Содержание статьи

Эмпирическая функция распределения (ЭФР) позволяет визуализировать и анализировать данные, представляя их распределение по мере увеличения значений. ЭФР используется для оценки вероятности того, что случайная величина примет значение, меньшее или равное заданному. Этот инструмент является основой для многих статистических методов, таких как проверка гипотез или оценка параметров распределений.
Для построения ЭФР необходимо выполнить несколько последовательных шагов. Сначала нужно упорядочить наблюдения в выборке от наименьшего к наибольшему. Затем для каждого наблюдения вычисляется его позиция в отсортированном ряду, после чего эта позиция делится на общее количество элементов в выборке. Это значение и будет эмпирической функцией распределения для данного наблюдения. Формально для каждого элемента x выборки ЭФР рассчитывается по формуле: F(x) = (число элементов, меньших или равных x) / N, где N – общее количество элементов в выборке.
Для графического отображения ЭФР используйте ступенчатый график, где ось X будет представлять наблюдения, а ось Y – значение ЭФР для соответствующих элементов. Такой график наглядно покажет, как распределяются данные и где концентрируются наибольшие вероятности для различных интервалов значений. Важно помнить, что ЭФР является непрерывной для непрерывных распределений, но для дискретных выборок она будет ступенчатой.
При интерпретации эмпирической функции распределения важно учитывать количество данных. На маленьких выборках ЭФР может демонстрировать значительные колебания, тогда как на больших выборках она будет стремиться к гладкости, приближая истинную функцию распределения.
Сбор данных для построения эмпирической функции распределения
Для построения эмпирической функции распределения (ЭФР) необходимо собрать данные, отражающие исследуемое распределение. Важно учитывать, что выборка должна быть достаточно репрезентативной и отражать характер распределения переменной. Чтобы минимизировать ошибки, следует избегать предвзятости при выборе данных. Например, если исследуется доход населения, важно собрать информацию с разных социально-экономических групп, а не только из определенной категории.
Сбор данных может быть выполнен разными методами: от экспериментов до опросов. Для количественных переменных наиболее удобны такие источники, как статистика компаний, базы данных научных исследований или результаты экспериментов. Если данные представлены в виде выборки с известным распределением, то для получения ЭФР достаточно просто упорядочить наблюдения по возрастанию и посчитать их кумулятивные частоты. Однако для качественных данных, например, текстовых или категориальных, сначала потребуется их кодирование и преобразование в числовые значения.
- Объем выборки должен быть не менее 30-50 элементов для обеспечения статистической значимости.
- Необходимо учитывать, что распределение данных должно быть случайным, без явных зависимостей между наблюдениями.
- Проверка на полноту данных важна для исключения выбросов и пропущенных значений, которые могут исказить картину распределения.
Как выбрать границы интервалов для анализа распределения
Границы интервалов играют ключевую роль в построении эмпирической функции распределения, так как они определяют, как будут сгруппированы данные. При выборе интервалов важно учитывать характеристики исследуемых данных, такие как их диапазон, тип распределения и размер выборки.
Для начала, нужно определиться с числом интервалов. Стандартное правило гласит, что количество интервалов должно быть около 5-20, но для очень больших выборок можно выбрать до 30 интервалов. Это можно рассчитать с помощью формулы Стерджесса:
| Количество интервалов | Формула |
|---|---|
| k | k = 1 + 3.322 * log(n) |
где n – количество наблюдений. Эта формула дает приближенное значение, которое можно корректировать в зависимости от конкретных условий задачи.
После того как определено количество интервалов, следующим шагом будет выбор ширины интервала. Это зависит от диапазона данных и числа интервалов. Например, если выборка имеет диапазон от 0 до 100, и вы выбрали 10 интервалов, то ширина интервала составит 10 (100 ÷ 10). Если диапазон данных сильно варьируется, стоит выбрать более крупные интервалы для минимизации ошибок, связанных с мелкими колебаниями.
Важно также учитывать, что границы интервалов не должны пересекаться и должны быть четко определены. Практика показывает, что использование непрерывных, равномерных интервалов позволяет получить наиболее стабильную и точную картину распределения данных. Иногда полезно использовать логарифмические интервалы, если данные распределены экспоненциально.
