Содержание статьи

Python предоставляет удобные инструменты для работы с файловой системой, что позволяет обрабатывать сразу несколько файлов в заданной директории без ручного открытия каждого из них. Основные подходы включают использование модуля os для навигации по папкам и модуля glob для фильтрации файлов по маске, например, *.txt или *.csv.
При работе с большим количеством файлов важно учитывать их размер и формат. Для текстовых файлов удобен метод open() с контекстным менеджером with, который автоматически закрывает файл после чтения. Для CSV или JSON рекомендуется использовать стандартные библиотеки csv и json, что обеспечивает корректное парсинг и обработку данных.
Если файлы необходимо обработать пакетно или в нескольких потоках, Python позволяет применять list comprehension для формирования списков путей и использовать concurrent.futures для параллельного чтения, что существенно ускоряет обработку при большом объеме данных. Практика показывает, что комбинирование фильтрации через glob и пакетного чтения через генераторы снижает потребление памяти.
Работа с файлами разных форматов в одной папке требует явного указания кодировки и проверки структуры данных перед обработкой. Для больших проектов полезно создавать функции, которые автоматически открывают файлы, проверяют их содержимое и возвращают готовые структуры данных, например, списки словарей или DataFrame библиотеки pandas.
Использование модуля os для перебора файлов в папке
Модуль os предоставляет функции для взаимодействия с файловой системой и позволяет эффективно перебирать файлы в папке. Основная функция для этого – os.listdir(path), которая возвращает список всех файлов и папок по указанному пути. Для фильтрации только файлов можно использовать проверку os.path.isfile(os.path.join(path, name)).
Пример перебора всех файлов в папке:
import os
path = '/путь/к/папке'
for filename in os.listdir(path):
full_path = os.path.join(path, filename)
if os.path.isfile(full_path):
print(filename)
Если требуется обрабатывать файлы с определённым расширением, удобно использовать метод str.endswith(). Например, для чтения только текстовых файлов:
for filename in os.listdir(path):
full_path = os.path.join(path, filename)
if os.path.isfile(full_path) and filename.endswith('.txt'):
print(filename)
Для рекурсивного перебора всех файлов во вложенных папках применяется os.walk(path). Она возвращает тройки (dirpath, dirnames, filenames), что позволяет одновременно получать путь, вложенные папки и файлы:
for dirpath, dirnames, filenames in os.walk(path):
for file in filenames:
print(os.path.join(dirpath, file))
Использование os эффективно для задач, где необходимо быстро получить список файлов, фильтровать по типу и организовать обработку нескольких файлов в папке, включая вложенные директории.
Чтение всех текстовых файлов с помощью glob
Модуль glob позволяет быстро получить список файлов в папке по заданному шаблону. Для работы с текстовыми файлами удобно использовать маску *.txt, чтобы выбирать только файлы с расширением .txt.
Пример базового использования:
import glob
for file_path in glob.glob('папка/*.txt'):
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
print(content)
Основные рекомендации при работе с glob:
- Использовать явное указание кодировки при открытии файлов (
utf-8или подходящую под ваши данные). - Для обработки большого числа файлов лучше читать их построчно, чтобы не загружать весь файл в память.
- Можно использовать рекурсивный поиск с
glob.glob('папка/**/*.txt', recursive=True), чтобы обрабатывать файлы в подкаталогах. - Если нужно работать с именами файлов без пути, применять
os.path.basename(file_path).
Для фильтрации по нескольким расширениям можно объединять результаты:
txt_files = glob.glob('папка/*.txt')
log_files = glob.glob('папка/*.log')
all_files = txt_files + log_files
Использование glob упрощает перебор файлов и интегрируется с другими инструментами Python, такими как os или pathlib, для более гибкой обработки данных.
Фильтрация файлов по расширению перед чтением
Для работы с файлами определённого типа в папке важно заранее отфильтровать их по расширению. В Python это можно сделать с помощью модуля os или glob. Например, функция os.listdir() возвращает все элементы папки, после чего с помощью проверки str.endswith('.txt') остаются только текстовые файлы.
При использовании glob.glob() фильтрация выполняется сразу при указании шаблона, например: glob.glob('папка/*.txt'). Это уменьшает количество ненужных операций и ускоряет чтение.
Для нескольких расширений удобнее применять генераторы или списковые включения: [f for f in os.listdir('папка') if f.endswith(('.txt', '.csv'))]. Такой подход позволяет гибко настраивать перечень поддерживаемых форматов и предотвращает обработку неподходящих файлов.
После фильтрации рекомендуется сразу проверять существование файлов и их доступность для чтения с помощью os.path.isfile() и попытки открытия в режиме 'r'. Это минимизирует ошибки во время обработки больших массивов данных.
При чтении больших файлов можно комбинировать фильтрацию с построчным чтением или использованием with open(), чтобы снизить нагрузку на память и ускорить обработку.
