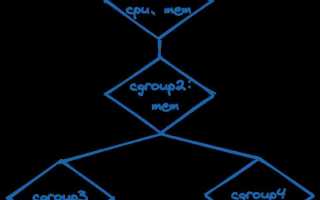
cgroups позволяют ограничивать, учитывать и приоритизировать ресурсы без изменения кода приложений. Ограничения задаются для CPU, оперативной памяти, swap, дискового I/O, сетевых операций и других параметров, а ядро контролирует их соблюдение в реальном времени. Процесс может быть привязан к группе при запуске или перемещён в неё во время работы, что упрощает администрирование нагруженных серверов.
На практике cgroups применяются при запуске сервисов через systemd, в контейнерных средах (Docker, Kubernetes), а также при изоляции пользовательских задач на shared-хостингах. Например, можно задать предел памяти для PHP-FPM пула, ограничить CPU для фоновых задач или не допустить, чтобы контейнер превысил выделенный лимит RAM и вызвал системный OOM.
Современные дистрибутивы используют cgroups v2, где управление ресурсами объединено в единую иерархию, а правила наследования стали строже и предсказуемее. Понимание принципов работы групп ресурсов помогает точнее настраивать systemd-сервисы, читать метрики нагрузки и находить причины нестабильности под высокой нагрузкой.
Linux cgroups: что это и как работают группы ресурсов
Каждая группа ресурсов связана с набором контроллеров. Контроллер – это модуль ядра, отвечающий за конкретный тип ресурсов. На уровне файловой системы cgroups представлены каталогами и файлами, через которые ядро получает параметры ограничений и возвращает статистику.
Основные возможности cgroups:
- установка верхних лимитов на использование CPU, памяти и дисковых операций;
- учёт фактического потребления ресурсов по каждой группе;
- разделение приоритетов между сервисами и контейнерами;
- изоляция системных и пользовательских процессов.
Работа cgroups строится на иерархии. Каждая группа может иметь дочерние группы, которые наследуют ограничения родителя. Процесс всегда принадлежит ровно одной группе в рамках каждого контроллера. При перемещении процесса в другую группу ядро сразу применяет новые правила без его перезапуска.
В актуальных системах используется cgroups v2, где все контроллеры объединены в одну иерархию. Это исключает конфликт настроек и упрощает контроль. Например, если группе задан лимит памяти, дочерние группы не могут превысить этот предел суммарно, даже если у каждой прописан собственный лимит.
Типичные контроллеры и их назначение:
- cpu – распределение процессорного времени и долей;
- memory – лимиты RAM и поведение при нехватке памяти;
- io – ограничения чтения и записи для блочных устройств;
- pids – ограничение количества процессов;
- cpuset – привязка групп к конкретным ядрам CPU.
На практике администратору редко приходится работать с cgroups напрямую. systemd автоматически создаёт группы для сервисов и сессий пользователей. Для точной настройки достаточно задать параметры в unit-файлах, например лимит памяти или долю CPU, после чего systemd передаёт эти значения ядру через cgroups.
Понимание устройства cgroups упрощает диагностику перегрузок: по счётчикам можно определить, был ли сервис остановлен из-за превышения лимита памяти, или почему контейнер стабильно недополучает процессорное время. Это делает cgroups базовым инструментом при эксплуатации серверов и контейнерных платформ.
Основная задача cgroups при работе с CPU – контроль распределения процессорного времени между сервисами и группами процессов. Ядро использует параметры долей и квот, чтобы одни группы не вытесняли другие при пиковой нагрузке. Например, через параметры cpu.weight и cpu.max можно задать относительный приоритет сервиса или жёсткий предел в процентах от одного или нескольких ядер.
Для памяти cgroups решают проблему неконтролируемого роста потребления RAM. Ограничение через memory.max задаёт верхний предел, после которого ядро начинает принудительное освобождение памяти или завершает процессы внутри группы. Это позволяет изолировать сбойные приложения и избежать системного OOM, когда из-за одного процесса падают все сервисы на узле.
Дополнительно cgroups позволяют управлять поведением при нехватке памяти. Параметры memory.swap.max и memory.high задают, можно ли группе использовать swap и при каком уровне давления ядро начнёт замедлять аллокации. Такой подход полезен для сервисов с предсказуемым профилем памяти, например баз данных или кэшей.
