Содержание статьи

Архитектура Nvidia Fermi была представлена в 2010 году и стала основой для вычислительных ускорителей Tesla, профессиональных карт Quadro и игровых видеокарт серии GeForce 400–500. Её ключевая особенность – поддержка compute capability 2.0, которая значительно расширила функциональность CUDA-ядер по сравнению с предыдущим поколением Tesla (1.x).
Compute capability 2.0 впервые ввела поддержку кэша L1 и L2, ускорила выполнение операций с двойной точностью и добавила возможность выполнения до 1024 потоков на мультипроцессор. Эти улучшения позволили Fermi применять не только для графических задач, но и для научных вычислений, моделирования и параллельных алгоритмов.
Для разработчиков CUDA знание compute capability важно при выборе инструкций, типов памяти и оптимизации кода под конкретную архитектуру. При работе с Fermi рекомендуется учитывать ограничения на количество регистров, размер кэша и доступные функции CUDA Toolkit, поддерживаемые версией 2.0.
Какая версия compute capability у архитектуры Fermi

Архитектура Nvidia Fermi соответствует версии compute capability 2.0. Эта версия впервые реализовала поддержку аппаратного кэша, расширенных регистров и параллельного выполнения инструкций, что повысило производительность при вычислениях общего назначения на GPU.
Модификации Fermi, использовавшиеся в более поздних моделях, например GF11x, имели compute capability 2.1. Она включала незначительные изменения в конфигурации потоковых мультипроцессоров и оптимизацию планировщика команд, сохраняя совместимость с кодом, написанным для версии 2.0.
При разработке приложений под CUDA рекомендуется использовать параметры компиляции -arch=sm_20 или -arch=sm_21 в зависимости от модели GPU. Это обеспечивает корректную работу кода и доступ к инструкциям, поддерживаемым архитектурой Fermi.
Определить compute capability конкретной видеокарты можно через официальную таблицу Nvidia CUDA GPUs или с помощью утилиты deviceQuery, входящей в состав CUDA Toolkit. Для карт GeForce GTX 400 и GTX 500 будет указано значение 2.0 или 2.1.
Какие модели видеокарт Nvidia относятся к архитектуре Fermi
Архитектура Fermi применялась в нескольких сериях видеокарт Nvidia, охватывающих игровые, профессиональные и вычислительные решения. Основой для всех моделей служили графические процессоры GF100, GF104, GF110 и их производные с compute capability 2.0 и 2.1.
К игровым видеокартам, построенным на архитектуре Fermi, относятся:
- GeForce GTX 400: GTX 480, GTX 470, GTX 465, GTX 460;
- GeForce GTX 500: GTX 580, GTX 570, GTX 560 Ti, GTX 560, GTX 550 Ti.
Для профессиональных задач на базе Fermi выпускались решения серий Quadro и Tesla:
- Quadro: 4000, 5000, 6000;
- Tesla: C2050, C2070, M2050, M2090.
GPU с compute capability 2.1 использовались в чипах GF114, GF116 и GF119, установленных в моделях GeForce GTX 560 Ti 448, GTX 560 SE, GT 545, GT 530 и других бюджетных картах. Эти версии сохраняли совместимость с CUDA-кодом Fermi, но имели оптимизированное энергопотребление и улучшенное распределение потоков.
При выборе GPU для вычислительных задач важно учитывать compute capability, так как она определяет поддержку инструкций CUDA и допустимые параметры ядра при компиляции.
Какие возможности предоставляет compute capability 2.0
Версия compute capability 2.0 ввела ряд аппаратных нововведений, которые сделали архитектуру Fermi пригодной для вычислительных задач высокого уровня. Основное отличие от предыдущих поколений – переработанная структура потоковых мультипроцессоров (SM), включающая по 32 ядра CUDA и три функциональных блока SFU для выполнения сложных математических операций.