Открытие и построчное чтение больших файлов
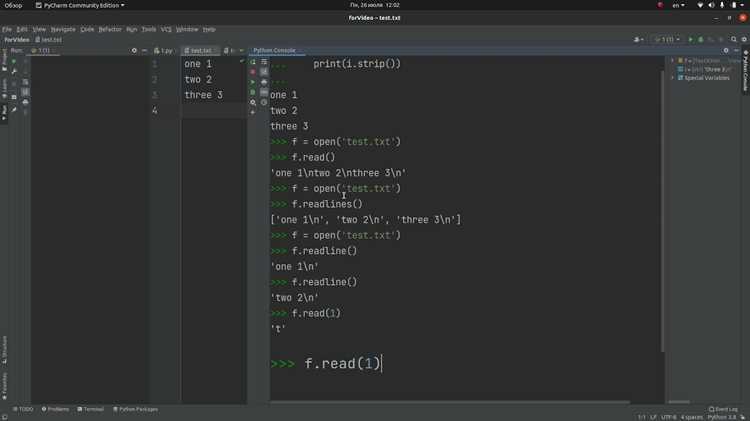
При работе с файлами размером в сотни мегабайт или гигабайты важно избегать загрузки всего содержимого в память. Python позволяет читать такие файлы по строкам, что минимизирует использование ресурсов.
Для открытия файла используют стандартную функцию open() с режимом чтения:
with open('filename.txt', 'r', encoding='utf-8') as file:
Использование контекстного менеджера with гарантирует автоматическое закрытие файла после завершения работы. Построчное чтение выполняется с помощью цикла:
for line in file:
Это позволяет обрабатывать каждую строку отдельно, что удобно для фильтрации данных или подсчета статистики без перегрузки памяти.
Если требуется хранить данные для последующей обработки, лучше использовать генераторы или писать результаты сразу в новый файл:
processed_lines = (line.strip() for line in file if line.startswith('INFO'))
Пример применения для подсчета количества строк и суммарного размера файлов:
| Файл | Строк | Размер (МБ) |
|---|---|---|
| log1.txt | 105234 | 12.5 |
| log2.txt | 230987 | 25.3 |
| log3.txt | 78912 | 8.7 |
Для ускорения чтения больших файлов можно использовать буферизацию, указав параметр buffering при открытии файла, либо применять модуль io для работы с потоками. Такой подход позволяет обрабатывать миллионы строк без заметного роста потребления памяти.
Чтение файлов в кодировке UTF-8 и обработка ошибок
При работе с текстовыми файлами в Python важно явно указывать кодировку. UTF-8 поддерживает большинство символов и рекомендуется для совместимости между платформами. Для чтения файла с указанием кодировки используется параметр encoding='utf-8':
with open('file.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
При чтении могут возникать ошибки декодирования, если файл содержит некорректные байты. Для их обработки используется параметр errors:
| Параметр | Описание |
|---|---|
strict |
Вызывает исключение UnicodeDecodeError при любой ошибке (по умолчанию) |
ignore |
Пропускает некорректные символы без прерывания работы |
replace |
Заменяет некорректные символы на � |
backslashreplace |
Заменяет некорректные символы на escape-последовательности |
Для безопасного чтения нескольких файлов в папке рекомендуется комбинировать обработку ошибок с циклом:
import os
path = 'folder/'
for filename in os.listdir(path):
if filename.endswith('.txt'):
try:
with open(os.path.join(path, filename), 'r', encoding='utf-8', errors='replace') as f:
data = f.read()
except Exception as e:
print(f'Ошибка чтения {filename}: {e}')
Использование errors='replace' позволяет продолжить обработку всех файлов, даже если часть содержимого содержит некорректные байты. Такой подход снижает риск прерывания программы и сохраняет максимальное количество информации из исходных файлов.
Использование pathlib для работы с путями к файлам
Модуль pathlib предоставляет объектно-ориентированный подход к работе с файловыми путями. Для чтения нескольких файлов в папке создайте объект Path для директории: dir_path = Path('путь/к/папке').
Метод iterdir() позволяет перебрать все элементы директории. Чтобы выбрать только файлы, используйте проверку item.is_file():
for file in dir_path.iterdir():
if file.is_file():
print(file.name)
Для фильтрации по расширению применяйте метод glob() или rglob() для рекурсивного поиска. Например, dir_path.glob('*.txt') вернёт все текстовые файлы в папке.
Объекты Path позволяют открывать файлы напрямую: with file.open(encoding='utf-8') as f:. Это упрощает чтение и обработку содержимого без необходимости объединять строки путей.
Методы name, suffix, stem и parent позволяют извлекать имя файла, расширение, имя без расширения и путь к родительской папке соответственно, что облегчает динамическую обработку множества файлов.
Для объединения путей используйте оператор /: full_path = dir_path / 'файл.txt', что гарантирует корректное формирование пути на любых операционных системах.
Сбор данных из нескольких файлов в один объект
Для объединения содержимого нескольких файлов в один объект в Python чаще всего используют списки или словари. Список подходит для последовательного хранения строк или блоков текста, словарь – для сопоставления имени файла с его содержимым.
