Содержание статьи

При работе с табличными данными в pandas пустые значения встречаются регулярно: отсутствующие поля в CSV, незаполненные колонки после объединения таблиц, результаты парсинга с пропусками. Такие строки могут искажать агрегации, ломать расчёты и приводить к ошибкам при обучении моделей. Поэтому перед анализом данных требуется явно определить, какие пропуски допустимы, а какие строки подлежат удалению.
В pandas пустые значения представлены не только как NaN, но и как None, NaT или результат некорректного преобразования типов. Это влияет на поведение методов фильтрации. Например, числовые и временные столбцы обрабатываются по-разному, а строки могут считаться пустыми даже при наличии данных в отдельных ячейках.
Метод dropna позволяет удалять строки по заданным условиям: при наличии хотя бы одного пропуска, при отсутствии данных во всех колонках или при нехватке заполненных значений. Дополнительные параметры дают контроль над выбором столбцов, минимальным количеством непустых ячеек и способом применения изменений к исходному объекту.
Корректная настройка удаления строк с пустыми значениями помогает сохранить полезные данные и избежать скрытых потерь информации. Без понимания логики работы методов pandas легко удалить больше строк, чем требуется, или оставить в наборе данные, которые позже вызовут проблемы при расчётах.
Как определить наличие пустых значений в DataFrame перед удалением

Перед удалением строк требуется точно понять, где именно присутствуют пропуски. В pandas для этого используется метод isna(), который возвращает DataFrame из логических значений. Каждая ячейка со значением NaN, None или NaT будет помечена как True, что позволяет сразу увидеть структуру пропусков.
Для быстрой оценки количества строк с пустыми значениями применяется связка isna().any(axis=1). Она показывает, есть ли хотя бы один пропуск в строке. Аналогично isna().all(axis=1) выявляет строки, где отсутствуют данные во всех столбцах. Это помогает разделить частично и полностью пустые записи до принятия решения об удалении.
Если требуется понять масштаб проблемы по каждому столбцу, используется df.isna().sum(). Результат показывает количество пропусков в разрезе колонок и помогает определить поля, которые чаще всего содержат отсутствующие данные. Такой анализ полезен перед фильтрацией по конкретным столбцам.
Для проверки отдельных типов данных стоит учитывать, что пустые строки и нулевые значения не считаются пропусками. Например, 0 в числовом столбце или пустая строка «» в текстовом поле не будут выявлены через isna(). В таких случаях требуется дополнительная проверка с помощью условий сравнения или replace().
При работе с датами рекомендуется отдельно проверять значения NaT, так как они возникают при ошибках преобразования форматов. Комбинация pd.to_datetime(…, errors=»coerce») и последующего isna() позволяет выявить строки с некорректными датами до удаления.
Удаление строк с NaN во всех столбцах с помощью dropna

Если требуется удалить только те строки, где отсутствуют данные во всех столбцах, используется метод dropna с параметром how=»all». В этом режиме строка будет удалена только при условии, что каждая её ячейка содержит NaN, None или NaT.
Базовый вызов для удаления полностью пустых строк выглядит так:
- df.dropna(how=»all») – возвращает новый DataFrame без строк, где все значения отсутствуют
Такой подход полезен при загрузке данных из CSV или Excel, где в конце таблицы часто появляются пустые строки, не несущие никакой информации. При этом строки с частично заполненными данными сохраняются без изменений.
При работе с большими наборами данных стоит заранее проверить количество полностью пустых строк, чтобы понимать объём изменений:
- df.isna().all(axis=1).sum() – количество строк, где все значения пустые
Если требуется применить удаление напрямую к исходному объекту, используется параметр inplace:
- df.dropna(how=»all», inplace=True) – изменяет DataFrame без создания копии
Важно учитывать, что how=»all» игнорирует значения вроде 0 или пустой строки «». Такие строки не будут удалены, даже если визуально кажутся пустыми. При необходимости их следует предварительно заменить на NaN через replace или условия фильтрации.
Удаление строк с пустыми значениями только в выбранных столбцах
Часто пропуски допустимы не во всех полях, а только в отдельных колонках. Для таких случаев метод dropna поддерживает параметр subset, который ограничивает проверку конкретным набором столбцов. Строка будет удалена, если пустое значение найдено хотя бы в одном из указанных полей.
