Содержание статьи

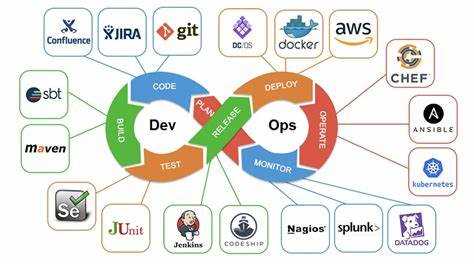
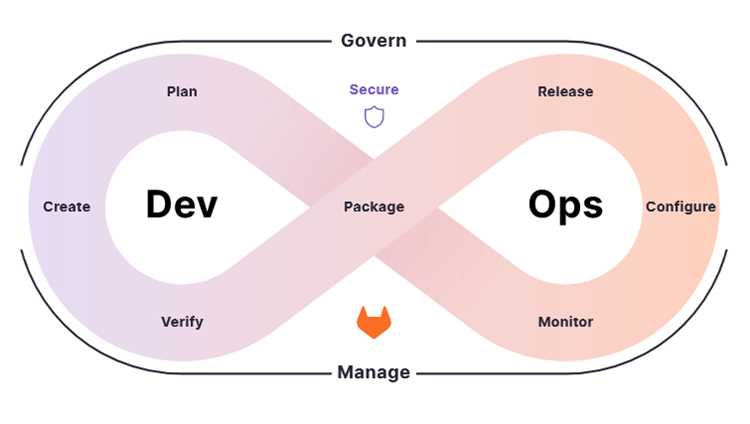
Специалисты DevOps должны владеть инструментами автоматизации, такими как Jenkins, GitLab CI/CD и Ansible. Знание этих инструментов позволяет создавать пайплайны сборки и развертывания, сокращая время на ручные операции и снижая риск ошибок.
Управление конфигурациями через Terraform или Puppet дает возможность поддерживать инфраструктуру как код. Это помогает контролировать изменения, воспроизводить окружения и ускоряет развертывание серверов в облаке и локальных центрах обработки данных.
Контейнеризация с Docker и оркестрация Kubernetes становятся обязательными навыками. Они позволяют управлять масштабируемыми приложениями, автоматизировать деплой и обеспечивать отказоустойчивость сервисов при увеличении нагрузки.
Мониторинг и логирование с использованием Prometheus, Grafana или ELK Stack позволяют отслеживать производительность приложений и инфраструктуры. Анализ метрик и логов помогает выявлять узкие места и предотвращать сбои до того, как они повлияют на пользователей.
В DevOps критично понимание практик CI/CD для непрерывной интеграции и доставки. Настройка автоматического тестирования, сборки и деплоя обновлений сокращает цикл выпуска и улучшает качество программного продукта.
Безопасность процессов и управление доступом с помощью инструментов Vault, AWS IAM или RBAC в Kubernetes позволяют минимизировать риски утечки данных и обеспечивать соответствие требованиям нормативных стандартов.
Автоматизация сборки и развертывания приложений
Автоматизация сборки позволяет уменьшить количество ручных ошибок и ускорить процесс подготовки программного продукта к деплою. Для этого применяются инструменты CI/CD, такие как Jenkins, GitLab CI и TeamCity, которые поддерживают написание скриптов сборки и настройку последовательности задач.
Скрипты сборки должны включать компиляцию, запуск модульных тестов, статический анализ кода и упаковку артефактов. Артефакты можно хранить в репозиториях вроде Nexus или Artifactory, что обеспечивает повторяемость и контроль версий.
Развертывание приложений автоматизируется с помощью Ansible, Chef или Puppet. Эти инструменты позволяют описывать конфигурации серверов в виде кода и применять их на нескольких средах одновременно, сокращая время на настройку окружений.
Использование контейнеризации с Docker облегчает переносимость приложений между средами. Для оркестрации контейнеров применяются Kubernetes или Docker Swarm, что упрощает масштабирование и управление состоянием сервисов при обновлениях.
Для минимизации риска сбоев рекомендуется внедрять стратегии blue-green deployment или canary releases. Они позволяют постепенно выпускать обновления и быстро откатывать изменения при обнаружении проблем.
Логирование и уведомления в пайплайне сборки помогают отслеживать ошибки и задержки. Настройка интеграции с системами уведомлений, такими как Slack или Teams, позволяет оперативно реагировать на сбои и корректировать процессы.
Управление конфигурациями и инфраструктурой как код
Управление конфигурациями позволяет стандартизировать настройку серверов и приложений. Инструменты Terraform, Puppet и Ansible используют декларативные описания инфраструктуры, что обеспечивает предсказуемое развертывание и контроль версий изменений.
