Содержание статьи

Знание алгоритмов позволяет решать задачи с разными объемами данных без перерасхода ресурсов. Например, сортировка массивов с миллионами элементов требует выбора между быстрой сортировкой, сортировкой слиянием или пирамидальной сортировкой, чтобы уменьшить время выполнения и нагрузку на память.
При работе с поиском важно понимать разницу между линейным и бинарным поиском. Бинарный поиск на отсортированном массиве из 106 элементов сокращает количество сравнений с миллиона до примерно 20.
Графовые структуры встречаются в сетевых приложениях, маршрутизации и анализе данных. Владение алгоритмами поиска в глубину, поиска в ширину и алгоритмом Dijkstra позволяет находить кратчайшие пути и оптимальные маршруты для тысяч узлов.
Динамическое программирование используется для вычисления чисел Фибоначчи, оптимизации ресурсов и задач на подсчет вариантов. Правильная постановка подзадач и хранение промежуточных результатов сокращает время решения с экспоненциального до полиномиального.
Рекурсивные алгоритмы и бэктрекинг применяются для перебора комбинаций, разбиений и задач на поиск всех вариантов. Практическая реализация требует контроля глубины рекурсии и использования вспомогательных структур данных для хранения состояния.
Сортировки: выбор между быстрым, слиянием и кучей
Быстрая сортировка работает по принципу разбиения массива на элементы меньше и больше опорного значения. Для массивов до 105 элементов она показывает среднее время O(n log n). На отсортированных или почти отсортированных данных необходимо использовать случайный выбор опорного элемента, чтобы избежать худшего случая O(n2).
Сортировка слиянием разделяет массив на половины до единичных элементов и объединяет их обратно, упорядочивая. Она стабильно выполняется за O(n log n) и подходит для массивов больших размеров или связанных списков. Основной расход ресурсов – дополнительная память, примерно равная размеру массива.
Пирамидальная сортировка строит бинарную кучу из элементов массива и последовательно извлекает максимальный элемент. Для массивов с 106 элементов время работы составляет O(n log n), при этом сортировка выполняется на месте, без выделения дополнительной памяти.
Для практических задач рекомендуется использовать быструю сортировку для большинства массивов, слияние – когда важна стабильность или работа с потоковыми данными, а кучу – если требуется сортировка на месте с гарантированным временем работы независимо от исходного порядка.
Поиск: бинарный, интерполяционный и по шаблону
Бинарный поиск применяется к отсортированным массивам. Он делит массив пополам и сравнивает элемент с опорным, сокращая количество проверок с n до log₂(n). Для массива из 106 элементов потребуется около 20 сравнений.
Интерполяционный поиск улучшает бинарный, учитывая распределение данных. Если элементы равномерно распределены, количество сравнений приближается к log log n. На несбалансированных массивах эффективность падает до O(n).
Поиск по шаблону используется для строк и текстов. Основные методы:
- Алгоритм Кнута–Морриса–Пратта: строит префикс-функцию, сокращая повторные сравнения. Время работы O(n + m), где n – длина текста, m – длина шаблона.
- Алгоритм Бойера–Мура: использует сдвиги на основе последних символов. Эффективен при длинных шаблонах, особенно в больших текстовых файлах.
- Работа с регулярными выражениями: подходит для сложных шаблонов, но требует дополнительной обработки и может замедлять поиск при больших объемах данных.
Рекомендации для практики:
- Использовать бинарный поиск для отсортированных массивов с фиксированными элементами.
- Выбирать интерполяционный поиск, если данные распределены равномерно и количество элементов превышает 105.
- Применять алгоритмы поиска по шаблону для анализа текстов, логов и строковых данных, учитывая длину шаблона и размер текста.
Работа с графами: поиск в глубину и ширину, кратчайшие пути
Поиск в глубину (DFS) используется для обхода графа, выявления компонент связности и циклов. Реализуется рекурсией или стеком. Для графа с 104 вершин и 5·104 ребрами DFS выполняется за O(V + E), где V – количество вершин, E – количество ребер.
