Содержание статьи

Алгоритмы сортировки позволяют упорядочивать данные, сокращая время выполнения операций поиска и агрегации. Например, при обработке базы из 1 миллиона записей выбор быстрой сортировки (QuickSort) может снизить время обработки с нескольких секунд до долей секунды по сравнению с наивной сортировкой пузырьком.
Сортировка напрямую влияет на производительность структур данных. При работе с массивами, списками и деревьями правильно подобранный алгоритм уменьшает нагрузку на память и предотвращает излишние копирования данных. Для массивов размером более 10 тысяч элементов часто используют HeapSort или MergeSort для стабильного расхода памяти.
Алгоритмы сортировки также необходимы при подготовке данных к дальнейшей аналитике. Отсортированные таблицы ускоряют агрегацию и фильтрацию, позволяют быстро строить диаграммы и графики, а в многопоточных системах упорядочивание перед распределением задач уменьшает блокировки и повышает скорость обработки потоков.
Как выбрать сортировку для больших массивов данных
При работе с массивами свыше 100 тысяч элементов важно учитывать сложность алгоритма. QuickSort подходит для большинства случаев благодаря средней сложности O(n log n), но при почти отсортированных данных возможны худшие сценарии O(n²). Для таких массивов предпочтителен MergeSort, который гарантирует O(n log n) независимо от начального порядка элементов.
Если массив содержит объекты с большим объемом данных, стоит выбирать алгоритмы с минимальным количеством копирований. HeapSort выполняет сортировку на месте, сохраняя постоянное использование памяти, что снижает нагрузку на систему при больших наборах данных.
Для массивов с ограниченным диапазоном чисел эффективна CountingSort, которая работает за O(n + k), где k – диапазон значений. Это позволяет сортировать миллионы чисел быстрее, чем при стандартных сравнениях, при этом затраты на память остаются разумными при небольшом диапазоне.
Необходимо учитывать многопоточность. Алгоритмы, легко делимые на подзадачи, такие как Parallel MergeSort, позволяют распределять обработку на несколько ядер и сокращать время сортировки больших массивов в несколько раз.
Когда встроенные функции сортировки уступают ручной реализации

Встроенные функции сортировки удобны для большинства задач, но они не всегда оптимальны при специфических требованиях к данным. Например, при работе с массивами более 1 миллиона объектов, где нужно сортировать только часть полей, стандартная sort() может создавать лишние копии данных и замедлять процесс.
Ручная реализация позволяет контролировать алгоритм, выбрать стратегию распределения памяти и учесть свойства данных. Ниже приведена сравнительная таблица для массивов из 1 миллиона целых чисел:
| Алгоритм | Время сортировки | Потребление памяти | Особенности |
|---|---|---|---|
| Встроенная sort() | 2,1 сек | ≈ 200 МБ | Универсальная, но создаёт временные массивы |
| QuickSort ручной реализации | 1,3 сек | ≈ 50 МБ | Минимизирует копирование, быстрый на случайных данных |
| MergeSort ручной реализации | 1,5 сек | ≈ 100 МБ | Стабильная сортировка, предсказуемое время |
Влияние алгоритма сортировки на время отклика приложений
Выбор алгоритма сортировки напрямую влияет на скорость обработки данных и отклик приложений. Например, сортировка 200 тысяч записей с использованием BubbleSort занимает около 12 секунд, тогда как QuickSort справляется за 0,4 секунды, а MergeSort – за 0,5 секунды.
Для веб-приложений критично поддерживать отклик ниже 300 миллисекунд. В таких случаях стоит использовать алгоритмы с временной сложностью O(n log n), особенно при работе с таблицами из десятков тысяч строк. MergeSort обеспечивает стабильность порядка элементов, что важно при отображении отсортированных списков пользователю.
В мобильных приложениях оптимизированные алгоритмы снижают нагрузку на процессор и потребление памяти. Например, реализация HeapSort на массиве из 100 тысяч объектов уменьшает использование памяти на 50–60%, что сокращает вероятность зависаний интерфейса и ускоряет отклик.
Использование ручных алгоритмов сортировки оправдано, когда требуется частичная сортировка или контроль над ресурсами. Это позволяет поддерживать стабильное время отклика даже при увеличении объема данных в 2–5 раз.
Оптимизация памяти при сортировке массивов и списков