На практике ограничения CPU, памяти и I/O применяются совместно. Например, для контейнера можно задать лимит в 2 ядра CPU, 1 ГБ RAM и 20 МБ/с на запись, чтобы его поведение оставалось предсказуемым вне зависимости от нагрузки соседних контейнеров. Все ограничения применяются ядром немедленно и не требуют перезапуска процессов.
Использование cgroups при таких настройках позволяет администратору заранее задать границы потребления ресурсов, а не реагировать на перегрузки постфактум. Это упрощает планирование нагрузки, повышает устойчивость сервисов и снижает риск деградации всей системы из-за одного неконтролируемого процесса.
Как устроена иерархия cgroups и привязка процессов к группам
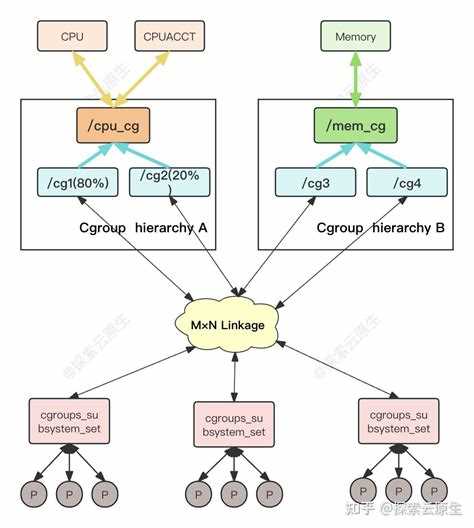
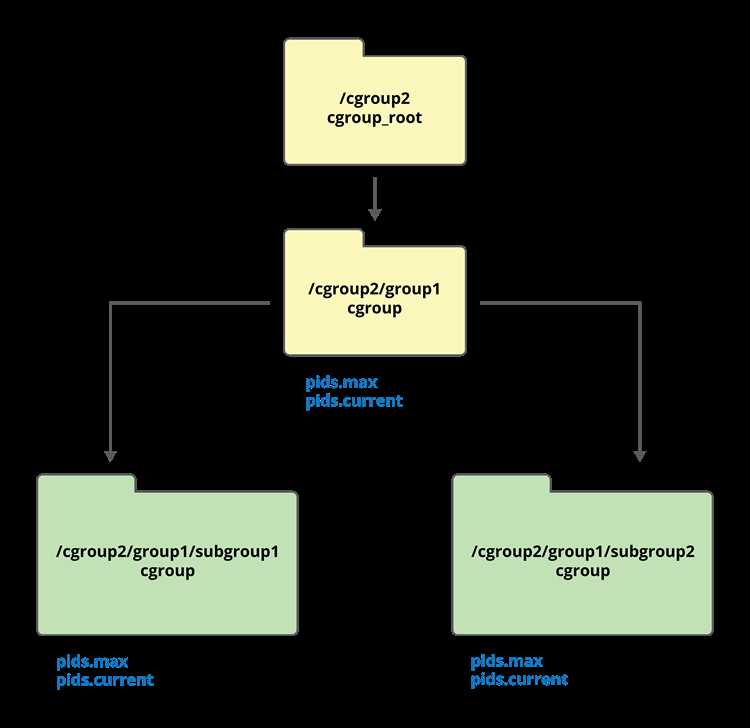
Каждая группа может иметь собственные параметры ресурсов, при этом дочерние группы наследуют ограничения родителя. Если родительской группе задан лимит памяти в 4 ГБ, все её дочерние группы суммарно не смогут превысить этот объём. Это правило используется для сегментации ресурсов между командами, пользователями или типами задач.
Привязка процесса к группе выполняется через специальный файл, в который ядро принимает PID. После записи идентификатора процесса он немедленно начинает подчиняться правилам выбранной группы. Один процесс может быть перемещён между группами во время выполнения, что позволяет динамически менять доступные ему ресурсы.
В рамках cgroups v2 процесс может принадлежать только одной группе в общей иерархии. Это устраняет расхождения, характерные для старой модели, где разные контроллеры могли использовать отдельные деревья. Благодаря этому все ограничения CPU, памяти и I/O применяются согласованно.