Если данные содержат выбросы или высокую асимметрию, можно использовать метод, который адаптирует границы интервалов под особенности распределения. Например, метод Кука-Моффетта помогает лучше обрабатывать несимметричные распределения, улучшая точность эмпирической функции распределения в таких случаях.
Не забывайте проверять, как выбор границ интервалов влияет на интерпретацию результатов. Иногда полезно повторно проанализировать данные с разными интервалами, чтобы убедиться, что результаты анализа не зависят от субъективного выбора границ.
Вычисление частот для каждого интервала выборки
Для расчета частот в каждом интервале выборки необходимо сначала определить границы этих интервалов. Обычно для этого используется метод равных интервалов или метод Стёрджесса. После того как интервалы выбраны, нужно подсчитать, сколько элементов выборки попадает в каждый интервал. Частота интервала определяется как количество элементов в нем, деленное на общее количество элементов выборки. Такой подход позволяет оценить, как часто встречаются данные в определенном диапазоне значений.
Важно учитывать, что выбор размера интервала напрямую влияет на результат. Очень широкие интервалы могут скрывать важные закономерности в данных, а слишком узкие – привести к переоценке вариативности. При выборе интервалов следует опираться на размер выборки и характер распределения данных. Для этого можно применить метод автоматической подгонки интервалов с учетом плотности данных, например, алгоритм оптимизации через метод максимального правдоподобия, чтобы найти наиболее информативное распределение.
Нормировка данных для получения относительных частот
Нормировка данных представляет собой процесс приведения их к единому масштабу для вычисления относительных частот. Для этого важно правильно распределить значения в диапазоне от 0 до 1 или от 0% до 100%, в зависимости от контекста задачи. Это необходимо для того, чтобы результат мог быть интерпретирован как доля от общего объема, что позволяет корректно анализировать данные и строить эмпирическую функцию распределения.
Основной этап нормировки – это деление частоты каждого события на общее количество наблюдений. Например, если у нас есть 1000 наблюдений, а событие произошло 250 раз, то его относительная частота будет равна 0.25 или 25%. Это позволяет получить значение, которое отражает долю каждого события в контексте всего набора данных.
Перед нормировкой данных важно убедиться, что данные представляют собой целые числа или подходящие категории. Если данные не представлены в виде дискретных значений, их необходимо агрегировать. В случае непрерывных данных можно применить метод разбиения на интервалы (биннинг), чтобы получить дискретные значения, по которым затем будут вычисляться частоты.
Для корректности нормировки следует учитывать вес каждого наблюдения, если данные включают в себя переменные с разной значимостью. Например, если определенные данные представляют собой более важные наблюдения, их частота может быть увеличена в процессе нормировки. Это обеспечит более точную оценку относительных частот для разных категорий.
Нормировка данных также важна при анализе нескольких выборок или при сравнении групп с разными размерами. В таком случае необходимо скорректировать частоты для каждого набора данных, чтобы они были сопоставимы. Использование пропорций вместо абсолютных значений позволяет устранять эффект различий в объеме выборок и делает анализ более объективным.
После нормировки получаемые значения можно использовать для построения гистограмм, плотностей распределения и эмпирических функций распределения. Эти показатели предоставляют наглядное представление о распределении данных и позволяют оценить их характеристики, такие как асимметрия или куртозис, а также выявить возможные аномалии в наборе данных.
Построение эмпирической функции распределения по накопленным частотам
Процесс начинается с сортировки данных в порядке возрастания и вычисления частоты для каждой категории. Частота указывает, сколько раз данное значение появляется в выборке. Далее, на основе этих частот, можно вычислить накопленные частоты: для каждого значения \( X_i \) кумулятивная частота будет равна сумме частот всех значений, меньших или равных \( X_i \). Это даёт представление о том, как часто значения, не превышающие \( X_i \), встречаются в выборке.
