Содержание статьи

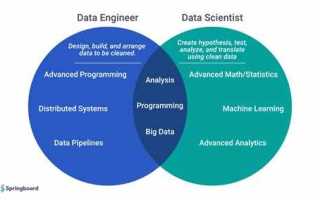
Data engineer отвечает за создание и поддержку инфраструктуры для работы с данными. В его задачи входят настройка потоков данных, управление базами данных и оптимизация процессов хранения и обработки информации. На практике это включает работу с ETL-процессами, распределёнными системами хранения данных и инструментами типа Apache Spark, Hadoop или Airflow.
Data scientist сосредоточен на анализе и интерпретации данных. Он применяет статистические методы, машинное обучение и визуализацию данных для выявления закономерностей и поддержки бизнес-решений. В повседневной работе специалист использует Python, R, SQL и библиотеки для анализа данных, такие как pandas, scikit-learn и TensorFlow.
Главное различие заключается в цели работы: Data engineer строит систему для обработки данных, а Data scientist извлекает из этих данных инсайты. Компании часто используют их совместно, чтобы данные корректно собирались, хранились и давали ценные результаты для принятия решений.
Для тех, кто рассматривает карьеру в области данных, важно понимать разницу в навыках и подходах. Data engineer требует углублённого знания систем и архитектуры данных, тогда как Data scientist ориентирован на статистику, моделирование и интерпретацию результатов. Это определяет выбор технологий, инструментов и образовательных программ для каждого направления.
Роли в обработке и хранении данных
Data engineer создаёт и поддерживает инфраструктуру для хранения и передачи данных. Он проектирует базы данных, организует поток информации между источниками и аналитическими системами, а также отвечает за надёжность и масштабируемость процессов. В работе применяются системы управления базами данных SQL и NoSQL, облачные платформы типа AWS или Azure, а также инструменты обработки больших данных, включая Apache Kafka и Spark.
Data scientist работает с уже подготовленными наборами данных. Его задача – выявление закономерностей, построение моделей прогнозирования и генерация отчётов для принятия решений. Для этого используются методы статистики, машинного обучения и визуализации данных. Работа включает подготовку данных, очистку и трансформацию, но основные процессы хранения и потоков данных выполняет Data engineer.
Разграничение ролей позволяет оптимизировать работу с информацией. Data engineer обеспечивает доступность, целостность и скорость обработки данных, а Data scientist концентрируется на аналитике и прогнозах. При проектировании систем данных рекомендуется заранее определить зоны ответственности, чтобы избежать дублирования задач и задержек в обработке информации.
Инструменты и технологии в работе специалистов
Data engineer использует инструменты для управления потоками данных, хранения и обработки больших объёмов информации. Data scientist применяет технологии для анализа, моделирования и визуализации данных. Ниже представлена таблица с основными инструментами и их назначением:
| Специалист | Инструмент | Назначение |
|---|---|---|
| Data engineer | Apache Spark | Обработка больших данных в распределённых системах |
| Data engineer | Apache Kafka | Организация потоковой передачи данных |
| Data engineer | SQL, NoSQL | Управление реляционными и нереляционными базами данных |
| Data engineer | Airflow | Оркестрация ETL-процессов |
| Data scientist | Python, R | Программирование и анализ данных |
| Data scientist | pandas, NumPy | Манипуляция и очистка данных |
| Data scientist | scikit-learn, TensorFlow | Построение моделей машинного обучения |
| Data scientist | Matplotlib, Seaborn, Plotly | Визуализация и построение графиков |
Для построения рабочих процессов рекомендуется совместное использование технологий. Data engineer обеспечивает подготовку и доступность данных, Data scientist выбирает инструменты анализа, подходящие под конкретные задачи и типы данных.
Навыки программирования и работы с базами данных
Data engineer и Data scientist используют разные подходы к программированию и работе с базами данных, что отражается в наборе необходимых навыков.
Для Data engineer ключевыми являются:
- Программирование на Python, Java или Scala для обработки данных и интеграции систем.
- Работа с SQL для проектирования и оптимизации реляционных баз данных.
- Знание NoSQL баз, таких как MongoDB, Cassandra, для хранения структурированных и полуструктурированных данных.
- Создание и поддержка ETL-процессов с помощью Airflow, NiFi или аналогичных инструментов.
- Оптимизация производительности хранилищ и потоков данных в распределённых системах.
Для Data scientist важны навыки:
- Программирование на Python или R для анализа и моделирования данных.
- Использование библиотек pandas и NumPy для трансформации и очистки данных.
- Работа с SQL для выборки и агрегации данных из различных источников.
- Применение машинного обучения через scikit-learn, TensorFlow или PyTorch.
- Построение визуализаций и интерактивных графиков с Matplotlib, Seaborn, Plotly.
Рекомендуется интегрировать навыки обеих ролей при проектировании систем: Data engineer обеспечивает корректное хранение и доступ к данным, Data scientist строит модели и аналитические отчёты на их основе.
Методы анализа данных и моделирования

Data scientist применяет разнообразные методы анализа и моделирования для выявления закономерностей и прогнозирования. Основные подходы включают:
- Статистический анализ: проверка гипотез, корреляция, регрессия для количественной оценки зависимостей между переменными.
- Машинное обучение: обучение моделей на исторических данных с использованием алгоритмов классификации, регрессии и кластеризации.
- Глубокое обучение: применение нейронных сетей для обработки изображений, текста или сложных многомерных данных.
- Визуализация данных: построение графиков, диаграмм и интерактивных дашбордов для интерпретации результатов и поддержки принятия решений.
- Feature engineering: создание новых признаков и трансформация существующих для повышения точности моделей.
Data engineer обеспечивает подготовку данных для этих методов: формирует качественные, структурированные наборы, интегрирует источники и автоматизирует процессы обработки. Без корректной инфраструктуры результаты анализа могут быть неполными или искажёнными.
Для повышения точности прогнозов рекомендуется совместная работа: Data engineer настраивает доступ к данным и их качество, Data scientist выбирает подходящие методы анализа и строит модели с учётом специфики задач и объёма данных.
Подход к подготовке данных для проектов