Поиск в ширину (BFS) применяется для нахождения кратчайшего пути в невзвешенных графах. Использует очередь и посещение соседей по уровням. Время работы аналогично DFS: O(V + E).
Алгоритмы кратчайших путей:
| Алгоритм | Применение | Время работы |
|---|---|---|
| Dijkstra | Графы с неотрицательными весами ребер | O(V²) для матрицы смежности, O(E + V log V) с кучей Фибоначчи |
| Bellman-Ford | Графы с отрицательными ребрами, проверка на отрицательные циклы | O(V·E) |
| Floyd-Warshall | Поиск кратчайших путей между всеми парами вершин | O(V³) |
Для практических задач рекомендуется использовать DFS и BFS для анализа структуры графа и поиска маршрутов в невзвешенных графах. Dijkstra подходит для маршрутизации и сетевых задач с положительными весами, Bellman-Ford – для финансовых и логистических моделей с возможными отрицательными значениями, а Floyd-Warshall – для полного анализа всех путей при небольших графах.
Структуры данных: стек, очередь, хэш-таблица на практике

Стек реализует принцип LIFO (последний вошёл – первый вышел). Используется для отмены действий в редакторах, обхода деревьев и реализации рекурсии без системного стека. Для массива из 105 элементов операции push и pop выполняются за O(1).
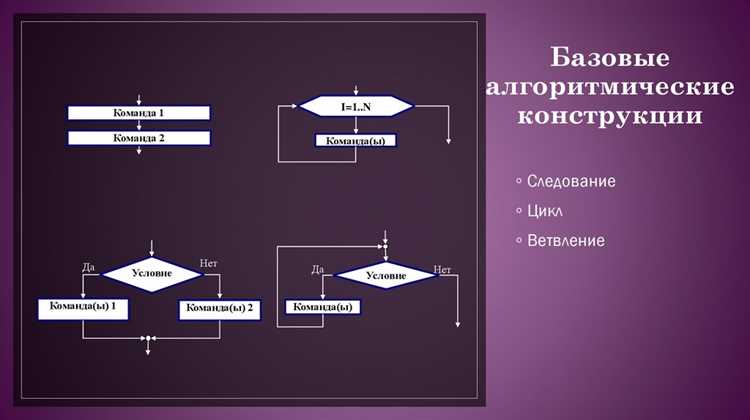 реализует принцип LIFO (последний вошёл – первый вышел). Используется для отмены действий в редакторах, обхода деревьев и реализации рекурсии без системного стека. Для массива из 105 элементов операции push и pop выполняются за O(1).»>
реализует принцип LIFO (последний вошёл – первый вышел). Используется для отмены действий в редакторах, обхода деревьев и реализации рекурсии без системного стека. Для массива из 105 элементов операции push и pop выполняются за O(1).»>
Очередь работает по принципу FIFO (первый вошёл – первый вышел). Применяется для планирования задач, обработки событий и потоков данных. Реализация с кольцевым буфером позволяет обрабатывать до миллиона элементов с константным временем вставки и удаления.
Хэш-таблица обеспечивает доступ к данным за O(1) в среднем. Используется для словарей, индексов баз данных и подсчета частот элементов. Важно выбирать качественную хэш-функцию и учитывать возможность коллизий, применяя методы цепочек или открытой адресации.
Практическая рекомендация: стек подходит для задач с обратным порядком обработки, очередь – для последовательной обработки событий, а хэш-таблица – для быстрого поиска, вставки и удаления элементов в больших объемах данных.
Динамическое программирование: задачи на оптимизацию и подсчет

Динамическое программирование (ДП) используется для разбиения задачи на подзадачи и хранения промежуточных результатов. Это сокращает время решения с экспоненциального до полиномиального. Пример: вычисление чисел Фибоначчи для n = 105 элементов вместо рекурсии выполняется за O(n).