Чтобы построить ЭФР, можно нанести точки на график, где по оси X откладываются значения данных, а по оси Y – соответствующие накопленные частоты, нормированные на общее количество наблюдений. Рекомендуется нормировать накопленные частоты, так как это позволяет получить функцию распределения, значения которой лежат в пределах от 0 до 1. Например, если в выборке 100 данных, то для каждой точки накопленная частота будет делиться на 100, чтобы отразить вероятность попадания случайной величины в диапазон до данного значения.
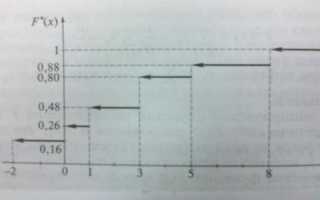
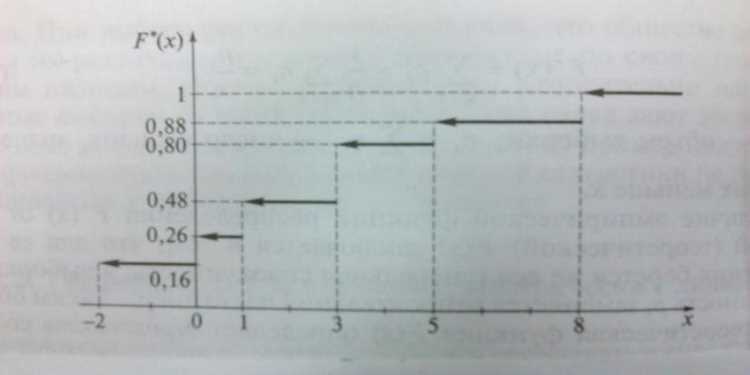
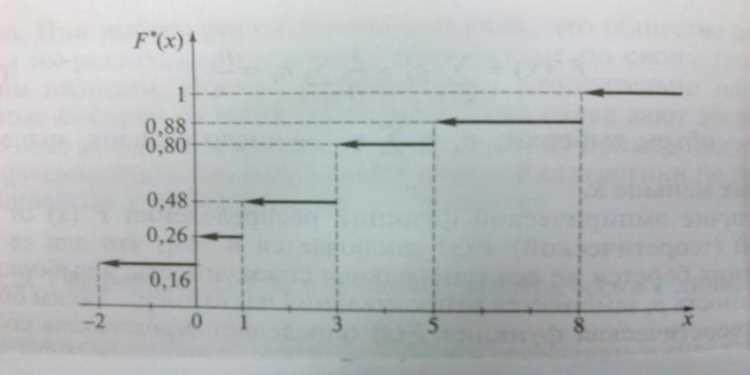
На графике ЭФР, построенном по накопленным частотам, можно визуализировать не только общую тенденцию распределения данных, но и выделить особенности, такие как возможные выбросы, асимметрии или пики. Этот подход часто используется для анализа нормальных и других типов распределений, а также для проверки гипотез о форме распределения данных. Важно помнить, что ЭФР является ступенчатой функцией, так как она отражает дискретную природу данных, и не имеет гладкости, характерной для теоретических распределений.
Применение графического метода для визуализации эмпирической функции распределения
Для построения графика эмпирической функции распределения, сначала необходимо упорядочить все наблюдаемые значения в выборке по возрастанию. Затем, для каждого значения x на оси X, на графике строится ступенька, высота которой соответствует доле наблюдений, меньше или равных этому значению. Ступенчатая линия визуализирует накопленные вероятности, что позволяет быстро оценить распределение данных.
Одной из ключевых особенностей такого метода является возможность выделить на графике участки с высокой плотностью значений. Например, если между двумя соседними ступеньками имеется значительный горизонтальный участок, это свидетельствует о том, что данные в этом диапазоне сконцентрированы. Визуализируя ЭФР таким образом, исследователь может выделить области с частыми значениями или же определить границы выбросов.
Для лучшего восприятия и точности анализа можно дополнительно нанести на график кривую эмпирической функции распределения. Это можно сделать с помощью интерполяции между точками ступеней, что даст более плавное и непрерывное представление о поведении данных. Однако стоит помнить, что такая кривая является приближением и не всегда корректно отражает реальные характеристики данных.