Data engineer отвечает за формирование корректной и доступной базы данных для проектов. Основные этапы подготовки включают:
- Сбор данных из внутренних и внешних источников с учётом форматов и частоты обновления.
- Очистка данных: удаление дубликатов, исправление некорректных значений, нормализация форматов.
- Трансформация и агрегирование данных для согласованности между различными источниками.
- Организация хранилищ и потоков данных с применением SQL, NoSQL, распределённых систем и ETL-инструментов.
- Мониторинг качества данных и автоматизация процессов обновления.
Data scientist использует подготовленные наборы данных для анализа и моделирования. Его подход включает:
- Выбор релевантных признаков для конкретной задачи.
- Дополнительная очистка и фильтрация данных под алгоритмы машинного обучения.
- Создание новых признаков (feature engineering) для повышения точности моделей.
- Проверка полноты и согласованности данных перед обучением моделей.
Рекомендуется планировать подготовку данных совместно: Data engineer обеспечивает стабильный поток качественных данных, Data scientist адаптирует их под аналитические задачи. Это сокращает время на обработку и повышает точность результатов.
Взаимодействие с бизнес-командой и аналитикой
Data engineer сотрудничает с бизнес-командой для обеспечения доступности и корректности данных, необходимых для аналитики. Основные задачи включают настройку потоков данных под требования отделов маркетинга, продаж и финансов, а также интеграцию внешних источников с внутренними системами.
Data scientist переводит бизнес-требования в аналитические задачи. Он определяет метрики, строит модели прогнозирования и визуализирует результаты для принятия решений. В работе применяются статистические тесты, алгоритмы машинного обучения и интерактивные дашборды для оперативного контроля показателей.
Эффективное взаимодействие требует чёткой договорённости о формате данных, периодичности обновления и критериях качества. Data engineer обеспечивает стабильность потоков, а Data scientist предоставляет интерпретируемую аналитику. Рекомендуется регулярно проводить совместные сессии для уточнения требований и корректировки процессов обработки данных.
Типичные задачи и проекты специалистов
Data engineer выполняет задачи, связанные с инфраструктурой и обработкой данных. Среди проектов:
- Разработка ETL-процессов для интеграции данных из CRM, ERP и внешних источников.
- Проектирование и оптимизация реляционных и NoSQL баз данных для хранения больших объёмов информации.
- Настройка потоковой обработки данных с использованием Kafka, Spark или Flink.
- Автоматизация мониторинга качества данных и устранение ошибок в потоках.
Data scientist занимается аналитикой и моделированием данных. Среди проектов:
- Построение прогнозных моделей продаж или пользовательского поведения с применением регрессии и классификации.
- Анализ больших наборов данных для выявления закономерностей и оптимизации бизнес-процессов.
- Создание визуализаций и дашбордов для оперативного контроля ключевых метрик.
- Тестирование гипотез и внедрение алгоритмов машинного обучения в продуктивные системы.
Для успешной реализации проектов рекомендуется планировать задачи совместно: Data engineer подготавливает стабильный поток качественных данных, Data scientist использует эти данные для построения моделей и аналитических отчётов.
Требования к образованию и профессиональному опыту
Data scientist чаще имеет образование в области математики, статистики, физики или компьютерных наук. Опыт анализа данных, построения моделей машинного обучения и работы с инструментами визуализации является обязательным. Необходимы навыки Python или R, библиотеки для анализа и моделирования (pandas, scikit-learn, TensorFlow) и опыт работы с SQL для выборки данных.
Для карьерного роста рекомендуется сочетание теоретических знаний и практических проектов. Data engineer должен демонстрировать способность строить масштабируемую и надёжную инфраструктуру, Data scientist – умение превращать данные в точные прогнозы и аналитические отчёты.
Вопрос-ответ:
В чем конкретно отличается работа Data engineer и Data scientist?
Data engineer создаёт и поддерживает инфраструктуру для хранения и обработки данных. Он проектирует базы данных, настраивает потоки информации и автоматизирует процессы интеграции данных из разных источников. Data scientist использует подготовленные данные для анализа, построения моделей и прогнозов, применяя статистические методы и алгоритмы машинного обучения.
Какие инструменты чаще всего используют Data engineer и Data scientist?
Data engineer работает с инструментами управления потоками данных и хранилищами, включая SQL и NoSQL базы, Apache Kafka, Spark и Airflow. Data scientist применяет Python или R, библиотеки pandas и NumPy для обработки данных, scikit-learn и TensorFlow для моделей машинного обучения, а также Matplotlib и Seaborn для визуализации результатов.
Нужно ли Data scientist уметь строить базы данных и настраивать потоки данных?
Data scientist должен уметь выполнять базовую очистку и трансформацию данных, а также писать SQL-запросы для выборки информации. Основная работа по проектированию и поддержке баз данных выполняется Data engineer, что позволяет Data scientist сосредоточиться на анализе и построении моделей.
Какие навыки важны для карьерного роста Data engineer и Data scientist?
Для Data engineer ключевы навыки работы с распределёнными системами, ETL-процессами, SQL и NoSQL базами, а также знание облачных платформ. Для Data scientist важны статистический анализ, программирование на Python или R, моделирование с использованием машинного обучения и визуализация данных. Практические проекты с реальными данными помогают развивать компетенции и подтверждать опыт.