости результатов можно использовать random.seed().
Генерация случайного индекса через random.randint
Функция random.randint(a, b) возвращает случайное целое число в диапазоне от a до b включительно. Для выбора элемента из списка используют индекс от 0 до len(список) — 1.
Пример: index = random.randint(0, len(my_list) — 1), element = my_list[index]. Такой подход позволяет дополнительно обрабатывать индекс перед выборкой, например, применять условия или фильтры.
Для больших массивов индексирование через randint может быть полезно при частых выборках, так как доступ по индексу выполняется за O(1). При многократном повторении выборки можно сохранять предыдущие индексы, чтобы избежать повторов без использования random.sample().
Рекомендуется комбинировать random.randint() с random.seed() для воспроизводимости случайных индексов в тестах и отладке алгоритмов.
Применение numpy.random для больших массивов

Модуль numpy.random оптимизирован для работы с массивами размером более 106 элементов. Он обеспечивает быстрый выбор случайных значений и поддерживает генерацию сразу нескольких элементов.
Основные методы:
- numpy.random.choice(a, size, replace=False) – выбирает size элементов из массива a. Параметр replace=False исключает повторения.
- numpy.random.randint(low, high, size) – генерирует массив случайных индексов для обращения к элементам исходного массива.
- numpy.random.seed(seed) – фиксирует генератор для воспроизводимости результатов.
Пример для массива из 107 элементов:
- Создание массива: arr = np.arange(10_000_000)
- Выбор 5 случайных элементов: selection = np.random.choice(arr, size=5, replace=False)
- Проверка уникальности: len(np.unique(selection)) == 5
При больших массивах использование numpy.random снижает нагрузку на память и ускоряет выборку по сравнению с random.sample(). Для многократных выборок рекомендуется генерировать массив индексов и обращаться к нему напрямую, чтобы избежать повторной работы генератора.
Случайный выбор с вероятностями через random.choices
Функция random.choices() позволяет выбирать элементы из последовательности с учетом весов. Она принимает аргументы: список элементов и список весов того же размера, где каждый вес определяет вероятность выбора соответствующего элемента.
Пример: random.choices([‘a’, ‘b’, ‘c’], weights=[0.1, 0.3, 0.6], k=5) вернет массив из 5 элементов, где ‘c’ выбирается чаще, чем ‘b’, а ‘b’ чаще, чем ‘a’. Аргумент k указывает количество элементов в выборке, повторы допустимы.
Если веса не заданы, функция работает как random.choice(), с равной вероятностью для всех элементов. Для числовых списков можно использовать веса, пропорциональные значению или частоте встречаемости элементов, что позволяет моделировать реальные распределения.
Для повторяемости результатов при тестировании следует использовать random.seed(). При больших выборках (>106 элементов) функция сохраняет производительность и не требует предварительного копирования списка.
Выбор элемента из списка словарей по ключу

При работе со списком словарей часто требуется выбрать элемент по значению определенного ключа. Для этого используют комбинацию функций random.choice() или random.choices() с извлечением значения через ключ.
Пример списка словарей:
- data = [{‘id’: 1, ‘name’: ‘Alice’}, {‘id’: 2, ‘name’: ‘Bob’}, {‘id’: 3, ‘name’: ‘Carol’}]
Выбор случайного словаря:
- item = random.choice(data)
- Получение значения ключа: name = item[‘name’]
Если требуется выбор нескольких значений с уникальностью, используется random.sample() с генерацией списка ключей:
- names = [d[‘name’] for d in data]
- selection = random.sample(names, k=2)
Для вероятностного выбора элементов словаря по ключу применяют random.choices() с параметром weights. Это полезно, когда один элемент должен выпадать чаще, чем другой, например при распределении пользователей по активности.
Случайный элемент из пустого или динамически изменяемого списка
Попытка выбрать элемент из пустого списка с помощью random.choice() или random.sample() вызывает IndexError. Для предотвращения ошибки необходимо проверять длину списка перед выборкой: if my_list: element = random.choice(my_list).