При запуске сервиса через systemd иерархия создаётся автоматически. systemd формирует группы для system.slice, user.slice и machine.slice, а каждый unit получает собственную подгруппу. Администратор управляет привязкой не через PID, а через unit-файлы, задавая параметры ресурсов на уровне сервиса.
Для ручного управления и диагностики используется просмотр текущей иерархии и списков процессов внутри групп. Это позволяет определить, к какой группе относится конкретный PID, какие лимиты на него действуют и почему процесс сталкивается с ограничениями при росте нагрузки.
Отличия cgroups v1 и cgroups v2 на уровне контроллеров ресурсов
В cgroups v1 каждый контроллер ресурсов монтируется в отдельное дерево, что позволяет управлять CPU, памятью, I/O и другими ресурсами независимо. Это создаёт возможность задавать разные ограничения для одного и того же процесса через разные контроллеры, но приводит к конфликтам при пересечении ограничений и усложняет управление иерархией.
cgroups v2 объединяет все контроллеры в единую иерархию. Процесс может принадлежать только одной группе в этой иерархии, и все ограничения применяются согласованно. Это исключает ситуации, когда процесс получает разные лимиты CPU и памяти в разных деревьях, упрощает прогнозирование нагрузки и обеспечивает предсказуемое поведение сервиса.
Основные различия в контроллерах:
- CPU: в v2 объединены параметры долей и квот, управление стало единым через cpu.max и cpu.weight;
- Memory: v2 поддерживает лимиты, high-watermark и swap для всех процессов группы в одной конфигурации, что предотвращает разногласия между деревьями;
- PIDs: контроль количества процессов стал встроенным в общую иерархию, упрощая отслеживание и предотвращение fork-бомб.
v2 также добавляет новые возможности: параметр memory.low для гарантированного объёма памяти, более строгую и предсказуемую обработку OOM и возможность упрощённого мониторинга через единый интерфейс. Для администраторов это означает меньше ошибок при настройке сервисов, контейнеров и системных ресурсов.
Как система начисляет и распределяет процессорное время между группами

В Linux cgroups распределение процессорного времени осуществляется через контроллер cpu. Ядро учитывает доли и квоты каждой группы и пропорционально распределяет CPU между ними. Каждая группа получает возможность использовать заданный процент времени процессора за определённый интервал, после чего её процессы ждут следующей очереди.
Основные параметры контроллера:
| Параметр | Назначение |
|---|---|
| cpu.max | Задаёт жёсткий лимит процессорного времени (микросекунды в периоде) |
| cpu.weight | Определяет относительный приоритет группы при распределении CPU |
| cpu.stat | Отображает фактическое использование процессорного времени процессами группы |
Распределение происходит по алгоритму пропорционального деления времени между активными группами. Если группа простаивает, её доля перераспределяется между активными группами. Это позволяет поддерживать баланс нагрузки даже при нерегулярной активности процессов.
Для администрирования можно использовать команды systemd или вручную редактировать файлы в /sys/fs/cgroup/cpu. Например, установка cpu.max=50000 100000 ограничивает группу до 50% одного ядра, а cpu.weight=200 повышает её приоритет по сравнению с другими группами с весом 100.
Мониторинг через cpu.stat позволяет отслеживать, насколько реально группа использует ресурсы и корректировать лимиты в случае дисбаланса. Это важно для контейнеров, сервисов с разной нагрузкой и сценариев, где один процесс не должен блокировать остальные.
Ограничение памяти и обработка OOM внутри cgroups
cgroups позволяют задавать жёсткие и мягкие лимиты памяти для групп процессов через контроллер memory. Основной параметр – memory.max, который ограничивает суммарное использование RAM процессами группы. При превышении этого лимита ядро инициирует действия по освобождению памяти или завершает процессы через OOM-киллер.
Дополнительно используются следующие параметры:
- memory.high – задаёт уровень «soft limit», при достижении которого ядро начинает замедлять аллокации, но не завершает процессы;
- memory.swap.max – ограничивает использование swap для группы;
- memory.low – гарантирует минимальный объём памяти, который группа сможет использовать даже при сильной нагрузке на систему.
При срабатывании OOM внутри cgroups процессы завершаются последовательно в рамках группы, а не всей системы. Это предотвращает падение критических сервисов и позволяет изолировать перегрузки.