Fermi с compute capability 2.0 поддерживает до 1024 потоков на один мультипроцессор, что позволяет выполнять больше параллельных вычислений при одинаковом объёме ресурсов. В архитектуре реализованы кэши L1 и L2, что уменьшает задержки при обращении к глобальной памяти и повышает стабильность выполнения потоков.
Поддержка операций с двойной точностью (FP64) стала стандартной, что расширило применение Fermi в научных и инженерных вычислениях. Добавлены функции атомарных операций для глобальной и разделяемой памяти, а также усовершенствована работа с текстурами и памятью постоянных данных.
Для программистов CUDA compute capability 2.0 открыла доступ к возможностям конфигурации блоков и сетей потоков, использованию до 63 регистров на поток и 48 КБ разделяемой памяти на SM. Эти параметры задаются при компиляции через флаги -arch=sm_20 и -code=sm_20.
Благодаря поддержке полного набора инструкций CUDA 4.x и оптимизированной иерархии памяти compute capability 2.0 стала основой для перехода к гибридным вычислительным системам на GPU.
Поддержка инструкций и особенностей CUDA в архитектуре Fermi
Архитектура Fermi реализует расширенный набор инструкций CUDA, соответствующий версии compute capability 2.0. Он включает поддержку операций с двойной точностью, атомарных функций, улучшенное управление памятью и возможность асинхронного выполнения потоков. Эти улучшения обеспечили совместимость с CUDA Toolkit версий от 3.0 до 5.0.
Fermi поддерживает выполнение инструкций IEEE-754-2008 для операций с плавающей запятой, включая округление и обработку переполнения. Расширен набор логических и битовых операций, добавлены функции работы с 64-битными целыми числами, а также инструкции для быстрого вычисления квадратного корня и обратного числа.
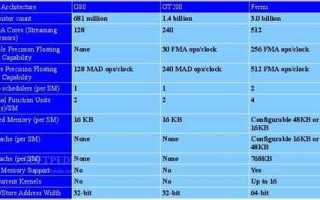
В таблице приведены ключевые особенности поддержки CUDA-инструкций в архитектуре Fermi:
| Функция | Поддержка в Fermi (2.0) | Описание |
|---|---|---|
| Double Precision (FP64) | Да | Арифметические операции с двойной точностью, ускоренные на уровне SM. |
| Atomic Operations | Да | Поддержка атомарных операций для глобальной и разделяемой памяти. |
| Concurrent Kernels | Да | Одновременное выполнение нескольких ядер CUDA на одном GPU. |
| Unified Address Space | Нет | Отсутствует объединённое адресное пространство CPU и GPU, добавлено в Kepler. |
| Texture and Surface Access | Да | Аппаратное ускорение работы с текстурами и поверхностями памяти. |
| ECC Memory | Да (Tesla) | Контроль и коррекция ошибок памяти на серверных GPU Tesla. |
Для компиляции кода под Fermi рекомендуется использовать архитектуру sm_20 или sm_21, чтобы активировать поддержку специфичных инструкций и моделей памяти. Это гарантирует корректное распределение ресурсов и использование всех возможностей архитектуры при работе с CUDA-приложениями.
Сравнение compute capability 2.0 с более поздними версиями

Compute capability 2.0, реализованная в архитектуре Fermi, ограничена 32 ядрами CUDA на потоковый мультипроцессор и поддержкой до 1024 потоков на SM. В версиях 3.x (Kepler) и 5.x (Maxwell) увеличено количество ядер на SM до 192–2048 и расширены возможности параллельного выполнения, включая улучшенные механизмы планирования потоков и управление энергопотреблением.
Поддержка операций с двойной точностью в 2.0 ограничена 1/8 от скорости операций с одинарной точностью, тогда как в Kepler (3.5) и Maxwell (5.2) коэффициент FP64 был повышен до 1/2 на профессиональных моделях, что ускоряет научные вычисления и задачи машинного обучения.
В compute capability 2.0 объём разделяемой памяти на SM ограничен 48 КБ, а кэш L1 можно конфигурировать на 16/48 КБ. В более поздних версиях память SM увеличена до 96 КБ, L1-кэш и L2-кэш получили улучшенные алгоритмы замены, что снижает задержки доступа и повышает пропускную способность.
