Содержание статьи

В Python матрицы могут быть представлены списками списков, массивами NumPy или таблицами pandas DataFrame. Для списков списков достаточно использовать len(), чтобы получить число вложенных списков, соответствующее количеству строк.
Для массивов NumPy точное количество строк определяется через array.shape[0]. Атрибут shape возвращает кортеж размерностей, где первая позиция показывает число строк, что удобно для интеграции в вычислительные алгоритмы.
В pandas DataFrame число строк можно узнать через len(df) или df.shape[0]. Этот метод учитывает все записи, включая пустые ячейки, и позволяет корректно оценивать объем данных перед фильтрацией или агрегацией.
При чтении данных из файлов, таких как CSV или текстовые таблицы, количество строк лучше подсчитывать построчно. Это обеспечивает точность даже при наличии пустых строк и позволяет формировать корректные структуры матриц для дальнейшей обработки.
Использование функции len() для подсчета строк

Функция len() позволяет быстро определить количество строк в матрице, представленной списком списков. Каждая вложенная структура считается отдельной строкой, поэтому достаточно вызвать len(matrix), чтобы получить точное число строк.
Этот метод работает независимо от длины строк или наличия пустых элементов. Например, если матрица содержит строки различной длины, len() вернет только количество вложенных списков, игнорируя их содержимое.
При обработке динамически формируемых матриц использование len() помогает избежать ошибок при индексации. Можно комбинировать подсчет строк с проверкой наличия данных в каждой строке, чтобы корректно фильтровать пустые или неполные элементы.
В сценариях с большими списками списков вызов len() не создает дополнительной нагрузки, так как функция возвращает уже известное количество объектов, что делает метод быстрым и надежным для подсчета строк перед дальнейшими вычислениями.
Определение строк через свойства массива NumPy
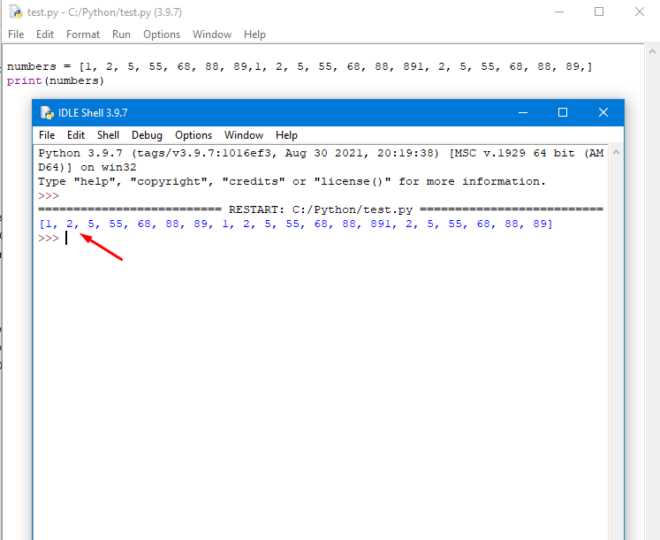
Для массивов NumPy количество строк определяется с помощью атрибута shape. Он возвращает кортеж, где первая позиция соответствует числу строк: rows = array.shape[0].
Метод работает для массивов любой размерности, включая двумерные и многомерные структуры. Даже если строки содержат разное количество элементов, shape[0] точно отражает количество строк.
При обработке больших массивов использование array.shape[0] предпочтительнее итеративного подсчета, так как возвращает значение напрямую без необходимости проходить по каждому элементу.
Этот подход особенно удобен при подготовке данных для математических операций и алгоритмов машинного обучения, где точное знание числа строк необходимо для корректного формирования входных и выходных матриц.
Подсчет строк в списке списков
В Python матрицы часто представляют как списки списков. Для подсчета строк существует несколько подходов, позволяющих учитывать структуру и содержимое матрицы.
- Простейший способ – использовать len(matrix), где matrix – список списков. Результат покажет количество вложенных списков.
- Если необходимо учитывать только непустые строки, можно использовать генератор: rows = sum(1 for row in matrix if row). Это исключает пустые списки из подсчета.
- Для фильтрации строк по длине элементов можно применить условие: rows = sum(1 for row in matrix if len(row) >= n), где n – минимальное количество элементов в строке.
Такие методы позволяют гибко подсчитывать строки, контролировать пустые и неполные данные и формировать точное представление структуры матрицы перед дальнейшей обработкой или визуализацией.
Проверка количества строк в DataFrame pandas

