Содержание статьи

CuneiForm – это программа для распознавания текста (OCR), которая позволяет преобразовывать сканированные документы и изображения в редактируемый текст. Она поддерживает работу с более чем 20 языками, включая русский, английский, немецкий и французский, а также умеет распознавать текст в документах с двоичным и многоколоночным форматированием.
Программа сохраняет структуру исходного документа, включая абзацы, таблицы и списки, что позволяет минимизировать ручную корректировку после распознавания. Рекомендуется использовать CuneiForm для обработки сканов книг, договоров и отчетов, где важно сохранить форматирование.
CuneiForm поддерживает экспорт в форматы TXT, RTF, DOC и PDF. Для ускорения распознавания больших массивов документов можно использовать пакетную обработку, а точность повысить, подбирая правильный язык документа и применяя встроенную проверку орфографии.
Программа удобна для работы как с отдельными страницами, так и с многостраничными файлами TIFF и PDF. Для оптимального результата рекомендуется предварительно очистить скан от шумов и корректировать ориентацию страниц перед распознаванием.
Как распознавать текст из сканированных документов
Для распознавания текста в CuneiForm сначала откройте файл скана в формате TIFF, JPEG или PDF. Программа автоматически определяет границы страниц и сегментирует текст на блоки, колонки и абзацы. Рекомендуется проверять корректность автоматической сегментации перед запуском распознавания.
Перед обработкой документов стоит убедиться, что разрешение скана не ниже 300 dpi, а контраст текста и фона достаточен для точного распознавания. Сканы с наклонным текстом или шумами требуют предварительной коррекции с помощью инструментов выравнивания и очистки изображения.
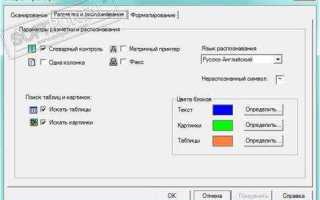
Выберите язык документа в настройках CuneiForm, чтобы повысить точность распознавания. Для многоязычных страниц можно включить несколько языков одновременно. После настройки нажмите кнопку «Распознать», программа создаст текстовый файл с сохранением исходной структуры документа.
Для больших объемов сканированных документов рекомендуется использовать пакетную обработку. Это позволяет обрабатывать сразу несколько файлов и автоматически сохранять результаты в выбранном формате без ручного вмешательства.
Какие форматы файлов поддерживает CuneiForm

CuneiForm распознает текст из растровых изображений форматов TIFF, JPEG, PNG и BMP. Для многостраничных документов программа корректно обрабатывает многостраничные TIFF и PDF, включая файлы с встроенными изображениями и текстовыми слоями.
После распознавания текст можно экспортировать в форматы TXT, RTF, DOC и PDF. Формат RTF сохраняет базовое форматирование абзацев и шрифтов, а DOC подходит для дальнейшего редактирования в текстовых редакторах, таких как Microsoft Word. Экспорт в PDF позволяет создать документ с редактируемым и поисковым текстом, сохранив исходную компоновку страниц.
При работе с нестандартными файлами рекомендуется предварительно конвертировать их в поддерживаемый формат. Например, изображения из сканеров, сохраняемые в RAW или нестандартных графических форматах, лучше перевести в TIFF или PNG для корректного распознавания.
Как настроить программу для работы с разными языками

В CuneiForm доступна настройка языка распознавания для каждого документа. В меню «Язык документа» можно выбрать один или несколько языков одновременно, что особенно важно для многоязычных текстов. Программа поддерживает более 20 языков, включая кириллицу, латиницу и европейские алфавиты.
Для повышения точности распознавания рекомендуется выбирать только те языки, которые присутствуют в документе. Если текст содержит несколько языков на одной странице, активируйте их все, чтобы избежать ошибок в распознавании отдельных слов и символов.
При работе с документами, содержащими специальные символы или диакритические знаки, полезно включить расширенные наборы символов для выбранного языка. Это снижает количество некорректно распознанных букв и ускоряет процесс проверки и редактирования текста.
После выбора языков рекомендуется сохранить настройки в профиле, чтобы при повторной обработке документов с теми же языками не требовалось перенастраивать программу.
Методы проверки и корректировки распознанного текста