В динамически изменяемых списках, где элементы добавляются или удаляются во время работы программы, рекомендуется формировать выборку на момент запроса, а не хранить ранее выбранные индексы. Это предотвращает обращение к несуществующим элементам.
Пример безопасного выбора случайного элемента:
- if len(my_list) > 0:
- element = random.choice(my_list)
- else:
- element = None
Для многократных выборок из изменяемого списка удобно использовать генератор: (random.choice(my_list) for _ in range(k) if my_list). Он автоматически пропускает моменты, когда список пуст, и позволяет сохранять контроль над количеством выборок.
Сравнение методов по скорости на больших списках
При работе со списками размером более 106 элементов время выполнения выборки случайного элемента заметно различается в зависимости от метода. Функция random.choice() обеспечивает доступ за O(1) и подходит для одиночных выборок.
random.sample() эффективна для выборки нескольких уникальных элементов, но при больших k или длинных списках затраты памяти и времени растут, так как функция создает внутренние копии и проверяет уникальность.
random.randint() с индексированием позволяет выбирать элементы напрямую, что полезно при повторяющихся или условных выборках, особенно если требуется дополнительная обработка индексов.
numpy.random.choice() превосходит стандартные методы по скорости при генерации больших массивов элементов. На списках размером 107–108 элементов она может быть в 5–10 раз быстрее random.sample(), при этом поддерживая выборку с заменой и без.
Для многократных выборок рекомендуется профилировать методы на конкретных данных и использовать numpy.random, если важна скорость, или стандартные random-методы для простых и небольших списков.
Вопрос-ответ:
Как выбрать один случайный элемент из списка в Python?
Для выбора одного элемента используют функцию random.choice() из модуля random. Она принимает список или кортеж и возвращает один элемент. Пример: element = random.choice([10, 20, 30]). Если список пустой, функция вызовет IndexError, поэтому перед выборкой рекомендуется проверять длину списка.
Можно ли выбрать несколько элементов из списка без повторов?
Да, для этого применяют random.sample(). Она принимает исходный список и количество элементов, которые нужно выбрать. Функция гарантирует уникальность выбранных элементов. Например, random.sample([1, 2, 3, 4], 2) может вернуть [2, 4]. Если размер выборки больше длины списка, будет ошибка ValueError.
Как сделать так, чтобы один элемент выпадал чаще другого?
Используют функцию random.choices() с параметром weights. Каждый элемент списка получает числовой вес, который определяет вероятность его выбора. Например: random.choices([‘a’,’b’,’c’], weights=[0.1,0.3,0.6], k=5) — ‘c’ будет появляться чаще, чем ‘b’ и ‘a’. При этом повторения возможны, если k больше 1.
Что удобнее использовать для больших списков, random или numpy?
Для списков размером более миллиона элементов numpy.random работает быстрее и позволяет сразу генерировать несколько случайных значений. Например, np.random.choice(array, size=5, replace=False) выбирает несколько уникальных элементов из массива. Стандартные функции random подходят для небольших списков или единичных выборок.
Как безопасно выбирать элементы из динамически изменяемого списка?
При изменении списка во время выполнения программы необходимо проверять, что список не пуст. Для одиночного выбора используют условие: if my_list: element = random.choice(my_list). Для многократной выборки удобно использовать генератор с проверкой длины: (random.choice(my_list) for _ in range(k) if my_list). Это предотвращает ошибки при удалении всех элементов из списка.
Можно ли выбрать случайный элемент из списка словарей по определенному ключу и с разной вероятностью?
Да, для этого сначала формируют список значений нужного ключа, а затем используют функцию random.choices() с параметром weights. Например, есть список словарей: data = [{‘name’:’Alice’,’score’:10},{‘name’:’Bob’,’score’:20},{‘name’:’Carol’,’score’:30}]. Чтобы выбрать имя с вероятностью, пропорциональной очкам, можно сделать так: names = [d[‘name’] for d in data]; weights = [d[‘score’] for d in data]; selection = random.choices(names, weights=weights, k=1). Результат будет содержать одно имя, при этом имена с большим значением score выпадут чаще. Этот способ подходит для динамически изменяемых списков и позволяет легко управлять вероятностями без изменения исходной структуры данных.