Содержание статьи

S2T маппинг (speech-to-text) представляет собой процесс преобразования аудиосигналов в текстовые данные с помощью алгоритмов машинного обучения. Основу таких систем составляют глубокие нейронные сети, обученные на тысячах часов аудиозаписей с разметкой. Ключевым фактором точности распознавания является качество обучающего корпуса и его разнообразие по акцентам, шумовым условиям и скорости речи.
Современные модели S2T используют комбинацию сверточных и рекуррентных сетей для извлечения признаков из аудиосигнала и построения последовательности вероятных слов. Настройка гиперпараметров, таких как размер окна анализа спектрограммы и шаг смещения, позволяет адаптировать систему под конкретные задачи, например, транскрибацию лекций, звонков службы поддержки или подкастов.
Для интеграции S2T в производственные процессы важно учитывать форматы входных данных. Моно- и стереозаписи с частотой дискретизации 16 кГц и 16-битным разрешением обеспечивают стабильную работу большинства моделей. Регулярная проверка метрик точности, таких как WER (Word Error Rate), помогает отслеживать деградацию модели при добавлении новых аудиофайлов или изменении акустической среды.
Принцип преобразования сигналов в текст через S2T
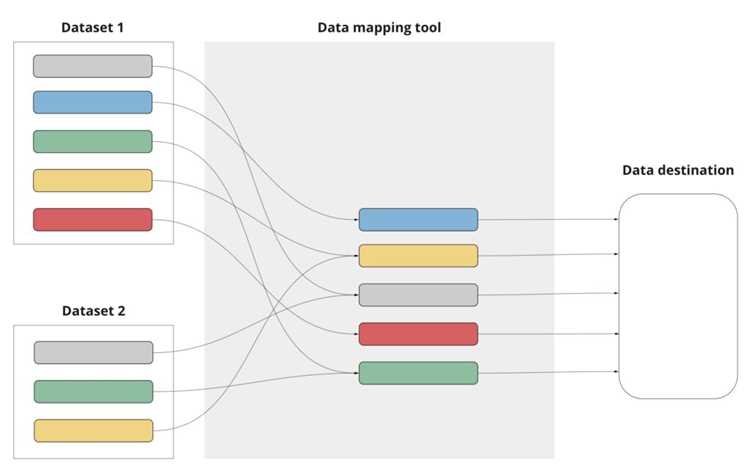
S2T маппинг начинается с захвата аудиосигнала и его преобразования в цифровой формат. Для этого используется частота дискретизации не менее 16 кГц и 16-битное разрешение, что позволяет сохранить диапазон речевых частот от 20 Гц до 8 кГц.
Далее аудиоданные обрабатываются в несколько этапов:
- Фильтрация шумов и подавление эхо с помощью алгоритмов спектрального вычитания.
- Разделение сигнала на короткие фреймы длительностью 20–40 мс с перекрытием 50%, чтобы сохранить временные характеристики речи.
- Преобразование каждого фрейма в спектрограмму или мел-спектрограмму для визуализации амплитуды частот в зависимости от времени.
На следующем уровне применяются нейронные сети:
- Сверточные слои извлекают локальные частотные паттерны, характерные для фонем и слогов.
- Рекуррентные или трансформерные слои моделируют последовательность фреймов, обеспечивая правильный порядок слов.
- Декодер преобразует вероятности фонем или слов в текстовую последовательность, используя языковые модели для исправления ошибок и предсказания пропущенных элементов.
Для повышения точности рекомендуется:
- Использовать корпус обучающих данных с разнообразием акцентов и шумовых условий.
- Регулярно оценивать WER (Word Error Rate) на контрольной выборке.
- Настраивать параметры спектрограммы и длину фреймов под конкретные типы аудиоматериала, например звонки кол-центра или лекции.
Использование нейронных сетей для распознавания речи
Сверточные слои применяются к спектрограммам для выявления локальных частотных паттернов, связанных с фонемами и интонацией. Рекуррентные слои, такие как LSTM или GRU, обрабатывают последовательность фреймов, удерживая контекст и улучшая распознавание слов в длинных предложениях.
Трансформерные модели используют механизм внимания для одновременного анализа всех фреймов и построения вероятностей слов, что снижает накопление ошибок в длинных аудиопотоках. Для оптимальной работы важно настраивать размер скрытых слоев и количество голов внимания под конкретные типы аудиозаписей.
