Содержание статьи

Free OCR – это бесплатное программное обеспечение для распознавания текста на изображениях и сканированных документах. Оно поддерживает форматы TIFF, JPG, PNG и PDF, что позволяет работать с большинством современных файлов без дополнительного конвертирования. Программа использует технологию оптического распознавания символов, позволяя преобразовывать бумажные документы в редактируемый текст.
Основная функция Free OCR – быстрое извлечение текста из графических файлов с сохранением структуры документа. Программа особенно эффективна при работе с одноцветными сканами и документами с четким шрифтом. Для работы не требуется интернет-соединение, что обеспечивает конфиденциальность обработанных данных.
Процесс распознавания в Free OCR включает анализ изображения, выделение текстовых блоков, определение шрифта и символов. Пользователь может сразу копировать результат в буфер обмена или экспортировать в текстовый файл. Программа позволяет ускорить работу с большими объемами документов, минимизируя ручной ввод и ошибки при переносе текста.
Free OCR полезна для работы с архивами, сканами отчетов, квитанций и других бумажных документов. Рекомендуется использовать изображения с разрешением не ниже 200 dpi, чтобы повысить точность распознавания. Дополнительно программа может распознавать тексты на нескольких языках, включая русский и английский, что расширяет её сферу применения.
Free OCR: что это за программа и как работает

Работа Free OCR строится на последовательном анализе изображения: сначала определяется контраст и границы текста, затем программа выделяет блоки символов и сопоставляет их с внутренними шрифтами. Результат можно сразу копировать в буфер обмена или сохранять в формате TXT для дальнейшей обработки.
Программа эффективно справляется с документами с четким шрифтом и высоким разрешением сканов (рекомендуется не ниже 200–300 dpi). Для повышения точности распознавания Free OCR поддерживает настройку языка текста и коррекцию ориентации страниц. Пользователям доступны функции обработки отдельных областей изображения и пакетной обработки нескольких файлов одновременно.
Free OCR применяется для цифровизации отчетов, квитанций, научных статей и архивных документов. Она позволяет минимизировать ручной ввод текста, ускоряет работу с большими объемами информации и обеспечивает сохранение исходной структуры документа, включая абзацы и разделы.
Что такое Free OCR и для каких задач подходит
Free OCR подходит для цифровизации бумажных архивов, обработки отчетов, квитанций, научных публикаций и любых документов с текстовой информацией. Программа эффективна при работе с одноцветными сканами и документами с четким шрифтом, обеспечивая высокую точность распознавания.
Программа позволяет выбирать язык текста и корректировать ориентацию страниц, что повышает качество распознавания. Поддержка пакетной обработки файлов ускоряет работу с большими объемами данных, а возможность выделять отдельные области изображения позволяет извлекать только необходимую информацию.
Рекомендуется использовать сканы с разрешением не ниже 200–300 dpi. Free OCR обеспечивает сохранение исходной структуры документа, включая абзацы и разделы, что делает её удобной для последующего редактирования и анализа текста.
Поддерживаемые форматы изображений и PDF
Free OCR поддерживает работу с основными графическими форматами: JPG, PNG и TIFF. Эти форматы охватывают большинство сканов и фотографий документов, обеспечивая высокую совместимость при обработке текстовой информации. Для многостраничных документов программа обрабатывает PDF-файлы, включая сканированные и текстово-графические варианты.
При работе с изображениями рекомендуется использовать файлы с разрешением не ниже 200 dpi. Это повышает точность распознавания и минимизирует ошибки при идентификации символов. Для PDF-файлов Free OCR корректно обрабатывает страницы с разным разрешением и ориентацией, сохраняя структуру документа и последовательность страниц.
Программа позволяет извлекать текст не только из полностью текстовых PDF, но и из файлов, содержащих изображения с текстом. В случае сложных сканов рекомендуется предварительно улучшить контраст и очистить фон, чтобы повысить точность распознавания символов и сохранить форматирование исходного документа.
Установка Free OCR и требования к системе
Free OCR устанавливается на операционные системы Windows, начиная с версии Windows 7 и выше. Для работы программы требуется процессор с тактовой частотой не ниже 1 ГГц, оперативная память от 2 ГБ и минимум 100 МБ свободного места на жестком диске. Программа совместима с 32- и 64-битными системами.
Установка выполняется через стандартный установочный файл, скачанный с официального сайта. Процесс включает выбор папки для установки и создание ярлыков для быстрого запуска. Дополнительные компоненты не требуются, однако для корректного распознавания PDF-файлов необходимо наличие библиотеки поддержки PDF, которая обычно интегрирована в установщик.
