Race condition – это ситуация в многопоточных или распределённых системах, когда результат работы программы зависит от порядка выполнения операций. Чаще всего она возникает при одновременном доступе нескольких потоков к общей переменной или ресурсу без синхронизации. Ошибки такого типа могут привести к неконсистентным данным, сбоям и трудноуловимым багам.
Типичные примеры race condition встречаются при увеличении счетчиков, записи в файлы, работе с базами данных и кэшированными объектами. Даже простая операция вроде x = x + 1 становится опасной, если два потока выполняют её одновременно: оба могут прочитать одно и то же значение и записать одинаковый результат, игнорируя изменения друг друга.
Чтобы предотвратить ошибки, используют механизмы синхронизации: мьютексы, семафоры, атомарные операции и блокировки на уровне базы данных. При проектировании систем важно идентифицировать критические секции – участки кода, где возможен конфликт – и ограничивать доступ к ним. Контроль порядка выполнения потоков, а также тщательное тестирование под нагрузкой позволяют выявлять потенциальные race conditions до выхода в продакшн.
Дополнительная практика – использование статического анализа кода и специализированных инструментов, таких как ThreadSanitizer или Helgrind, которые обнаруживают гонки данных на этапе тестирования. Правильная организация доступа к общим ресурсам и строгое соблюдение принципов синхронизации снижает риск непредсказуемого поведения приложений.
Признаки race condition в многопоточных программах
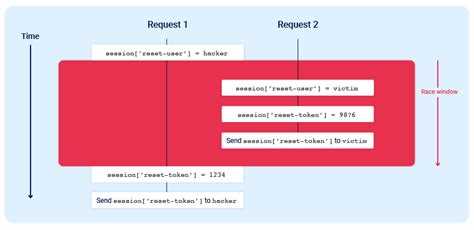
Race condition возникает, когда несколько потоков одновременно обращаются к общим ресурсам без корректной синхронизации, что приводит к непредсказуемым результатам. Основные признаки включают:
1. Непоследовательное поведение программы при одинаковых входных данных. Если запуск с одними и теми же параметрами иногда приводит к разным результатам, это сигнал о возможной race condition.
2. Внезапные сбои или исключения, особенно при обращении к общим переменным или структурам данных. Часто это проявляется в виде NullPointerException, IndexOutOfBoundsException или ошибок доступа к памяти.
3. Некорректное обновление данных. Когда несколько потоков одновременно модифицируют один ресурс, итоговые значения могут быть неожиданными или поврежденными.
4. Пропадающие события или некорректная обработка очередей. Если события не обрабатываются в ожидаемом порядке, это может указывать на конфликт потоков.
Для наглядного анализа можно использовать таблицу признаков и их проявлений:
| Признак | Проявление в программе | Вероятная причина |
|---|---|---|
| Непредсказуемый результат | Результат операций меняется при повторных запусках | Одновременный доступ к общим данным без блокировок |
| Сбои и исключения | Исключения доступа к null, массивам или памяти | Конкуренция потоков при чтении/записи |
| Поврежденные данные | Несоответствие значений переменных ожидаемым | Неатомарные операции с общими ресурсами |
| Пропавшие события | Сообщения или задачи не обрабатываются в порядке очереди | Перекрытие выполнения потоков без синхронизации |
Выявление признаков race condition требует мониторинга состояния потоков, логирования операций с общими ресурсами и тестирования с увеличенной конкуренцией потоков. Рекомендовано использовать специализированные инструменты анализа многопоточности для точного обнаружения конфликтов.
Типичные ошибки при одновременном доступе к данным
Другой распространённой ошибкой считается чтение данных в процессе их модификации. Поток может получить частично обновлённое значение, что приводит к логическим ошибкам и сбоям программы.
Использование неподходящих структур данных, не предназначенных для многопоточного доступа, также повышает риск race condition. Примеры включают обычные массивы и списки без блокировок при параллельной работе.
Отсутствие или неправильная настройка механизмов блокировки создаёт условия взаимоблокировки или потерю данных. Например, некорректное использование мьютексов может приводить к тому, что один поток блокирует ресурс на длительное время, мешая другим потокам.
Ошибки при комбинировании операций чтения и записи в одну транзакцию без атомарности часто приводят к расхождению данных. Даже если операции выполняются быстро, порядок их выполнения разными потоками может нарушить целостность.
Неправильное использование глобальных переменных или кэшированных значений, которые разделяются между потоками, может вызвать состояние гонки при обновлении и чтении одновременно. Рекомендуется применять локальные копии или атомарные операции.
Отсутствие тестирования с высокой степенью параллелизма скрывает потенциальные ошибки. Реальные условия многопоточности выявляют проблемы, которые невозможно обнаружить при последовательном выполнении.