Таблица основных различий:
| Особенность | Compute Capability 2.0 (Fermi) | Compute Capability 3.x/5.x (Kepler/Maxwell) |
|---|---|---|
| Ядра CUDA на SM | 32 | 192–2048 |
| FP64 производительность | 1/8 от FP32 | 1/2 от FP32 |
| Максимум потоков на SM | 1024 | 2048–4096 |
| Разделяемая память на SM | 48 КБ | 64–96 КБ |
| Кэш L1/L2 | 16/48 КБ конфигурируемо / 768 КБ L2 | 32–128 КБ L1 / 1–3 МБ L2 |
Для CUDA-разработчиков выбор compute capability влияет на использование оптимизаций ядра, управление памятью и планирование потоков. При работе с Fermi рекомендуется учитывать ограничения по числу регистров, разделяемой памяти и инструкциям, чтобы код оставался совместимым с более поздними архитектурами.
Как определить compute capability своей видеокарты Nvidia
Определение compute capability необходимо для правильной настройки компиляции CUDA-приложений и использования функций GPU. Наиболее точный способ – обратиться к официальной таблице Nvidia CUDA GPUs, где указана модель видеокарты и соответствующая версия compute capability.
Пример команды для Linux и Windows:
- Откройте терминал или командную строку.
- Перейдите в каталог CUDA Samples/bin.
- Запустите deviceQuery или deviceQuery.exe.
- Найдите строку CUDA Capability – например, 2.0 или 2.1 для Fermi.
Альтернативно можно использовать библиотеки CUDA в коде: функция cudaGetDeviceProperties возвращает структуру cudaDeviceProp, где поля major и minor соответствуют compute capability. Это позволяет программно проверять возможности GPU и выбирать оптимальные параметры ядра и память.
Вопрос-ответ:
Что такое compute capability в архитектуре Nvidia Fermi и зачем она нужна?
Compute capability — это версия архитектуры CUDA, определяющая набор поддерживаемых инструкций, доступное количество потоков, регистров и кэша на потоковый мультипроцессор. В Fermi эта версия 2.0 или 2.1, что позволяет использовать операции с двойной точностью, атомарные функции и до 1024 потоков на SM. Для разработчика CUDA знание compute capability важно при выборе оптимальных параметров ядра и управления памятью.
Какие видеокарты Nvidia построены на архитектуре Fermi?
К архитектуре Fermi относятся игровые карты серий GeForce GTX 400 и GTX 500, включая модели GTX 480, GTX 470, GTX 465, GTX 460, GTX 580, GTX 570 и GTX 560 Ti. Для профессиональных задач использовались Quadro 4000, 5000, 6000 и вычислительные Tesla C2050, C2070, M2050, M2090. Карты с compute capability 2.1 основаны на чипах GF114, GF116 и GF119, применяемых в бюджетных и среднеценовых моделях.
В чем отличие compute capability 2.0 от более поздних версий, например 3.0 и 5.0?
Compute capability 2.0 ограничена 32 ядрами CUDA на SM, максимальным числом потоков 1024 и разделяемой памятью 48 КБ. В версиях 3.x и 5.x увеличено количество ядер на SM до 192–2048, расширены кэши L1 и L2, улучшена поддержка операций с двойной точностью (FP64 до 1/2 скорости FP32), а также добавлены новые инструкции и улучшено планирование потоков. Эти изменения ускоряют вычисления и повышают пропускную способность памяти.
Как можно определить compute capability своей видеокарты Nvidia?
Определить compute capability можно через официальную таблицу Nvidia CUDA GPUs или с помощью утилиты deviceQuery из CUDA Toolkit. Запуск deviceQuery выводит параметры GPU, включая версию compute capability в формате Major.Minor. Программно это можно сделать через функцию cudaGetDeviceProperties, которая возвращает структуру с полями major и minor, соответствующими версии архитектуры.