
Содержание статьи

Массивы в программировании представляют собой структуры данных, позволяющие хранить набор однотипных элементов с индексированным доступом. Правильный выбор методов работы с массивами напрямую влияет на скорость выполнения операций, особенно при обработке больших объемов данных. Например, при работе с массивом из 100 000 элементов использование встроенных функций сортировки может сократить время выполнения задачи на порядок по сравнению с ручной реализацией алгоритмов.
Инициализация массива может выполняться статически, через литералы, или динамически с выделением памяти во время выполнения программы. Для крупных данных рекомендуется использовать динамические структуры с предварительным резервированием памяти, что снижает накладные расходы на перераспределение и копирование элементов. Также важна правильная стратегия перебора элементов: циклы for и while подходят для последовательной обработки, а методы map, filter и reduce упрощают выполнение вычислений и трансформаций.
При фильтрации и поиске данных в массиве стоит учитывать алгоритмическую сложность операций. Линейный поиск оптимален для неотсортированных массивов, тогда как двоичный поиск сокращает количество проверок при работе с отсортированными структурами. Для объединения или разбиения массивов лучше применять встроенные функции, позволяющие избежать лишних копирований и уменьшить использование оперативной памяти. Практика показывает, что внимательное сочетание этих приемов снижает время выполнения кода и повышает стабильность работы программ.
Инициализация и заполнение массивов различными способами