Кроме того, график ЭФР может быть использован для сравнения различных выборок. Наложение нескольких ЭФР на одном графике позволяет наглядно оценить различия в распределении данных. Этот метод полезен для анализа изменений в распределении при различных условиях или выборках с разными размерами.
Как оценить точность эмпирической функции распределения
Критерий Колмогорова-Смирнова вычисляется как максимальное абсолютное отклонение между функциями распределения, формально выражаемое как:
D_n = \sup_x | F_n(x) - F(x) |,
где F_n(x) – эмпирическая функция распределения, F(x) – теоретическая функция распределения, а sup – супремум, то есть наибольшее значение отклонения. Чем меньше значение D_n, тем более точной является эмпирическая функция.
Другим способом оценки точности является использование метода бутстрэппинга, который заключается в повторной выборке с возвращением из имеющихся данных. Это позволяет построить распределение эмпирических функций для разных выборок и оценить доверительные интервалы для каждого значения функции распределения. Такой подход помогает наглядно оценить устойчивость эмпирической функции к изменениям в исходных данных.
Для более детальной оценки точности можно применить критерий Хи-квадрат. Он заключается в сравнении наблюдаемых и ожидаемых частот, что позволяет проверить, насколько эмпирическое распределение сходится с теоретическим. Для этого данные делятся на интервалы, а затем рассчитывается статистика Хи-квадрат, которая служит индикатором степени отклонения ЭФР от теории.
Не менее важным инструментом является анализ распределения отклонений между наблюдаемыми и теоретическими значениями. Можно использовать методичку с помощью, например, графиков ошибок, таких как графики Q-Q (квантиль-квантиль), которые позволяют визуально оценить отклонения и выявить системные ошибки в модели распределения.
Вопрос-ответ:
Что такое эмпирическая функция распределения и как её построить?
Эмпирическая функция распределения (ЭФР) — это статистическая функция, которая показывает, какая доля наблюдаемых значений случайной величины меньше или равна заданному значению. Построение ЭФР начинается с сортировки всех наблюдаемых значений в порядке возрастания. После этого для каждого значения вычисляется доля наблюдений, которые не превышают это значение. ЭФР может быть представлена графически, как ступенчатая линия, где высота каждой ступени соответствует накопленной доле данных.
Что такое статистическое наблюдение и как оно связано с эмпирической функцией распределения?
Статистическое наблюдение — это отдельная выборка или результат измерения какой-либо величины, который добавляется в набор данных. В контексте эмпирической функции распределения, каждое наблюдение помогает формировать общую картину распределения случайной величины. Число наблюдений, которые меньше или равны данному значению, используется для построения ЭФР. Таким образом, количество статистических наблюдений напрямую влияет на точность и форму эмпирической функции распределения.
Как вычислить значения эмпирической функции распределения для заданных точек?
Чтобы вычислить значение эмпирической функции распределения для заданной точки, нужно определить, сколько наблюдений из всего набора данных меньше или равно этой точке. После этого полученное количество делится на общее количество наблюдений в выборке. Например, если из 100 наблюдений 35 значений меньше или равны 10, то ЭФР в этой точке будет равна 35/100 = 0.35.
Можно ли построить эмпирическую функцию распределения для категориальных данных?
Да, эмпирическую функцию распределения можно построить и для категориальных данных. Для этого нужно посчитать, сколько раз каждая категория встречается в наборе данных, и затем вычислить долю этих категорий от общего числа наблюдений. Например, если в выборке из 100 объектов 30 принадлежат к категории «А», то эмпирическая функция распределения для категории «А» будет равна 30/100 = 0.3. Графически ЭФР для категориальных данных будет представлять собой ступенчатую линию, где высоты ступеней соответствуют долям различных категорий.
Какие преимущества использования эмпирической функции распределения по сравнению с теоретической?
Основное преимущество эмпирической функции распределения — это её способность точно отражать реальные данные, без предположений о форме распределения. В отличие от теоретической функции распределения, которая строится на основе предположений о распределении случайной величины (например, нормальном), эмпирическая функция не требует таких предположений и может использоваться для любых данных, независимо от их распределения. Это делает её более гибким инструментом для анализа реальных данных.