В pandas DataFrame количество строк определяется через свойства len(df) или df.shape[0]. Оба метода возвращают число записей в таблице, включая строки с пустыми ячейками.
Использование df.shape[0] особенно удобно при работе с фильтрацией и объединением таблиц, так как позволяет сразу получить число строк без необходимости проходить по каждой записи.
Для подсчета строк с конкретными условиями можно применять логические маски: rows = df[df[‘column’] > value].shape[0]. Такой подход позволяет точно учитывать только строки, соответствующие критериям анализа.
При обработке больших DataFrame использование этих свойств снижает нагрузку на память и ускоряет вычисления, так как методы возвращают значения напрямую без итерации по каждой строке.
Подсчет строк с условием заполненности
Для точного анализа матриц важно учитывать только строки с определенным количеством данных. В Python это можно реализовать через фильтрацию списков или использование библиотек NumPy и pandas.
Пример подсчета строк в списке списков, где заполнено хотя бы 3 элемента:
| Код | Описание |
|---|---|
rows = sum(1 for row in matrix if len([x for x in row if x is not None]) >= 3) |
Считает только строки, где количество непустых элементов больше или равно 3 |
Для NumPy используется логическая маска:
| Код | Описание |
|---|---|
rows = np.sum(np.count_nonzero(array, axis=1) >= 3) |
Считает строки с хотя бы 3 ненулевыми элементами |
В pandas можно применять метод dropna с порогом непустых значений:
| Код | Описание |
|---|---|
rows = df.dropna(thresh=3).shape[0] |
Оставляет только строки с минимум 3 заполненными ячейками и возвращает их количество |
Такой подход позволяет исключить неполные строки из анализа, что важно при подготовке данных для вычислений и визуализации.
Получение числа строк при чтении файла как матрицы

При работе с файлами, содержащими табличные данные, количество строк можно определить на этапе чтения. В Python для этого используют построчное чтение файлов и подсчет строк.
Для текстового файла с разделителями достаточно:
with open(‘file.txt’, ‘r’) as f:
rows = sum(1 for line in f if line.strip())
Этот метод учитывает только непустые строки, исключая пробелы и пустые строки.
Для CSV-файлов удобно применять модуль csv:
import csv
with open(‘file.csv’, newline=») as f:
reader = csv.reader(f)
rows = sum(1 for row in reader if any(row))
В pandas можно использовать pd.read_csv(‘file.csv’) и определить число строк через len(df) или df.shape[0]. Такой подход позволяет сразу получить точное количество строк для анализа и последующей обработки.
Обработка пустых или нерегулярных матриц
В NumPy массивы должны быть выровнены по размерности. Для нерегулярных данных можно использовать np.array(object, dtype=object) и подсчитать строки через array.shape[0], что вернет количество внешних элементов независимо от длины вложенных списков.
В pandas пустые строки можно игнорировать с помощью dropna или фильтрации по условию df[df.notna().any(axis=1)]. Это позволяет получить точное число реальных строк для анализа.
Такая проверка важна при загрузке данных из внешних источников или при динамическом формировании матриц, чтобы избежать ошибок при индексации и дальнейшей обработке данных.
Вопрос-ответ:
Как быстро узнать количество строк в обычном списке списков?
Для стандартного списка списков в Python достаточно использовать функцию len(). Она возвращает количество вложенных списков, которые соответствуют строкам матрицы. Например, len(matrix) даст точное число строк независимо от длины отдельных списков.
Можно ли определить число строк в массиве NumPy?
Да, у массива NumPy есть атрибут shape, где первая позиция показывает количество строк. Например, rows = array.shape[0] возвращает число строк даже при сложных многомерных массивах и не зависит от содержимого каждой строки.
Как учитывать только непустые строки при подсчете?
Если нужно исключить пустые строки, можно использовать генератор. Для списка списков: rows = sum(1 for row in matrix if row). В NumPy применяют логическую маску: rows = np.sum(np.count_nonzero(array, axis=1) > 0). В pandas можно использовать df.dropna(), чтобы оставить только строки с данными.
Как определить количество строк при чтении CSV-файла?
Можно использовать модуль csv и подсчитать строки через генератор: rows = sum(1 for row in csv.reader(f) if any(row)). В pandas после чтения файла через pd.read_csv(‘file.csv’) число строк определяется как len(df) или df.shape[0], включая только реальные записи.
Что делать, если матрица нерегулярная или содержит пустые строки?
Для списков списков нужно проверять, что каждый элемент является списком и не пустой: rows = sum(1 for row in matrix if isinstance(row, list) and row). В NumPy можно создавать массив с типом object, чтобы сохранить нерегулярные строки, а число строк брать через array.shape[0]. В pandas пустые строки фильтруют через dropna() или df[df.notna().any(axis=1)].