Пример с использованием списка:
import pathlib
folder = pathlib.Path('папка_с_файлами')
all_data = []
for file in folder.glob('*.txt'):
with file.open(encoding='utf-8') as f:
all_data.extend(f.readlines())
В этом случае каждая строка всех файлов добавляется в один список all_data. Для объединения в словарь удобно использовать имя файла как ключ:
data_dict = {}
for file in folder.glob('*.txt'):
with file.open(encoding='utf-8') as f:
data_dict[file.name] = f.read()
Такой подход позволяет обращаться к содержимому конкретного файла по имени, упрощает фильтрацию и дальнейшую обработку данных.
При работе с большими файлами рекомендуется читать их построчно и сохранять блоками, чтобы не перегружать память. Для этого можно использовать генераторы или пакет itertools для последовательного объединения потоков данных.
Обработка исключений при чтении отсутствующих файлов
При работе с несколькими файлами часто возникает ситуация, когда часть файлов отсутствует. Игнорирование этого приводит к остановке программы. В Python для обработки таких случаев используется конструкция try...except.
Простейший пример обработки отсутствующего файла:
try:
with open('data.txt', 'r', encoding='utf-8') as f:
content = f.read()
except FileNotFoundError:
print('Файл data.txt не найден')
Рекомендуется использовать перебор файлов в папке с проверкой наличия перед открытием:
import os
folder = 'data'
files = ['file1.txt', 'file2.txt', 'file3.txt']
for filename in files:
path = os.path.join(folder, filename)
if os.path.exists(path):
with open(path, 'r', encoding='utf-8') as f:
data = f.read()
else:
print(f'Пропущен отсутствующий файл: {filename}')
Для массового чтения большого количества файлов полезно комбинировать try...except с логированием ошибок:
- Создавать список успешно прочитанных файлов.
- В отдельный лог записывать имена отсутствующих файлов и причины.
- Продолжать обработку остальных файлов без прерывания цикла.
Использование такого подхода повышает устойчивость скрипта и упрощает выявление проблем с недостающими файлами, особенно при автоматизированной обработке большого количества данных.
Вопрос-ответ:
Как открыть сразу все файлы с определённым расширением в папке с помощью Python?
Для этого можно использовать модуль glob, который позволяет находить файлы по шаблону. Например, чтобы открыть все файлы с расширением .txt, можно использовать код: import glob; files = glob.glob('путь_к_папке/*.txt'). После этого можно пройтись по списку файлов циклом и открыть каждый файл для чтения с помощью open(). Такой подход позволяет работать только с нужными файлами, исключая остальные.
Что делать, если один из файлов в папке отсутствует или повреждён?
При открытии файлов полезно использовать конструкцию try-except для перехвата ошибок. Например, try: open(file, 'r', encoding='utf-8') except FileNotFoundError: print(f"Файл {file} не найден"). Это предотвращает прерывание работы программы при ошибках и позволяет обработать такие случаи отдельно. Для повреждённых файлов можно добавить обработку UnicodeDecodeError, если файл не читается в указанной кодировке.
Можно ли объединить содержимое нескольких файлов в один список строк?
Да, это делается через последовательное чтение файлов в цикле и добавление содержимого в один список. Например: all_lines = []; for f in files: with open(f, 'r', encoding='utf-8') as file: all_lines.extend(file.readlines()). Такой подход собирает все строки из каждого файла в одном объекте, после чего можно проводить анализ или фильтрацию данных.
Как правильно работать с путями к файлам на разных операционных системах?
Модуль pathlib позволяет формировать пути к файлам независимо от ОС. Вместо ручного объединения строк с разделителями лучше использовать from pathlib import Path; folder = Path('путь_к_папке'); for file in folder.glob('*.txt'):. Такой код одинаково корректно работает на Windows, Linux и macOS, исключая ошибки с некорректными слэшами.
Есть ли разница между построчным чтением и чтением всего файла целиком?
Да, построчное чтение с помощью цикла for line in file: экономит память при работе с большими файлами, так как каждая строка обрабатывается по мере чтения. Чтение всего файла через read() загружает его полностью в память, что подходит для небольших файлов, но может вызвать переполнение памяти при больших объёмах данных.
Как прочитать все текстовые файлы в папке с помощью Python?
Для чтения всех текстовых файлов в папке можно использовать модуль glob. Сначала укажите путь к папке и шаблон файлов, например *.txt, чтобы выбрать только текстовые файлы. Затем с помощью цикла пройдитесь по списку найденных файлов и откройте каждый через open() для чтения содержимого. Альтернатива — использование модуля pathlib, который позволяет работать с объектами путей и фильтровать файлы по расширению с помощью метода Path.glob(). Такой подход упрощает обработку и делает код более наглядным.
Как объединить данные из нескольких файлов в один объект для дальнейшей обработки?
После открытия каждого файла его содержимое можно добавлять в общий список, словарь или строку, в зависимости от формата данных. Например, если в файлах строки с информацией, их можно считывать построчно и добавлять в список: all_lines.extend(file.readlines()). Для CSV-файлов удобнее использовать модуль csv и объединять строки в один список словарей. Такой метод позволяет работать с данными как с единым набором, а не обрабатывать каждый файл отдельно, что упрощает анализ или последующую запись в новый файл.