Для оптимальной работы рекомендуется закрывать сторонние приложения при обработке больших файлов и обеспечивать стабильное питание компьютера. При необходимости обработки многостраничных документов можно использовать пакетный режим, который снижает нагрузку на систему и ускоряет обработку.
Как происходит распознавание текста шаг за шагом
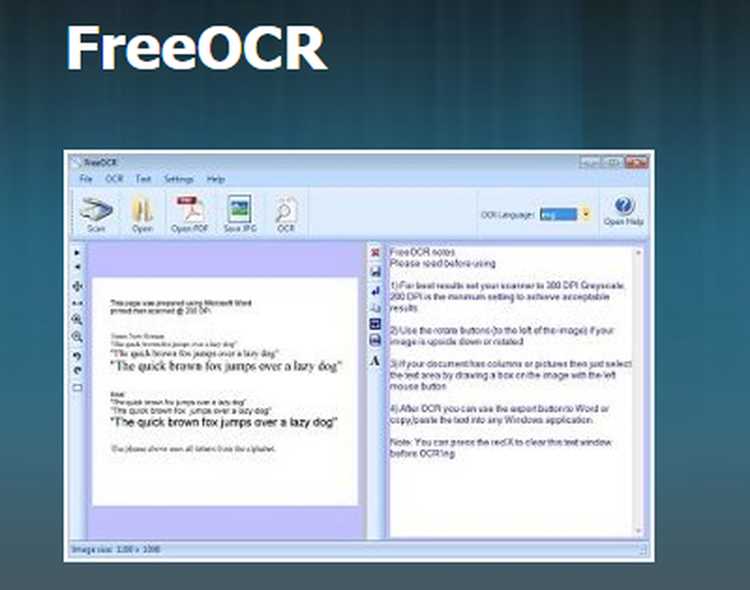
1. Загрузка документа. Пользователь выбирает изображение или PDF-файл. Free OCR поддерживает форматы JPG, PNG, TIFF и многостраничные PDF, что позволяет сразу обрабатывать разнообразные источники.
2. Предварительная обработка. Программа анализирует контраст, очищает фон и корректирует ориентацию страниц. Эта стадия критична для повышения точности распознавания символов.
3. Выделение текстовых блоков. Алгоритм определяет границы абзацев и отдельных слов, разделяя текст от графических элементов. Это позволяет сохранить структуру документа при дальнейшем экспорте.
4. Распознавание символов. Free OCR сопоставляет изображенные символы с внутренними шрифтами, определяет буквы и цифры, учитывая выбранный язык текста. Программа корректирует ошибки, возникающие при сканировании низкого качества.
5. Экспорт результата. Полученный текст можно скопировать в буфер обмена или сохранить в формате TXT. Программа сохраняет исходную структуру документа, включая абзацы, заголовки и разрывы страниц, что облегчает дальнейшее редактирование.
Языки распознавания и факторы точности

Free OCR поддерживает распознавание текста на нескольких языках, включая русский, английский, немецкий, французский и испанский. Выбор языка критически важен для корректного распознавания символов и сокращения ошибок при обработке документов.
Основные факторы, влияющие на точность распознавания:
- Качество изображения. Разрешение не ниже 200–300 dpi повышает точность идентификации символов.
- Контраст и четкость шрифта. Одноцветные сканы и четкий шрифт минимизируют ошибки.
- Ориентация и выравнивание текста. Программа корректирует наклон страниц, но предварительное выравнивание повышает точность.
- Язык текста. Настройка соответствующего языка позволяет программе правильно интерпретировать буквы и специальные символы.
- Сложность документа. Наличие таблиц, рисунков или сложного форматирования может снижать точность распознавания и требовать ручной проверки.
Для повышения эффективности рекомендуется использовать качественные сканы и при необходимости разделять документы на логические блоки, обрабатывая их отдельно. Free OCR позволяет корректировать ошибки после распознавания и сохранять текст в удобном для редактирования формате.
Форматы сохранения результата и способы экспорта
Free OCR позволяет сохранять распознанный текст в нескольких форматах и обеспечивает удобные способы экспорта для дальнейшей работы.
Основные форматы сохранения:
- TXT – простой текст без форматирования, удобен для последующей обработки и вставки в документы или базы данных.
- RTF – текст с базовым форматированием, сохраняются абзацы и разрывы строк.
- DOC/DOCX – совместимый с Microsoft Word, сохраняется структура документа, включая заголовки и абзацы.
