Содержание статьи

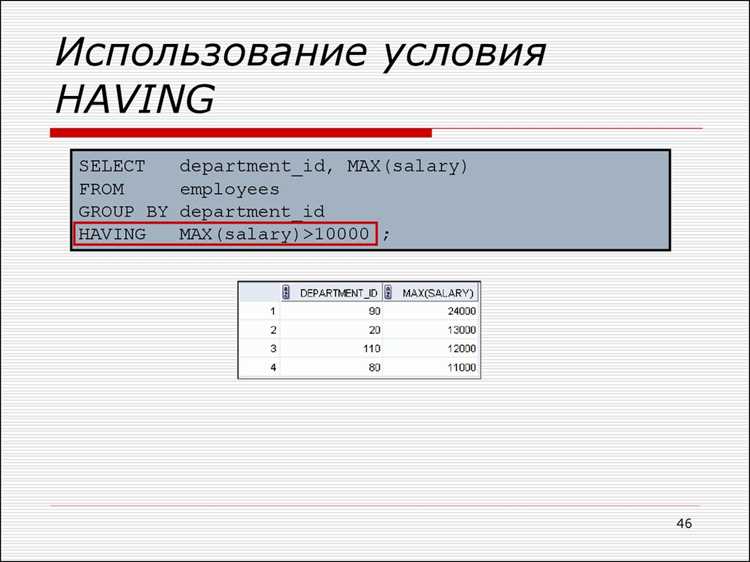
Выражение HAVING в SQL используется для фильтрации групп данных после применения агрегатных функций, таких как SUM, COUNT, AVG и других. Однако не все функции можно использовать напрямую в этом контексте. Попытка применить скалярные функции строк, даты или математические операции к отдельным строкам внутри HAVING приведет к ошибкам.
Оконные функции, например ROW_NUMBER() или RANK(), недоступны в HAVING, поскольку они обрабатываются после группировки, а HAVING работает на агрегированных данных. Аналогично, пользовательские функции или подзапросы, возвращающие несколько значений, вызывают ошибки при попытке их использования внутри HAVING.
Чтобы обходить эти ограничения, рекомендуется использовать вычисления в SELECT или CTE до группировки, а затем применять HAVING к результатам агрегатных выражений. Это позволяет фильтровать группы без нарушения логики SQL и минимизирует вероятность ошибок при работе с функциями, недоступными в HAVING.
Почему агрегатные функции работают в HAVING, а скалярные нет
Выражение HAVING обрабатывает данные после группировки, поэтому агрегатные функции, такие как SUM, AVG, COUNT, работают корректно. Они вычисляют значения на уровне групп, что соответствует логике HAVING: фильтровать уже агрегированные данные.
Скалярные функции, например UPPER, LOWER, LENGTH или операции с датами, возвращают результат для каждой строки. В контексте HAVING отдельные строки недоступны, поэтому использование таких функций приводит к ошибке или некорректным результатам.
Для фильтрации по результатам скалярных функций рекомендуется сначала вычислять их в SELECT или CTE, затем использовать агрегатные выражения или результаты вычислений в HAVING. Такой подход сохраняет корректность запросов и позволяет комбинировать группировку с необходимыми вычислениями.
Ограничения использования оконных функций в HAVING

Оконные функции, такие как ROW_NUMBER(), RANK() и LEAD(), вычисляют значения по отдельным строкам в пределах окна, определенного OVER. Поскольку HAVING применяется после группировки, отдельные строки уже агрегированы, и контекст окна теряется, что делает использование оконных функций невозможным.
Попытка вставить оконную функцию напрямую в HAVING вызовет ошибку выполнения. Вместо этого рекомендуется сначала вычислить значения оконной функции в подзапросе или CTE, а затем применять фильтрацию к агрегированным результатам. Это сохраняет возможность анализа позиций, рангов и кумулятивных сумм в рамках групп.
Пример правильного подхода:
| Шаг | Описание |
|---|---|
| 1 | Создать CTE, вычисляющий ROW_NUMBER() для каждой строки в пределах группы |
| 2 | В основной выборке использовать HAVING для фильтрации групп по агрегатным значениям |
| 3 | При необходимости фильтровать строки по номеру окна после агрегирования |
Такой подход позволяет совмещать анализ по окнам с фильтрацией групп без нарушения логики SQL и избегать ошибок в HAVING.
Почему функции строк и дат нельзя применять напрямую в HAVING