Скрипты инфраструктуры должны включать определение сетевых ресурсов, правил безопасности, дисковых томов и сервисов. Terraform позволяет создавать облачные ресурсы в AWS, Azure или GCP с одинаковыми настройками, что сокращает ручные операции и ошибки при масштабировании.
Для управления конфигурациями приложений Ansible применяет плейбуки, которые описывают шаги установки и настройки сервисов. Это упрощает повторное развертывание на новых серверах и поддерживает консистентность окружений.
Хранение конфигураций в системах контроля версий, таких как Git, позволяет отслеживать изменения, проводить код-ревью и возвращаться к стабильным версиям при необходимости.
Рекомендуется внедрять автоматическое тестирование инфраструктуры с помощью Terratest или Kitchen. Это позволяет выявлять ошибки конфигурации до развертывания на продуктивных серверах.
Использование модульного подхода и шаблонов для ресурсов упрощает масштабирование и повторное использование конфигураций, сокращая время подготовки новых сред и повышая управляемость инфраструктуры.
Мониторинг и логирование приложений в реальном времени
Мониторинг позволяет отслеживать производительность сервисов и реагировать на сбои до того, как они затронут пользователей. Инструменты Prometheus и Grafana собирают метрики CPU, памяти, задержек и количества запросов, визуализируя их в дашбордах для быстрого анализа.
Логирование через ELK Stack или Fluentd обеспечивает централизованный сбор логов из разных сервисов. Структурированные логи упрощают фильтрацию и поиск ошибок, а индексация позволяет отслеживать события в реальном времени.
Настройка алертов на основе порогов метрик или паттернов логов позволяет оперативно уведомлять команду через Slack, Teams или электронную почту о проблемах, снижая время реакции на инциденты.
Использование распределённого трейсинга с Jaeger или OpenTelemetry помогает анализировать производительность микросервисов, выявлять узкие места и оптимизировать маршруты обработки запросов.
Рекомендуется интегрировать мониторинг и логирование с CI/CD пайплайнами, чтобы при деплое автоматически проверять стабильность сервисов и обнаруживать потенциальные сбои до перевода изменений в продуктив.
Хранение исторических метрик и логов позволяет проводить анализ трендов, прогнозировать рост нагрузки и планировать масштабирование инфраструктуры без деградации работы приложений.
Контейнеризация и оркестрация с Docker и Kubernetes

Контейнеризация с Docker позволяет упаковывать приложения с их зависимостями в изолированные контейнеры, что обеспечивает одинаковую работу на любых серверах. Это упрощает переносимость и тестирование, снижая вероятность ошибок при развертывании.
Создание Dockerfile с указанием базового образа, зависимостей и команд запуска обеспечивает воспроизводимость сборки. Оптимизация образов через уменьшение слоёв и использование легковесных базовых образов сокращает время запуска и нагрузку на хост-систему.
Оркестрация контейнеров с Kubernetes позволяет управлять масштабированием, балансировкой нагрузки и восстановлением приложений при сбоях. Настройка Deployment, Service и ConfigMap обеспечивает автоматическое обновление и конфигурирование приложений без ручного вмешательства.
Использование стратегий обновления, таких как rolling update и canary deployment, позволяет постепенно внедрять новые версии контейнеров и минимизировать простой сервисов.
Мониторинг состояния контейнеров через Kubernetes Metrics Server или интеграцию с Prometheus обеспечивает контроль за загрузкой ресурсов и своевременную реакцию на превышение порогов CPU и памяти.
Хранение и управление образами через Docker Registry или Harbor обеспечивает версионирование, безопасность и доступность контейнеров для всех этапов разработки и деплоя.
CI/CD практики для быстрого выпуска обновлений
CI/CD пайплайны позволяют автоматизировать процесс интеграции и доставки кода. Инструменты Jenkins, GitLab CI/CD и CircleCI обеспечивают запуск сборки, тестов и деплоя при каждом изменении в репозитории.
Настройка автоматического запуска модульных и интеграционных тестов снижает риск попадания ошибок в продуктив. Тестовые окружения можно создавать через Docker или Kubernetes, повторяя условия реального сервера.
Для ускорения выпуска обновлений рекомендуется внедрять feature branches и автоматическое слияние через pull request с проверкой тестами. Это упрощает управление параллельной разработкой и уменьшает вероятность конфликтов.
Доставка приложений в продуктив лучше организовать через стратегии blue-green или canary deployment, чтобы минимизировать влияние на пользователей и быстро откатывать проблемные изменения.