Пример базового применения: df.dropna(subset=[«price», «quantity»]). В этом случае pandas проверяет только столбцы price и quantity, игнорируя пропуски в остальных колонках. Такой подход подходит для фильтрации строк, где отсутствуют данные, необходимые для расчётов.
Если требуется удалить строки только при отсутствии значений во всех выбранных столбцах, используется сочетание subset и how=»all». Вызов df.dropna(subset=[«email», «phone»], how=»all») сохранит строки, где заполнен хотя бы один из этих контактов.
Перед удалением рекомендуется проверить количество затронутых строк. Для этого применяется выражение df[[«price», «quantity»]].isna().any(axis=1).sum(), которое показывает, сколько строк будет удалено при стандартной проверке.
Параметр subset принимает список, кортеж или индекс колонок, поэтому его удобно использовать в динамических сценариях, например при формировании перечня обязательных полей на основе пользовательских настроек или конфигурационных файлов.
Удаление строк, где заполнено меньше заданного количества ячеек
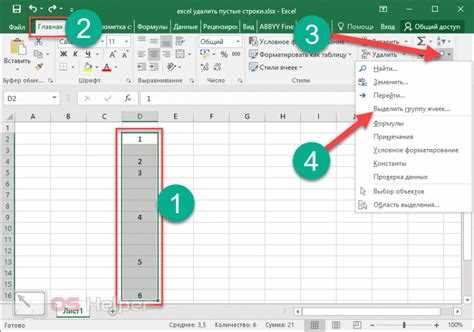
В pandas можно удалять строки не по конкретным столбцам, а по количеству реально заполненных ячеек. Для этого в методе dropna используется параметр thresh, который задаёт минимальное число непустых значений, необходимое для сохранения строки.
Например, вызов df.dropna(thresh=3) сохранит только те строки, где заполнено не меньше трёх ячеек. Все строки с двумя и менее значениями будут удалены независимо от того, в каких именно столбцах находятся пропуски.
Параметр thresh особенно удобен при работе с широкими таблицами, где часть колонок носит вспомогательный характер, а данные поступают неравномерно. Вместо перечисления десятков столбцов достаточно задать минимальный порог заполненности.
Ниже показано, как значение thresh влияет на поведение метода:
| Параметр thresh | Условие сохранения строки |
|---|---|
| thresh=1 | Есть хотя бы одно непустое значение |
| thresh=3 | Заполнено минимум три ячейки |
| thresh=кол-во столбцов | Отсутствуют пропуски во всей строке |
Перед удалением полезно оценить распределение заполненных значений. Для этого используется выражение df.notna().sum(axis=1), которое показывает количество непустых ячеек в каждой строке и помогает выбрать подходящий порог.
Если требуется учитывать только часть столбцов, параметр thresh можно комбинировать с subset. В этом случае минимальное количество значений будет считаться только по указанным колонкам, а остальные данные не будут участвовать в проверке.
Удаление строк с пустыми значениями с учётом параметра axis
Метод dropna позволяет управлять направлением удаления через параметр axis. По умолчанию axis=0, что означает удаление строк с пропусками. Параметр axis=1 переключает действие на столбцы, удаляя те, где встречаются пустые значения.
Примеры использования:
- df.dropna(axis=0) – удаляет строки с хотя бы одним пропуском
- df.dropna(axis=1) – удаляет столбцы, где присутствует хотя бы один NaN
- df.dropna(axis=0, how=»all») – удаляет только полностью пустые строки
- df.dropna(axis=1, thresh=5) – сохраняет столбцы, где заполнено минимум 5 ячеек
При работе с широкими таблицами проверка по столбцам помогает избавиться от колонок, которые почти не содержат данных, не затрагивая строки. Аналогично, удаление по строкам очищает данные от неполных записей без удаления целых колонок.
Перед применением рекомендуется анализировать структуру пропусков:
- df.isna().sum(axis=0) – количество пустых значений по столбцам
- df.isna().sum(axis=1) – количество пустых значений по строкам
Такой подход позволяет корректно выбирать axis в зависимости от того, что нужно удалить: неполные записи или неинформативные колонки.
Разница между inplace и созданием нового DataFrame при удалении строк
Метод dropna позволяет выбрать, изменять ли исходный DataFrame или создавать новый объект с очищенными данными. Параметр inplace=True применяет изменения напрямую к исходной таблице, без возвращения нового DataFrame.