Рекомендации по использованию нейронных сетей в S2T:
- Обучать модели на корпусах не менее 1 000 часов аудио с разметкой для стабильного распознавания.
- Использовать аугментацию данных: шумы, реверберацию и изменения темпа речи для повышения устойчивости.
- Регулярно контролировать метрики WER и CER (Character Error Rate) для выявления деградации качества.
- Поддерживать обновление языковых моделей для корректной интерпретации новых терминов и имен собственных.
Настройка модели S2T под специфические голосовые данные

Для повышения точности распознавания конкретного голоса или группы говорящих применяется адаптация модели S2T. Первый шаг – сбор корпуса аудиозаписей с характеристиками голоса, акцентом и уровнем шума, соответствующими реальной задаче.
Далее выполняется тонкая настройка нейронной сети через дообучение на этом корпусе. Важно сохранять баланс между новыми и базовыми данными, чтобы не потерять универсальность модели. Рекомендуется использовать не более 20–30% новых данных относительно исходного корпуса для одного цикла дообучения.
При работе с голосами, отличающимися по тембру или скорости речи, полезно:
- Применять нормализацию амплитуды и коррекцию темпа аудиозаписей.
- Использовать аугментацию данных: добавление фона, реверберации, варьирование громкости.
- Настраивать параметры спектрограммы и длину фреймов для соответствия диапазону частот конкретного голоса.
- Регулярно оценивать WER на тестовой выборке с эталонным голосом.
Дополнительно рекомендуется интегрировать пользовательский словарь для корректной расшифровки специфических терминов, имен или аббревиатур, характерных для целевой группы говорящих.
Обработка шумного аудиопотока в S2T системах

Шумный аудиопоток снижает точность распознавания речи, поэтому S2T системы используют многослойную обработку сигналов. Первый этап – подавление фонового шума с помощью фильтров спектрального вычитания или алгоритмов Wiener, которые уменьшают постоянные и случайные шумы без искажения голоса.
Следующий этап – разделение аудиосигнала на фреймы 20–40 мс с 50% перекрытием для сохранения временной структуры речи. Для каждого фрейма создается спектрограмма или мел-спектрограмма, на которой нейронная сеть выделяет речевые паттерны, игнорируя шумовые пиксели.
Дополнительно применяются методы:
- Аугментация шумом при обучении модели, что повышает устойчивость к разным акустическим условиям.
- Адаптивная нормализация амплитуды, компенсирующая колебания громкости фонового шума.
- Многоканальная обработка, если доступны записи с нескольких микрофонов, что позволяет выделять сигнал речи через пространственное подавление шумов.
Для проверки качества распознавания шумного аудио рекомендуется использовать контрольные метрики WER и SNR, отслеживая снижение точности при увеличении уровня шума и корректируя фильтры и параметры модели в соответствии с типом записей.
Форматы входных и выходных данных для S2T
S2T (Speech-to-Text) маппинг требует строго определенных форматов для корректной работы модели. Входные данные представлены в виде аудиофайлов, а выходные – текстовыми транскрипциями.
Входные форматы:
- Формат аудио: WAV, FLAC, MP3. WAV и FLAC предпочтительны для высокой точности, так как поддерживают безсжатое качество.
- Частота дискретизации: 16 kHz или 44.1 kHz. Более низкая частота снижает точность распознавания, выше 44.1 kHz увеличение качества незначительно влияет.
- Количество каналов: моно. Стерео требуется конвертация в моно, иначе модель может неправильно интерпретировать звуковые потоки.
- Формат хранения: PCM 16-bit. Другие кодировки (например, 24-bit или float) допускаются, но могут требовать предварительной нормализации.
Выходные форматы:
- Текст: UTF-8, plain text. Поддерживаются специальные символы и пунктуация.
- JSON: структура включает поля
transcriptдля текста иconfidenceдля оценки точности распознавания. Рекомендуется для интеграции с приложениями. - Тайм-коды: необязательный элемент JSON-выхода. Указывает начало и конец каждой фразы, используется для субтитров или аналитики речи.
Для оптимальной работы S2T важно использовать аудио без шумов, с равномерным уровнем громкости и без резких клипов. Форматы должны строго соответствовать указанным требованиям, иначе возможно падение точности распознавания до 15–20%.