Интеграция с системами уведомлений и мониторинга позволяет отслеживать результат каждого деплоя, фиксировать ошибки и получать уведомления в реальном времени для оперативного реагирования.
Использование артефактов сборки в репозиториях вроде Nexus или Artifactory обеспечивает версионирование и повторное использование компонентов при деплое на разных средах.
Безопасность и управление доступом в DevOps процессах
Обеспечение безопасности в DevOps включает контроль доступа, защиту секретов и аудит действий. Инструменты Vault, AWS IAM и Kubernetes RBAC позволяют централизованно управлять правами пользователей и сервисов.
Рекомендованные практики включают:
- Использование least privilege для ограничения доступа к ресурсам.
- Хранение паролей, ключей и токенов в защищённых хранилищах, а не в коде или конфигурационных файлах.
- Регулярная ротация секретов и сертификатов для снижения риска компрометации.
- Внедрение двухфакторной аутентификации для критических сервисов и систем управления конфигурациями.
- Настройка логирования и аудита действий пользователей, включая изменения конфигураций и деплои, с сохранением истории для анализа инцидентов.
Дополнительно рекомендуется:
- Интегрировать сканирование уязвимостей контейнеров и зависимостей с CI/CD пайплайнами.
- Автоматически проверять соответствие политик безопасности в инфраструктуре как код через инструменты вроде Terraform Sentinel или OPA.
- Проводить регулярные ревизии прав доступа и удалять устаревшие учетные записи.
Следование этим практикам снижает вероятность утечек, защищает инфраструктуру и упрощает управление безопасностью на всех этапах DevOps процесса.
Вопрос-ответ:
Какие инструменты автоматизации сборки и развертывания стоит изучить DevOps специалисту?
Для автоматизации сборки и деплоя широко используются Jenkins, GitLab CI/CD и TeamCity. Они позволяют настроить последовательность задач: сборка, тестирование, упаковка артефактов и деплой на серверы. Важно также освоить работу с репозиториями артефактов, такими как Nexus или Artifactory, для контроля версий и повторного использования компонентов.
Как управление конфигурациями помогает уменьшить ошибки при развертывании?
Инструменты вроде Terraform, Puppet и Ansible позволяют описывать инфраструктуру и конфигурации в виде кода. Это даёт возможность создавать идентичные среды, отслеживать изменения через системы контроля версий, повторно использовать шаблоны ресурсов и автоматически применять обновления без ручной настройки каждого сервера.
Какие практики мониторинга наиболее важны для DevOps команды?
Ключевым является сбор метрик CPU, памяти, времени отклика и количества запросов с помощью Prometheus. Визуализация через Grafana помогает быстро обнаруживать отклонения. Логирование с использованием ELK Stack или Fluentd позволяет отслеживать события и ошибки. Для микросервисной архитектуры полезно внедрять распределённый трейсинг через Jaeger или OpenTelemetry для анализа задержек и взаимодействия сервисов.
В чём преимущество использования контейнеризации и оркестрации с Docker и Kubernetes?
Контейнеризация с Docker упрощает упаковку приложения со всеми зависимостями, делая его переносимым между разными средами. Kubernetes позволяет управлять масштабированием, балансировкой нагрузки и автоматическим восстановлением контейнеров. Стратегии развертывания, такие как rolling update или canary deployment, дают возможность внедрять обновления постепенно и снижать риск сбоев в продуктиве.
Как обеспечить безопасность и контроль доступа в DevOps процессах?
Для управления правами и защиты секретов используют Vault, AWS IAM и Kubernetes RBAC. Рекомендуется ограничивать права пользователей по принципу least privilege, хранить пароли и токены в защищённых хранилищах, регулярно проводить ротацию секретов и настраивать логирование всех действий. Автоматическое сканирование контейнеров и проверка политик инфраструктуры помогают выявлять уязвимости до развертывания.
Какие ключевые навыки DevOps помогают ускорить выпуск обновлений и повысить стабильность сервисов?
Основные навыки включают автоматизацию сборки и развертывания с помощью Jenkins, GitLab CI/CD или TeamCity, управление конфигурациями через Terraform, Ansible и Puppet, а также контейнеризацию и оркестрацию с Docker и Kubernetes. Владение этими инструментами позволяет создавать повторяемые пайплайны, поддерживать идентичные среды для тестирования и продуктива, автоматически масштабировать приложения и внедрять обновления с минимальным риском сбоев. Дополнительно важно настраивать мониторинг и логирование через Prometheus, Grafana и ELK Stack для отслеживания производительности и быстрого выявления проблем.