Примеры:
- df.dropna(inplace=True) – исходный DataFrame df изменяется, строки с пропусками удаляются, возвращаемого объекта нет
- df_clean = df.dropna() – исходный DataFrame df остаётся без изменений, новая переменная df_clean содержит очищенную таблицу
Использование inplace=True экономит память, так как не создаётся копия, но делает невозможным восстановление исходного состояния без дополнительных действий. Создание нового DataFrame предпочтительно при необходимости сравнения до и после удаления или при отладке обработки данных.
При работе с большими наборами данных важно учитывать, что создание копии увеличивает объём занимаемой памяти. Если удаление строк применяется многократно, разумнее использовать inplace=True, но при исследовательском анализе лучше сохранять отдельный DataFrame для безопасной проверки результатов.
Типичные ошибки при удалении строк с NaN и способы их избежать
Неправильная интерпретация пустых значений также приводит к ошибкам. Значения 0, пустая строка «» или логическое False не считаются NaN и не будут удалены. Если необходимо, их следует предварительно заменить на np.nan через replace() или условия фильтрации.
Использование inplace=True без резервной копии DataFrame может вызвать потерю данных, если потребуется восстановить исходное состояние. Для безопасного анализа рекомендуется сначала создавать новый DataFrame, а inplace применять только после проверки.
Ещё одна ошибка связана с неверным применением параметра thresh. Указание числа, превышающего количество столбцов, приведёт к удалению всех строк, а слишком маленькое значение может оставить почти пустые записи. Рекомендуется предварительно подсчитать заполненные ячейки с помощью df.notna().sum(axis=1).
При работе с датами стоит проверять NaT отдельно. Некорректное преобразование форматов может создать пустые значения, которые не будут видны визуально. Используйте pd.to_datetime(…, errors=»coerce») и последующий isna() для выявления таких строк.
Вопрос-ответ:
Как проверить, сколько строк в DataFrame содержат пустые значения?
Для оценки количества строк с пропусками используется комбинация методов isna() и any(axis=1). Выражение df.isna().any(axis=1).sum() возвращает число строк, где хотя бы одна ячейка содержит NaN, None или NaT. Это позволяет определить объём данных, которые могут быть удалены при фильтрации.
Можно ли удалить строки с пропусками только в отдельных столбцах?
Да, для этого применяется параметр subset метода dropna. Например, df.dropna(subset=[«price», «quantity»]) удалит только те строки, где отсутствуют значения в колонках price или quantity. Остальные столбцы игнорируются, что предотвращает потерю полезной информации.
Как удалить строки, где заполнено меньше определённого числа ячеек?
Используется параметр thresh метода dropna. Он задаёт минимальное количество непустых ячеек для сохранения строки. Например, df.dropna(thresh=3) удалит строки с двумя и менее заполненными ячейками. Такой подход полезен при широких таблицах с частично заполненными данными.
В чём отличие использования inplace=True и создания нового DataFrame при удалении строк?
При inplace=True изменения применяются к исходному DataFrame, а метод не возвращает новый объект. Это экономит память, но делает невозможным восстановление исходных данных без резервной копии. Если создать новый DataFrame, например df_clean = df.dropna(), исходный набор остаётся без изменений, и можно сравнивать до и после фильтрации.
Какие ошибки чаще всего возникают при удалении строк с NaN и как их избежать?
Основные ошибки: удаление строк без уточнения столбцов, что ведёт к потере нужных данных; игнорирование значений вроде 0 или пустой строки, которые не считаются NaN; некорректное использование thresh, приводящее к удалению слишком большого числа строк; удаление с inplace=True без резервной копии. Чтобы избежать проблем, проверяйте столбцы через subset, заменяйте пустые строки на NaN, предварительно оценивайте количество заполненных ячеек и при необходимости создавайте копию DataFrame.
Как удалить строки с пустыми значениями только в определённых столбцах?
Для удаления строк с пропусками в конкретных колонках используется параметр subset метода dropna. Например, df.dropna(subset=[«email», «phone»]) удалит только те строки, где отсутствуют данные в столбцах email или phone, оставляя остальные строки с пропусками в других колонках.
Что делает параметр thresh в методе dropna и как его применять?
Параметр thresh задаёт минимальное количество непустых ячеек, необходимых для сохранения строки. Например, df.dropna(thresh=3) удалит все строки, где заполнено менее трёх ячеек. Этот метод удобен для широких таблиц с частично заполненными данными и позволяет сохранять строки с достаточным количеством информации.