Использование блокировок для предотвращения конфликтов

Блокировки обеспечивают последовательный доступ к разделяемым данным, предотвращая одновременные изменения потоками. Основные типы блокировок включают мьютексы, семафоры и читательско-писательские блокировки.
Мьютекс позволяет одному потоку захватить ресурс, блокируя другие до завершения операции. Он эффективен для критических секций с минимальным временем выполнения, но чрезмерное использование может вызвать взаимные блокировки.
Семафоры применяются для управления доступом к ограниченным ресурсам, например, пулу соединений. Их счетчик позволяет определенному числу потоков одновременно работать с ресурсом, предотвращая перегрузку.
Читательско-писательские блокировки разделяют доступ на чтение и запись. Несколько потоков могут одновременно читать данные, но запись блокирует всех читателей. Это повышает производительность при частых чтениях и редких записях.
Для правильного применения блокировок важно минимизировать время удержания, избегать вложенных блокировок и всегда использовать явное освобождение ресурсов. В языках с поддержкой синхронизации, например Java или C#, рекомендуется использовать конструкции try-finally или ключевое слово lock для автоматического управления блокировками.
Комплексная стратегия предотвращения конфликтов включает выбор подходящего типа блокировки, анализ точек конкуренции и тестирование в условиях высокой нагрузки. Это снижает вероятность race condition и повышает стабильность многопоточного приложения.
Синхронизация потоков через семафоры и мьютексы
Семафоры и мьютексы позволяют управлять доступом потоков к общим ресурсам и предотвращают race conditions. Мьютекс блокирует ресурс для одного потока, пока другой не завершит работу. Это гарантирует, что одновременно ресурс использует только один поток. В языках типа C++ или Java мьютекс реализуется через классы std::mutex или ReentrantLock.
Семафор позволяет ограничить число потоков, одновременно работающих с ресурсом. Например, семафор с максимальным счетчиком 3 разрешает трем потокам параллельно обращаться к ресурсу, остальные ждут освобождения. В Java семафоры реализуются через Semaphore, в C++ через сторонние библиотеки или std::counting_semaphore.
Для правильного использования важно всегда блокировать ресурс перед доступом и освобождать после завершения работы. Неправильное использование мьютексов и семафоров может привести к deadlock, когда потоки навсегда блокируют друг друга. Рекомендуется применять таймауты при ожидании или использовать вложенные блокировки с фиксированным порядком.
Практическая рекомендация: для защиты критических секций используйте мьютексы, когда нужен эксклюзивный доступ, и семафоры – когда ограничено число одновременных обращений. В многопоточных приложениях это снижает вероятность race conditions и делает выполнение операций предсказуемым.
Изоляция критических секций кода

Критическая секция – участок кода, доступ к которому одновременно может осуществлять более одного потока, что приводит к race condition. Изоляция таких секций гарантирует корректное выполнение операций с общими ресурсами.
Для эффективной изоляции применяются следующие подходы:
- Мьютексы (mutex): обеспечивают эксклюзивный доступ одного потока к ресурсу. Перед входом в критическую секцию поток блокирует мьютекс, после выхода – освобождает.
- Семафоры: позволяют ограничить число потоков, одновременно работающих с ресурсом. Для полной изоляции достаточно бинарного семафора.
- Блокировки чтения/записи: применяются при частых операциях чтения и редких модификациях данных. Потоки чтения могут выполняться параллельно, запись блокирует остальных.
- Мониторы и синхронизированные методы: встроенные механизмы языков программирования (например, synchronized в Java) автоматически блокируют объект на время выполнения критической секции.
Рекомендации по изоляции:
- Минимизировать длину критической секции, чтобы снизить время блокировки и уменьшить задержки потоков.
- Избегать вложенных блокировок, которые повышают риск взаимной блокировки (deadlock).
- Всегда освобождать блокировки в блоке finally или аналогичной конструкции, чтобы гарантировать снятие блокировки при ошибках.
- Использовать атомарные операции для простых случаев модификации переменных, что снижает необходимость полной блокировки.
Правильная изоляция критических секций снижает вероятность race condition, обеспечивает корректность данных и повышает предсказуемость работы многопоточных приложений.
Проверка и тестирование на условия гонки
Для выявления race conditions используют многопоточные стресс-тесты, которые создают высокую конкуренцию за ресурсы. Например, одновременный запуск 50–100 потоков с доступом к общему массиву или счетчику позволяет обнаружить нестабильное поведение.
Применяют инструменты динамического анализа, такие как ThreadSanitizer или Helgrind, которые отслеживают конфликтующие обращения к памяти и сигнализируют о потенциальных гонках. Рекомендуется запускать тесты с различными порядками выполнения потоков для увеличения вероятности обнаружения ошибок.