После распознавания документа в CuneiForm важно проверить текст на точность и исправить ошибки. Программа предлагает несколько инструментов для этого:
- Встроенная проверка орфографии для выбранного языка, которая выделяет слова с возможными ошибками.
- Возможность сравнения исходного изображения с распознанным текстом с помощью режима «Смотреть рядом», чтобы исправлять пропуски и искажения.
- Редактирование отдельных блоков текста прямо в окне программы для корректировки неправильного распознавания символов.
Для структурированных документов полезно:
- Проверять форматирование абзацев и списков, чтобы сохранить исходную компоновку текста.
- Корректировать таблицы, проверяя соответствие строк и столбцов с оригиналом.
- Использовать функцию пакетной проверки, если распознаются несколько страниц или файлов.
Регулярное использование этих методов снижает количество ошибок и минимизирует ручную корректировку после экспорта текста в DOC, RTF или PDF.
Как экспортировать результаты в Word, PDF и TXT
CuneiForm позволяет сохранять распознанный текст в нескольких форматах, обеспечивая удобство дальнейшего использования:
- TXT – простой текст без форматирования, подходит для быстрой вставки в редакторы и анализа данных.
- RTF и DOC – сохраняют структуру документа, включая абзацы, списки и таблицы, что облегчает редактирование в Microsoft Word и LibreOffice.
- PDF – создаёт документы с редактируемым текстом и сохранением исходной компоновки страниц, удобно для пересылки и архивации.
Для экспорта следует выполнить несколько шагов:
- Выберите формат файла в меню «Сохранить как».
- Укажите папку и имя файла для сохранения.
- При экспорте в PDF можно включить параметры сохранения шрифтов и изображений для точного соответствия оригиналу.
Рекомендуется проверять результат после экспорта, особенно для документов с таблицами и многоязычным текстом, чтобы убедиться, что структура и символы отображаются корректно.
Советы по ускорению распознавания и улучшению точности
Для повышения скорости и точности работы CuneiForm рекомендуется использовать сочетание оптимизации исходных сканов и настроек программы.
Основные рекомендации можно представить в виде таблицы:
| Задача | Рекомендации |
|---|---|
| Разрешение сканов | Использовать 300–400 dpi для текстов и 600 dpi для мелких шрифтов или таблиц. |
| Контраст и очистка изображения | Удалять шумы и корректировать яркость/контраст, чтобы текст выделялся на фоне. |
| Языковые настройки | Выбирать только языки, присутствующие в документе, и активировать расширенные наборы символов при необходимости. |
| Сегментация документа | Проверять правильность блоков и колонок перед распознаванием, особенно для многостраничных документов. |
| Пакетная обработка | Использовать для нескольких файлов одновременно, чтобы снизить время обработки и автоматически сохранять результаты. |
Дополнительно рекомендуется периодически обновлять версию CuneiForm и проверять настройки экспорта, чтобы избежать потерь форматирования и ошибок в символах при сохранении в DOC или PDF.
Вопрос-ответ:
Для каких задач лучше использовать программу CuneiForm?
CuneiForm подходит для распознавания текста из сканированных документов, изображений и многостраничных PDF. Она сохраняет структуру исходного документа, включая абзацы, таблицы и списки, что делает её удобной для работы с книгами, договорами и отчетами.
Какие языки поддерживает CuneiForm и как их выбрать?
Программа поддерживает более 20 языков, включая русский, английский, немецкий и французский. Для точного распознавания в настройках документа выбирается один или несколько языков. Для многоязычных страниц активируют все присутствующие языки, а для специальных символов включают расширенные наборы символов выбранного языка.
Как правильно подготовить сканы для распознавания?
Скан следует делать с разрешением 300–400 dpi для обычного текста и до 600 dpi для мелких шрифтов или таблиц. Важно, чтобы текст был четким, без наклона, с достаточным контрастом на фоне. Шумы и лишние элементы лучше удалить с помощью инструментов очистки изображения перед распознаванием.
В какие форматы можно экспортировать распознанный текст?
CuneiForm позволяет сохранять текст в форматах TXT, RTF, DOC и PDF. Формат TXT используется для простого текста, RTF и DOC сохраняют форматирование абзацев и таблиц, а PDF создаёт документ с редактируемым текстом и сохранением компоновки страниц.
Какие способы ускоряют распознавание и повышают точность?
Для повышения точности и скорости рекомендуется использовать корректные языковые настройки, проверять сегментацию документа на блоки и колонки, очищать сканы от шумов и выравнивать текст. Пакетная обработка позволяет обрабатывать несколько файлов одновременно и автоматически сохранять результаты, что сокращает время работы с большими объемами документов.
Как правильно использовать CuneiForm для распознавания документов с несколькими колонками и таблицами?
Для документов с колонками и таблицами важно проверить автоматическую сегментацию текста перед распознаванием. В CuneiForm можно вручную выделить блоки и колонки, чтобы программа правильно определила границы текста. Для таблиц полезно использовать отдельные блоки для каждой строки или группы ячеек, чтобы сохранить структуру при экспорте в DOC или RTF. Также рекомендуется использовать сканы с разрешением не ниже 300 dpi и корректным контрастом, чтобы минимизировать ошибки распознавания символов и сохранить точность размещения текста на странице.