Способы экспорта текста:
- Копирование в буфер обмена для вставки в другие приложения.
- Сохранение в файл выбранного формата через диалог сохранения.
- Пакетный экспорт для обработки нескольких документов одновременно, с сохранением последовательности страниц и структуры текста.
Рекомендуется использовать формат DOCX или RTF для документов с таблицами или сложной структурой, а TXT – для текстов без форматирования. При экспорте многостраничных PDF Free OCR сохраняет порядок страниц, что позволяет корректно работать с архивами и отчетами.
Ограничения Free OCR и типичные проблемы при работе
Free OCR имеет ряд ограничений, которые влияют на качество распознавания текста и скорость обработки документов. Понимание этих ограничений позволяет заранее подготовить документы и снизить количество ошибок.
Основные ограничения и типичные проблемы:
| Ограничение / Проблема | Описание | Рекомендации |
|---|---|---|
| Разрешение сканов | Документы с разрешением ниже 200 dpi распознаются с высокой вероятностью ошибок. | Использовать сканы с разрешением 200–300 dpi или выше. |
| Сложное форматирование | Таблицы, рисунки, графики могут искажать текст или блоки. | Выделять текстовые области отдельно, обрабатывать таблицы вручную при необходимости. |
| Разные языки на одной странице | Программа хуже распознает текст, если на одной странице несколько языков. | Обрабатывать страницы по языковым блокам или выбрать язык текста вручную. |
| Плохой контраст и шум на изображении | Фон, пятна, смазанные символы снижают точность распознавания. | Использовать программы для очистки и повышения контраста перед распознаванием. |
| Многостраничные PDF | При очень больших файлах возможна замедленная обработка или сбои. | Разбивать PDF на части и использовать пакетный режим обработки. |
Соблюдение рекомендаций позволяет повысить точность распознавания, сохранить структуру документа и минимизировать ручную корректировку после обработки.
Вопрос-ответ:
Что такое Free OCR и для чего его используют?
Free OCR — это программа для оптического распознавания текста на изображениях и сканированных документах. Она позволяет преобразовывать графические файлы в редактируемый текст. Программа применяется для работы с отчетами, квитанциями, научными статьями и архивными документами, что позволяет экономить время на ручной ввод информации.
Какие форматы файлов поддерживает Free OCR?
Программа поддерживает популярные форматы изображений: JPG, PNG, TIFF. Также можно работать с PDF, включая многостраничные файлы. Это позволяет обрабатывать как отдельные страницы, так и большие архивы документов без необходимости конвертирования в другие форматы.
Как повысить точность распознавания текста в Free OCR?
Для повышения точности рекомендуется использовать сканы с разрешением не ниже 200–300 dpi и четким контрастом. Важно выбирать язык текста в настройках программы, корректировать ориентацию страниц и при необходимости выделять отдельные текстовые блоки. Чистые изображения без пятен и смазанного текста снижают количество ошибок.
В каких форматах можно сохранять результаты распознавания?
Распознанный текст можно сохранить в формате TXT для простого текста без форматирования, в RTF с базовым форматированием или DOC/DOCX для работы в Microsoft Word. Free OCR также позволяет копировать текст в буфер обмена и использовать пакетный экспорт для нескольких документов одновременно.
С какими проблемами можно столкнуться при работе с Free OCR?
Типичные проблемы включают низкое разрешение сканов, сложное форматирование с таблицами или рисунками, наличие нескольких языков на одной странице, плохой контраст текста и фоновые шумы. При больших многостраничных PDF возможна замедленная обработка. Решение этих проблем включает улучшение качества изображений, разделение страниц по языкам и использование пакетного режима для больших файлов.
Можно ли распознавать текст на нескольких языках одновременно в Free OCR?
Free OCR поддерживает несколько языков, включая русский, английский, немецкий и французский. При работе с документами, где текст на нескольких языках, точность распознавания может снижаться. Рекомендуется обрабатывать страницы по языковым блокам или вручную выбирать язык текста для каждой части документа, чтобы минимизировать ошибки.
Как обрабатывать многостраничные PDF-файлы в Free OCR?
Программа позволяет загружать многостраничные PDF и обрабатывать их в пакетном режиме. Для улучшения точности рекомендуется разбивать большие файлы на отдельные части, проверять ориентацию страниц и использовать сканы с разрешением не ниже 200–300 dpi. После распознавания текст сохраняется с сохранением порядка страниц, что упрощает работу с отчетами и архивами.