Автоматизированное тестирование включает симуляцию задержек между операциями чтения и записи, чтобы воспроизвести редкие состояния гонки. Практика показывает, что искусственные задержки в 1–10 мс значительно повышают вероятность выявления проблем.
Важно проверять как чисто кодовые критические секции, так и взаимодействие с внешними ресурсами: файловыми системами, базами данных и сетевыми соединениями. Для этого используют интеграционные тесты, которые комбинируют нагрузочные сценарии с проверкой целостности данных.
Регулярное применение unit-тестов с имитацией параллельного доступа помогает фиксировать ошибки на ранних этапах разработки. Тесты должны покрывать все функции, изменяющие общие данные, с повторным выполнением операций до 1000 раз для повышения вероятности проявления race condition.
Отчеты инструментов анализа и результаты стресс-тестов нужно документировать, включая количество потоков, последовательность операций и время возникновения конфликтов. Эти данные позволяют корректно настроить блокировки и мьютексы для устранения обнаруженных проблем.
Примеры исправления race condition в популярных языках

Race condition возникает, когда несколько потоков одновременно изменяют общие данные без синхронизации. Ниже приведены конкретные подходы к устранению таких ошибок на разных языках программирования.
- Java: Использование ключевого слова
synchronizedдля методов и блоков кода гарантирует, что только один поток выполняет критическую секцию в момент времени. - Пример:
class Counter { private int count = 0; cpppublic synchronized void increment() { count++; } public synchronized int getCount() { return count; } } - Python: Модуль
threadingпредоставляетLockдля защиты общих ресурсов. Все изменения данных внутриwith lock:выполняются атомарно. - Пример:
import threading counter = 0 lock = threading.Lock() def increment(): global counter with lock: counter += 1
- C#: Класс
lockблокирует доступ к объекту для других потоков до выхода из критической секции. - Пример:
class Counter { private int count = 0; private readonly object _lock = new object(); csharpCopy codepublic void Increment() { lock(_lock) { count++; } } public int GetCount() { lock(_lock) { return count; } } } - Go: Использование
sync.Mutexпредотвращает одновременное изменение переменных в горутинах. - Пример:
import "sync" var count int var mu sync.Mutex func increment() { mu.Lock() count++ mu.Unlock() } - JavaScript (Node.js): Так как однопоточный event loop предотвращает одновременное выполнение кода, race condition возможны при работе с асинхронными операциями. Решение – использовать атомарные операции или библиотеки, например
atomic-queue.
Во всех случаях ключевой принцип – явно ограничивать доступ к общим ресурсам и использовать средства синхронизации, предоставляемые языком. Игнорирование этих механизмов приводит к непредсказуемым результатам и трудноуловимым ошибкам.
Вопрос-ответ:
Что такое race condition и как она проявляется в многопоточных приложениях?
Race condition — это ситуация, когда результат работы программы зависит от порядка выполнения потоков или процессов. Проявляется она непредсказуемыми ошибками: данные могут повреждаться, счетчики или состояния объектов принимать неверные значения. Например, если два потока одновременно увеличивают один и тот же счётчик без синхронизации, итоговое значение может быть меньше ожидаемого.
Какие типичные ошибки приводят к возникновению race condition?
Основные ошибки включают: отсутствие блокировок при доступе к общим ресурсам, несогласованное использование переменных между потоками, чтение и запись данных без атомарных операций. Также частой причиной становятся нестандартные операции с памятью, когда один поток читает значение до того, как другой завершил запись. Все эти ситуации создают условия, при которых итог работы программы становится непредсказуемым.
Какие методы синхронизации потоков помогают предотвратить race condition?
Для предотвращения race condition применяются мьютексы, семафоры, блокировки на уровне объектов, атомарные операции и специальные структуры данных с поддержкой потокобезопасности. Мьютекс позволяет ограничить доступ к критической секции одному потоку, семафор — контролировать количество потоков, одновременно работающих с ресурсом. Атомарные операции гарантируют, что изменение значения произойдет полностью без прерывания другими потоками.
Как можно тестировать программу на наличие race condition?
Проверка включает запуск программы с высоким уровнем параллелизма и случайной задержкой потоков, что увеличивает шанс проявления ошибок. Используются статический и динамический анализ, инструменты вроде ThreadSanitizer или Helgrind, которые выявляют доступ к общим данным без синхронизации. Также полезно проводить нагрузочные тесты и создавать сценарии с одновременной записью и чтением общих ресурсов.
Можно ли полностью исключить race condition в сложных системах?
Полностью гарантировать отсутствие race condition сложно, особенно в системах с большим числом потоков и внешними зависимостями. Но их можно свести к минимуму, строго контролируя доступ к общим данным через синхронизацию, используя потокобезопасные структуры данных и избегая глобальных состояний. Применение модульного проектирования и ограничение взаимодействий между потоками также снижает вероятность возникновения таких ошибок.