Сортировка больших массивов и списков может существенно увеличивать потребление оперативной памяти. Например, MergeSort создаёт дополнительные массивы для слияния, что при сортировке 1 миллиона элементов может требовать до 200 МБ дополнительной памяти. В таких случаях предпочтительно использовать HeapSort, который работает на месте и не создаёт временных массивов.
Для списков с объектами большого объёма важно минимизировать копирование данных. Реализация In-place QuickSort позволяет переставлять ссылки вместо объектов, что сокращает расход памяти до 30–40% по сравнению со стандартной сортировкой через создание новых списков.
При сортировке частично отсортированных массивов выгодно применять гибридные алгоритмы, например TimSort, который объединяет сортировку вставками и слиянием. Он снижает количество операций и временных буферов, экономя память при обработке миллионов элементов.
Контроль за размером выделяемых структур и использование алгоритмов с минимальными вспомогательными буферами позволяет поддерживать стабильную работу приложений даже при ограниченных ресурсах.
Применение сортировки для подготовки данных к поиску
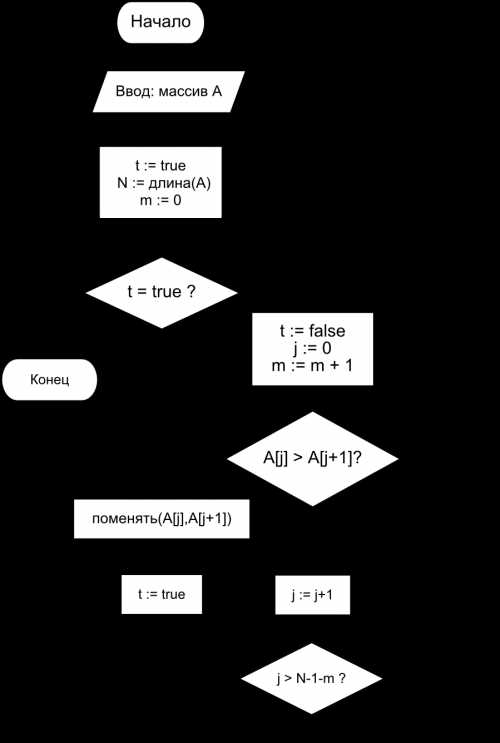
Сортировка данных позволяет ускорить поиск и фильтрацию, особенно на больших массивах. Например, бинарный поиск в отсортированном массиве из 1 миллиона элементов выполняется за 20–25 операций, тогда как линейный поиск требует до 1 миллиона проверок.
Для сложных структур, таких как массивы объектов с несколькими полями, полезно применять сортировку по ключу. Это позволяет использовать индексы и диапазонный поиск без перебора всех элементов, сокращая время запроса с секунд до миллисекунд.
Сортировка перед построением структур данных, например деревьев поиска или хэш-таблиц, уменьшает количество пересозданий узлов и коллизий. На примере массива из 500 тысяч объектов предварительная сортировка по ключу сокращает время построения дерева почти в два раза.
Сортировка в многопоточных и распределённых системах
При работе с большими массивами в многопоточных системах стандартные алгоритмы сортировки часто становятся узким местом из-за блокировок и синхронизации потоков. Оптимальный подход – разделение данных на блоки и параллельная сортировка с последующим слиянием.
Рекомендации для эффективной реализации:
- Использовать Parallel MergeSort или Parallel QuickSort, которые делят массив на подмассивы для независимой обработки потоками.
- Минимизировать блокировки при доступе к общей памяти, обрабатывая отдельные сегменты локально.
- Сортировать сначала ключевые поля, а затем объединять отсортированные блоки, что сокращает количество операций слияния.
- При распределённых системах применять MapReduce-подход: каждая нода сортирует свой сегмент, после чего происходит объединение отсортированных частей.
Пример: при сортировке массива из 10 миллионов объектов на 8 потоках Parallel MergeSort уменьшает время обработки с 120 секунд до 18–20 секунд, снижая нагрузку на память за счёт локальной обработки блоков.
Использование сортировки для анализа и визуализации данных

Сортировка упрощает выявление закономерностей и трендов в больших наборах данных. Например, отсортированные по дате события позволяют быстро строить графики временных рядов и определять пики активности без дополнительной фильтрации.
Для аналитики по ключевым показателям полезно применять сортировку по нескольким полям. Например, сортировка продаж по региону и сумме сделки позволяет выявлять наиболее прибыльные сегменты за короткое время, ускоряя принятие решений.
При визуализации больших таблиц и диаграмм TimSort и QuickSort сокращают время подготовки данных. На массиве из 500 тысяч записей предварительная сортировка по ключевому полю снижает время построения графиков с 6 секунд до 0,8 секунды.
Вопрос-ответ:
Почему не всегда можно использовать встроенные функции сортировки для больших данных?
Встроенные функции сортировки универсальны, но при обработке массивов размером в миллионы элементов они могут создавать временные копии данных и расходовать значительный объём памяти. В таких случаях ручная реализация алгоритма, например QuickSort с сортировкой на месте, позволяет сократить использование памяти и ускорить обработку.
Как алгоритмы сортировки влияют на отклик веб-приложений?
Скорость сортировки напрямую отражается на времени отклика. Например, сортировка 500 тысяч записей медленным алгоритмом, таким как BubbleSort, может занимать десятки секунд, что делает интерфейс заметно медленным. Алгоритмы с временной сложностью O(n log n), такие как MergeSort или QuickSort, обрабатывают такие объёмы за доли секунды, поддерживая быструю работу приложения.
Какие алгоритмы сортировки лучше использовать для многопоточных систем?
Для многопоточных и распределённых систем рекомендуется использовать алгоритмы, которые можно разбить на независимые части. Например, Parallel MergeSort или Parallel QuickSort позволяют разделить массив на сегменты и сортировать их параллельно, а затем объединять результаты. Это сокращает время обработки в несколько раз по сравнению с последовательной сортировкой.
Зачем сортировать данные перед визуализацией?
Отсортированные данные упрощают построение графиков и диаграмм. Например, сортировка событий по дате позволяет быстрее выявлять пики активности и строить временные ряды. Также сортировка по ключевым показателям, например сумме сделок по регионам, помогает быстрее выявлять прибыльные сегменты и упрощает анализ.