Выражение HAVING предназначено для фильтрации агрегированных данных. Функции строк и дат, такие как UPPER(), LOWER(), CONCAT(), DATEADD() или DATEDIFF(), работают на уровне отдельных строк, а не на группах. Прямое использование этих функций в HAVING приводит к ошибкам или некорректным результатам.
Рекомендации по работе с функциями строк и дат в контексте HAVING:
- Вычислять значения функций в SELECT или CTE до группировки.
- Использовать агрегатные функции поверх результатов, например MAX(UPPER(column)) или MIN(DATEDIFF(day, start_date, end_date)).
- Если требуется фильтрация по скалярной функции строки или даты, сначала создать промежуточную таблицу или подзапрос с вычисленными значениями.
Такой подход позволяет применять функции строк и дат к данным без нарушения логики HAVING и обеспечивает корректную фильтрацию агрегированных групп.
Проблемы с использованием подзапросов внутри HAVING
Подзапросы в HAVING могут создавать синтаксические и логические ошибки, так как HAVING обрабатывает агрегированные группы, а подзапросы часто возвращают наборы строк, которые не согласуются с уровнем агрегирования.
Основные ограничения:
- Подзапросы, возвращающие более одного значения, вызывают ошибку «subquery returns more than one row».
- Ссылки на столбцы из внешней группы без агрегатной функции или корреляции приводят к несоответствию контекста.
- Использование подзапросов с SELECT внутри HAVING снижает производительность из-за многократных вычислений для каждой группы.
Рекомендации:
- Вычислять необходимые подзапросы в CTE или промежуточных таблицах перед группировкой.
- Использовать агрегатные функции в подзапросе, чтобы результат был одной строкой на группу.
- Если требуется динамическая фильтрация, строить подзапрос как отдельное агрегированное выражение и соединять его с основной выборкой.
Следование этим правилам позволяет избежать ошибок и сохраняет корректность фильтрации групп через HAVING.
Невозможность применять пользовательские функции в HAVING

Выражение HAVING работает на уровне агрегированных данных, поэтому прямое использование пользовательских функций (UDF) часто приводит к ошибкам или неожиданным результатам. Пользовательские функции могут обрабатывать отдельные строки, возвращать таблицы или иметь побочные эффекты, что несовместимо с контекстом HAVING.
Ограничения и проблемы:
- Скалярные UDF, возвращающие значения для отдельных строк, не могут применяться напрямую к агрегированным группам.
- Табличные UDF, возвращающие несколько строк, создают конфликт с уровнем агрегирования и вызывают ошибки выполнения.
- Функции с побочными эффектами нарушают детерминированность HAVING и могут влиять на результаты группировки.
Рекомендации по использованию пользовательских функций в связке с HAVING:
- Вычислять значения UDF в SELECT или CTE перед группировкой.
- Использовать агрегатные функции поверх результатов UDF, например MAX(custom_function(column)).
- Для табличных функций применять JOIN или APPLY до группировки, а затем фильтровать группы через HAVING.
Такой подход позволяет интегрировать пользовательские функции в запросы с HAVING без нарушения логики SQL и минимизировать ошибки.
Почему некоторые математические функции не работают с HAVING
Выражение HAVING применяет фильтрацию на уровне агрегированных групп, поэтому функции, обрабатывающие отдельные строки, такие как POWER(), SQRT(), LOG() или ABS(), не могут использоваться напрямую без агрегирования. Эти функции возвращают результат для каждой строки, а HAVING видит только агрегированные значения.
Проблемы при использовании:
- Попытка применять функции к отдельным строкам внутри HAVING вызывает синтаксические ошибки.
- Функции с нестандартными или NULL значениями могут искажать результат группировки.
- Неправильное использование увеличивает нагрузку на сервер и снижает предсказуемость запроса.
Рекомендации:
- Вычислять математические функции на уровне SELECT или CTE перед группировкой.
- Использовать агрегатные функции поверх результата, например MAX(SQRT(column)) или SUM(ABS(column)).
- Для сложных выражений строить промежуточные таблицы с вычисленными значениями и фильтровать группы через HAVING.
Такой подход обеспечивает корректную фильтрацию агрегированных данных и совместимость с HAVING.
Особенности использования функций NULL и условий в HAVING
В HAVING обработка значений NULL отличается от обработки обычных числовых или строковых данных. Агрегатные функции, такие как SUM, COUNT или AVG, игнорируют NULL, тогда как скалярные функции и прямые сравнения с NULL вызывают ошибки или некорректные результаты.
Проблемы и ограничения:
- Выражения типа column = NULL всегда возвращают false, поскольку NULL требует использования IS NULL или IS NOT NULL.
- Скалярные функции, например COALESCE(column, 0), нельзя применять напрямую к каждой строке в HAVING без предварительного агрегирования.
- Комбинация условий с NULL и агрегатными функциями требует корректной логики, иначе группы будут неправильно отфильтрованы.
Рекомендации:
- Использовать агрегатные функции поверх выражений с NULL, например SUM(COALESCE(column, 0)).
- Для проверки на наличие пустых значений применять COUNT(column) = 0 или COUNT(column) > 0.
- Скалярные преобразования выполнять на этапе SELECT или CTE, затем фильтровать агрегированные результаты через HAVING.
Правильное обращение с NULL и условиями в HAVING позволяет избежать ошибок и обеспечивает точность фильтрации групп.
Обходные пути для функций, недоступных в HAVING