Метрики качества распознавания и их интерпретация

Качество S2T оценивается с использованием нескольких метрик, каждая из которых отражает конкретный аспект точности модели.
Основные метрики:
| Метрика | Описание | Интерпретация | Рекомендации |
|---|---|---|---|
| WER (Word Error Rate) | Доля слов с ошибками: вставки, удаления, замены. | WER 0.1–0.2 считается высоким уровнем точности; >0.4 указывает на необходимость дообучения или очистки аудио. | Снижать шум, нормализовать громкость, использовать аудио >16 kHz. |
| CER (Character Error Rate) | Доля символов с ошибками. | Полезна для языков с агглютинативной морфологией или длинными словами. CER <0.05 указывает на высокую точность. | Использовать корректные токенизаторы, проверять спецсимволы. |
| Accuracy | Процент правильно распознанных слов относительно общего числа слов. | Accuracy >90% для стандартной речи считается достаточной. Ниже 80% – сигнал для оптимизации модели. | Корректировать шумоподавление, адаптировать модель к домену. |
| Confidence Score | Модель оценивает вероятность правильного распознавания каждого слова. | Средний score <0.7 указывает на низкую надежность транскрипции, >0.9 – высокая уверенность. | Использовать threshold для фильтрации сомнительных слов, объединять с постобработкой. |
Для комплексной оценки рекомендуется использовать одновременно WER и Confidence Score, что позволяет выявить слабые сегменты аудио и корректировать модель под специфические условия записи.
Вопрос-ответ:
Что такое S2T маппинг и где он применяется?
S2T маппинг — это процесс преобразования аудиозаписи речи в текст. Он используется для автоматической транскрипции интервью, подкастов, лекций, голосовых команд и систем поддержки клиентов. Модель анализирует звуковой сигнал, выделяет фонемы и сопоставляет их с символами текста, формируя осмысленный транскрипт.
Какие требования к аудиофайлам для корректной работы S2T?
Для S2T предпочтительно использовать монофонические аудиофайлы формата WAV или FLAC с частотой дискретизации 16–44,1 кГц и PCM 16-bit кодировкой. Наличие шума, низкая громкость или искаженные частоты снижают точность распознавания. Стерео следует преобразовать в моно, чтобы избежать конфликтов между каналами.
Как S2T оценивает качество распознанного текста?
Для оценки применяются метрики WER, CER, Accuracy и Confidence Score. WER показывает процент слов с ошибками, CER измеряет ошибки на уровне символов, Accuracy отражает долю правильно распознанных слов, а Confidence Score указывает на вероятность корректного распознавания отдельных слов. Сочетание этих показателей помогает определить слабые участки аудио и выбрать оптимальные настройки модели.
Можно ли использовать S2T для языков с нестандартной грамматикой или редкими диалектами?
Да, но точность распознавания таких языков или диалектов обычно ниже. Модели требуют дополнительного обучения на специфических корпусах речи. Для улучшения результатов рекомендуется адаптировать словари, учитывать особенности фонетики и произношения, а также предварительно очищать аудио от фоновых шумов.
Какие форматы выходных данных поддерживает S2T и как их использовать?
Основные форматы выходных данных — plain text в кодировке UTF-8 и JSON. В JSON кроме транскрипта можно включать Confidence Score и тайм-коды для каждой фразы. Такие данные удобны для интеграции в приложения, создания субтитров или аналитики речи. Plain text подходит для быстрой визуальной проверки или хранения транскрипций без дополнительной структуры.
Какие ошибки чаще всего встречаются при распознавании речи в S2T?
Чаще всего возникают три типа ошибок: пропуск слов, замена слов другими и вставка лишних слов. Пропуски происходят из-за шумов или слишком тихой речи, замены — при схожем звучании слов или диалектных особенностях, вставки — когда фоновые звуки модель интерпретирует как речь. Для уменьшения ошибок используют шумоподавление, нормализацию громкости и обучение модели на специализированных наборах данных с похожим акцентом или темой.
Можно ли использовать S2T для потоковой речи в реальном времени?
Да, некоторые модели S2T поддерживают обработку аудиопотока с минимальной задержкой. Для этого используют буферизацию небольших фрагментов аудио и постепенную генерацию текста. Ограничения включают снижение точности при фоновых шумовых помехах и высокую нагрузку на вычислительные ресурсы. Оптимальная настройка требует выбора подходящей частоты дискретизации, моноформата и кратких интервалов обработки.