Рекомендации по настройке:
- Задавать memory.max исходя из профиля приложения и доступной оперативной памяти хоста.
- Использовать memory.high для плавного управления потреблением без резкого завершения процессов.
- Мониторить статистику через memory.current и memory.stat для корректировки лимитов в реальном времени.
- Комбинировать с параметрами CPU и I/O, чтобы предотвратить ситуации, когда процессы ограничены только по памяти, но создают высокую нагрузку на другие ресурсы.
Правильная настройка памяти и OOM в cgroups позволяет создать предсказуемую среду для контейнеров и сервисов, минимизируя риск аварийного завершения процессов и деградации всей системы.
Практика использования cgroups в systemd и контейнерах
systemd использует cgroups для управления ресурсами сервисов и сессий пользователей. Каждый unit автоматически создаёт подгруппу в иерархии system.slice или user.slice, что позволяет задавать лимиты CPU, памяти и I/O через unit-файлы без ручного редактирования cgroup-файлов.
Примеры настройки unit-файлов:
- CPU: CPUQuota=50% ограничивает сервис до половины одного ядра.
- Память: MemoryMax=1G задаёт верхний предел RAM для процесса.
В контейнерных платформах, таких как Docker и Kubernetes, cgroups используются для изоляции ресурсов между контейнерами. Docker автоматически создаёт отдельную группу для каждого контейнера и применяет лимиты, заданные через параметры —cpus, —memory и —blkio-weight. Kubernetes использует cgroups через kubelet для enforce лимитов и requests ресурсов контейнеров.
Рекомендации по практическому использованию:
- Всегда указывать лимиты памяти и CPU для контейнеров, чтобы избежать непредсказуемого поведения на узлах с высокой нагрузкой.
- Использовать systemd для управления сервисами, когда необходима долговременная изоляция и мониторинг ресурсов.
- Комбинировать лимиты CPU, памяти и I/O для обеспечения предсказуемой производительности критических сервисов.
- Регулярно проверять фактическое использование ресурсов через systemd-cgtop или файлы в /sys/fs/cgroup для корректировки параметров.
Использование cgroups в связке с systemd и контейнерами позволяет создать стабильную и контролируемую среду, где ресурсы распределяются между сервисами и приложениями без ручного вмешательства и риска перегрузки хоста.
Вопрос-ответ:
Что такое cgroups и зачем они нужны в Linux?
cgroups (Control Groups) — это механизм ядра Linux для управления и изоляции ресурсов между группами процессов. Они позволяют ограничивать использование CPU, памяти, дискового ввода-вывода и других ресурсов, учитывать фактическое потребление и задавать приоритеты. С помощью cgroups можно предотвратить ситуацию, когда один процесс потребляет слишком много ресурсов, влияя на работу остальных сервисов.
Как cgroups ограничивают использование CPU для группы процессов?
Ограничение CPU выполняется через контроллер cpu. Для группы процессов задаются параметры cpu.max (жёсткий лимит процессорного времени) и cpu.weight (относительный приоритет). Ядро распределяет CPU пропорционально весам активных групп, а если группа простаивает, её доля перераспределяется между другими. Это позволяет поддерживать баланс нагрузки между сервисами и контейнерами.
В чем разница между cgroups v1 и cgroups v2 на уровне контроллеров?
В cgroups v1 каждый контроллер ресурсов создаёт отдельное дерево, и один процесс может иметь разные ограничения по CPU, памяти или I/O в разных деревьях. В cgroups v2 все контроллеры объединены в единую иерархию, и процесс может принадлежать только одной группе. Это упрощает управление ограничениями и делает поведение процессов предсказуемым при одновременном контроле CPU, памяти и ввода-вывода.
Как использовать cgroups на практике для контейнеров и systemd-сервисов?
В systemd каждый unit автоматически создаёт подгруппу в cgroups, где можно задать параметры CPU, памяти и I/O через unit-файл. Например, CPUQuota ограничивает процессорное время, а MemoryMax задаёт верхний предел RAM. В контейнерах Docker и Kubernetes cgroups применяются автоматически при указании лимитов через —cpus, —memory и параметры ресурсов в манифестах. Такой подход позволяет контролировать использование ресурсов, предотвращать перегрузки и обеспечивать стабильность сервисов.