Когда стандартные функции недоступны в HAVING, можно использовать промежуточные вычисления и подзапросы, чтобы сохранить логику фильтрации без ошибок.
Возможные подходы:
- Создание CTE или подзапроса, где функции применяются на уровне отдельных строк, а затем использование агрегатных выражений в HAVING.
- Вычисление результатов функций в SELECT с последующей агрегацией, например SUM(COALESCE(custom_function(column), 0)).
- Использование JOIN или APPLY для интеграции табличных функций перед группировкой, чтобы HAVING применялся к агрегированным значениям.
- Для сложных условий формировать промежуточные таблицы с вычисленными столбцами и фильтровать группы через HAVING на основе этих столбцов.
Эти методы позволяют обходить ограничения HAVING, применяя функции и условия к данным без нарушения структуры агрегирования и предотвращая ошибки выполнения.
Вопрос-ответ:
Почему скалярные функции нельзя использовать напрямую в HAVING?
Выражение HAVING работает с агрегированными данными. Скалярные функции, например UPPER() или LENGTH(), обрабатывают отдельные строки. Прямое применение их в HAVING приведет к ошибкам, так как агрегированные группы уже не содержат информацию о каждой отдельной строке. Рекомендуется сначала вычислить результат функции в SELECT или CTE, а затем применять агрегатные выражения для фильтрации.
Можно ли использовать оконные функции внутри HAVING?
Нет, оконные функции, такие как ROW_NUMBER() или RANK(), не работают напрямую в HAVING. Они обрабатываются после группировки, а HAVING применяется к агрегированным данным. Для фильтрации на основе оконных функций следует использовать подзапросы или CTE, вычислив значения оконной функции до группировки.
Как обойти ограничения на использование функций строк и дат в HAVING?
Чтобы применять функции строк и дат, их сначала вычисляют на уровне SELECT или в CTE. После этого можно использовать агрегатные функции, например MAX(UPPER(column)) или MIN(DATEDIFF(day, start_date, end_date)), для фильтрации групп через HAVING. Такой подход позволяет корректно сочетать агрегирование с необходимыми вычислениями.
Почему подзапросы в HAVING вызывают ошибки?
Подзапросы могут возвращать несколько строк или ссылаться на столбцы вне контекста агрегированной группы, что несовместимо с HAVING. Чтобы избежать ошибок, подзапросы лучше выполнять в CTE или как промежуточные агрегированные таблицы. Затем можно фильтровать группы через HAVING по результату этих вычислений.
Как использовать пользовательские функции в запросах с HAVING?
Пользовательские функции (UDF) нельзя применять напрямую к агрегированным группам в HAVING. Для работы с ними вычисления выполняются на уровне SELECT или CTE, после чего результат агрегируется с помощью функций, таких как SUM или MAX, и фильтруется через HAVING. Такой подход предотвращает ошибки и сохраняет точность фильтрации.
Почему нельзя использовать скалярные и пользовательские функции напрямую в HAVING?
Выражение HAVING применяется после группировки и работает с агрегированными данными. Скалярные функции, например UPPER(), LENGTH(), а также пользовательские функции (UDF), возвращающие результат для каждой строки, не имеют доступа к отдельным элементам после агрегирования. Прямое использование таких функций вызывает ошибки или некорректные результаты. Чтобы обойти это ограничение, следует вычислять функции на уровне SELECT или в CTE, затем применять агрегатные функции, например SUM() или MAX(), и фильтровать группы через HAVING. Такой подход позволяет корректно фильтровать группы на основе вычисленных значений, не нарушая синтаксис SQL.