Задачи на оптимизацию включают:
- Задача о рюкзаке: выбор предметов с максимальной стоимостью при ограничении по весу. Решение через ДП выполняется за O(n·W), где n – количество предметов, W – вместимость рюкзака.
- Редакционное расстояние: подсчет минимального числа операций для превращения одной строки в другую. Для строк длиной 1000 символов матрица ДП размером 1000×1000 позволяет вычислить результат за O(n·m).
Задачи на подсчет включают:
- Количество способов размена монет при фиксированной сумме.
- Подсчет уникальных маршрутов на сетке n×m.
Рекомендации: использовать ДП при наличии перекрывающихся подзадач, хранить результаты в массиве или хэш-таблице, минимизировать размер состояния, чтобы снизить расход памяти и ускорить вычисления.
Рекурсия и бэктрекинг: перебор вариантов и комбинаторика

Рекурсия позволяет решать задачи, которые естественно делятся на подзадачи одинакового типа. Пример: обход дерева с 104 узлов выполняется за O(n), где n – количество узлов, используя стек вызовов или явный стек для контроля глубины.
Бэктрекинг применяется для перебора всех возможных комбинаций с отсечением неподходящих веток. Пример: задача о N ферзях на шахматной доске 8×8 требует проверки 92 допустимых расстановок, вместо 4·1011 всех возможных вариантов.
Примеры практического применения:
- Генерация всех перестановок элементов массива.
- Поиск всех решений судоку или других головоломок.
- Комбинаторные задачи на выбор подмножеств с заданными свойствами.
Рекомендации: контролировать глубину рекурсии, использовать массивы для хранения текущего состояния, применять отсечение веток для уменьшения количества проверок. В задачах с большим числом вариантов предпочтительно комбинировать рекурсию с динамическим программированием для сокращения вычислений.
Вопрос-ответ:
Какие алгоритмы сортировки подходят для больших массивов?
Для массивов с сотнями тысяч и миллионами элементов практическая реализация включает быструю сортировку, сортировку слиянием и пирамидальную сортировку. Быстрая сортировка обычно быстрее на случайных данных, сортировка слиянием обеспечивает стабильность и подходит для связанных списков, а пирамидальная сортировка выполняется на месте и гарантирует O(n log n) независимо от исходного порядка.
Когда стоит использовать бинарный поиск вместо интерполяционного?
Бинарный поиск подходит для любых отсортированных массивов и всегда выполняется за O(log n). Интерполяционный поиск быстрее при равномерном распределении данных, так как количество сравнений сокращается почти до log log n. Если данные неравномерно распределены, бинарный поиск обеспечивает более предсказуемое время работы.
В каких задачах графовые алгоритмы находят практическое применение?
Поиск в глубину и ширину используется для обхода сетей, проверки связности и поиска циклов. Алгоритмы кратчайших путей, такие как Dijkstra, Bellman-Ford и Floyd-Warshall, применяются для маршрутизации, анализа логистики и сетевого трафика. Выбор алгоритма зависит от структуры графа и наличия отрицательных ребер.
Как динамическое программирование помогает решать комбинаторные задачи?
Динамическое программирование разбивает задачу на подзадачи и сохраняет промежуточные результаты, что уменьшает количество вычислений. Например, подсчет количества способов размена монет или нахождение числа уникальных маршрутов на сетке можно выполнить за полиномиальное время, вместо проверки всех комбинаций.
В каких случаях предпочтительно использовать бэктрекинг?
Бэктрекинг эффективен при поиске всех решений задач с ограничениями, таких как N ферзей, судоку или генерация перестановок. Он позволяет отсекать ветки, которые не приводят к корректным решениям, сокращая количество проверок. Рекомендуется контролировать глубину рекурсии и хранить текущее состояние в массиве для ускорения перебора.