Массив можно создавать напрямую через литералы, например let arr = [1, 2, 3, 4], что подходит для фиксированного набора элементов. Для массивов большого размера предпочтительно использовать конструкторы, например new Array(1000), с последующей инициализацией через цикл или метод fill. Это снижает накладные расходы на создание промежуточных структур.
Динамическое заполнение массива через цикл for позволяет задавать элементы по вычисляемым значениям, например arr[i] = i * 2. Методы map и from сокращают код при генерации массивов на основе вычислений или других коллекций: Array.from({length: 100}, (_, i) => i + 1) создаст массив чисел от 1 до 100 без ручного перебора.
При работе с объектными или смешанными массивами важно сразу определять структуру элементов. Использование шаблонных объектов позволяет создавать массивы с одинаковыми полями: Array.from({length: 50}, () => ({id: 0, value: »})). Для потоковой обработки данных рекомендуется комбинировать методы push и unshift, чтобы управлять порядком вставки и минимизировать пересоздание массивов.
Резервирование памяти перед заполнением крупных массивов снижает нагрузку на сборщик мусора. В языках с автоматическим управлением памятью, таких как JavaScript или Python, создание массивов через конструктор с заданной длиной предотвращает многократное расширение внутренней структуры при добавлении элементов.
Перебор элементов: циклы и встроенные методы
Для последовательного обхода массивов чаще всего применяются циклы for и while. Цикл for удобен при известной длине массива: for (let i = 0; i < arr.length; i++) { /* операции с arr[i] */ }. Цикл while подходит для случаев, когда количество итераций зависит от условий обработки элементов.
Методы forEach, map и filter позволяют выполнять перебор без явного использования индексов. forEach применяется для операций без изменения исходного массива, например логирование элементов или вычисление суммы: arr.forEach(el => sum += el). map формирует новый массив на основе вычислений: arr.map(el => el * 2), сохраняя исходные данные без модификации.
Методы some и every используют перебор для проверки условий: arr.some(el => el > 10) возвращает true, если хотя бы один элемент удовлетворяет условию. every возвращает true, если все элементы соответствуют критерию. Эти методы сокращают код и повышают читаемость при проверках массива.
Для массивов с большой длиной предпочтительно использовать простые циклы for вместо встроенных методов, так как они не создают дополнительных функций обратного вызова и уменьшают нагрузку на память. Комбинирование циклов и методов позволяет оптимизировать перебор под конкретные задачи, например частичная обработка или фильтрация по сложным критериям.
Фильтрация и поиск данных в массиве
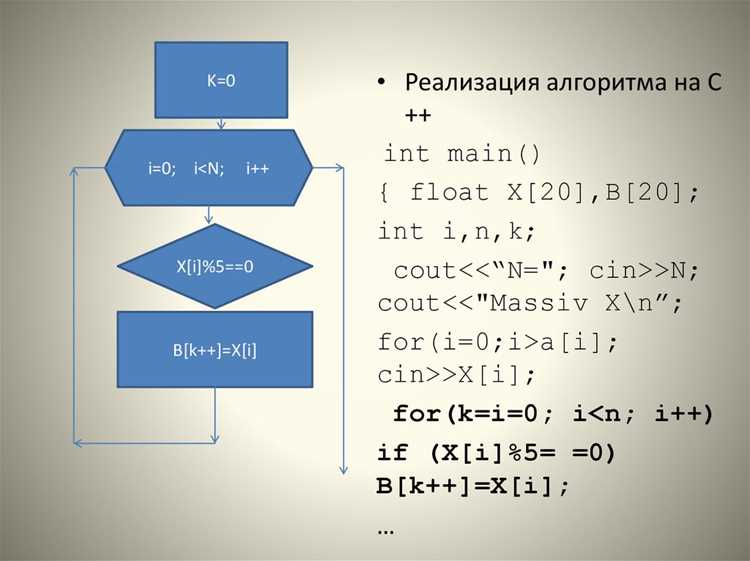
Поиск и отбор элементов в массиве зависит от структуры данных и объема информации. Для небольших массивов можно использовать линейный поиск, перебирая элементы по индексу:
- Линейный поиск: for или forEach проверяют каждый элемент, возвращая первый совпадающий или собирая все подходящие элементы.
- Поиск с предикатом: метод find возвращает первый элемент, удовлетворяющий условию, а findIndex – его индекс.
Для фильтрации элементов применяется метод filter, формирующий новый массив:
- Отбор по числовым критериям: arr.filter(el => el > 50).
- Отбор по свойствам объектов: arr.filter(obj => obj.status === ‘active’).
- Комбинация условий: arr.filter(el => el.score > 80 && el.completed).
Для массивов с большим количеством элементов важно учитывать сложность алгоритмов. Использование sort перед двоичным поиском уменьшает количество проверок до O(log n). Для частых фильтраций можно создавать вспомогательные индексы или словари, что снижает нагрузку на перебор.
Методы some и every позволяют проверить наличие или выполнение условия для нескольких элементов без создания нового массива. Это экономит память и ускоряет выполнение при проверках больших наборов данных.
Сортировка массивов по заданным критериям
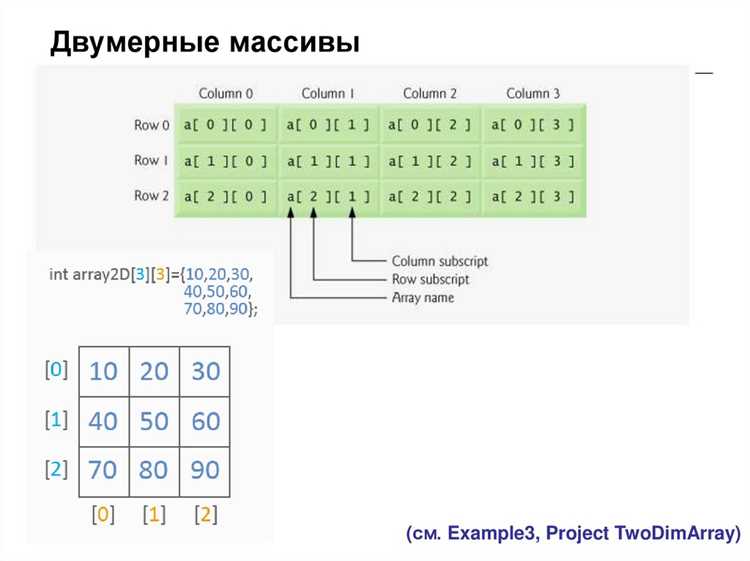
Сортировка массивов позволяет упорядочить элементы для ускорения поиска и анализа. В JavaScript используется метод sort, который изменяет исходный массив и может принимать функцию сравнения для задания критерия:
Пример числовой сортировки: arr.sort((a, b) => a — b). Для объектов сортировка выполняется по ключу:
Пример сортировки объектов: arr.sort((a, b) => a.age — b.age).
Для сравнения разных подходов можно использовать таблицу:
| Метод | Когда применять | Сложность |
|---|---|---|
| for + ручной алгоритм (bubble, insertion) | Малые массивы, демонстрационные цели | O(n²) |
| Метод sort с функцией сравнения | Любой массив, включая объекты | O(n log n) на большинстве реализаций |
| Сортировка с помощью вспомогательных массивов | Когда нужна копия без изменения исходного массива | O(n log n) + O(n) память |
При сортировке больших массивов рекомендуется минимизировать вызовы функций сравнения и избегать лишних преобразований типов. Для строковых данных можно использовать localeCompare, чтобы корректно учитывать национальные алфавиты. Комбинированные критерии сортировки реализуются через последовательное сравнение ключей в функции обратного вызова.
Объединение, разбиение и копирование массивов
Объединение массивов выполняется с помощью метода concat или оператора spread. Например, let combined = arr1.concat(arr2) или let combined = […arr1, …arr2]. Первый способ не изменяет исходные массивы, второй позволяет вставлять элементы в любой позиции при создании нового массива.
Разбиение массива на части выполняется методом slice или splice. slice(start, end) возвращает новый массив с элементами от start до end без изменения исходного массива. splice(start, count) удаляет элементы и может одновременно вставлять новые, что полезно для редактирования данных в месте вызова.
Копирование массива может быть поверхностным или глубоким. Поверхностное копирование через slice() или […arr] дублирует только первый уровень. Для массивов объектов рекомендуется использовать методы глубокого копирования, например через JSON.parse(JSON.stringify(arr)), чтобы изменения в копии не затрагивали исходный массив.
При объединении и разбиении больших массивов стоит учитывать расход памяти. Операции с concat и slice создают новые массивы, поэтому для массивов свыше 100 000 элементов предпочтительно работать с индексами или ссылками на исходные данные, минимизируя создание промежуточных копий.
Использование массивов в функциях и передача по ссылке

Массивы в JavaScript передаются в функции по ссылке, поэтому любые изменения элементов внутри функции отражаются на исходном массиве. Например, function modify(arr) { arr[0] = 10; } изменит первый элемент исходного массива после вызова modify(myArray).
Для предотвращения изменения исходных данных используют поверхностное копирование при передаче: function process(arr) { let copy = […arr]; copy[0] = 0; }. Такой подход сохраняет исходный массив неизменным, позволяя работать с временными изменениями.
Функции могут возвращать новые массивы на основе исходных, используя методы map, filter или slice. Например, function double(arr) { return arr.map(el => el * 2); } создает новый массив без изменения исходного. Это особенно важно при передаче массивов в несколько функций для последовательной обработки.
При работе с массивами объектов рекомендуется глубокое копирование, чтобы изменения в вложенных структурах не затрагивали оригинальные данные. Использование JSON.parse(JSON.stringify(arr)) или специализированных библиотек обеспечивает сохранность исходной структуры при сложных операциях.
Вопрос-ответ:
Какие способы инициализации массивов лучше использовать для больших наборов данных?
Для массивов большого объема предпочтительно использовать конструкторы с указанием длины и последующим заполнением через цикл или метод fill. Это позволяет заранее резервировать память и снижает количество перераспределений при добавлении элементов. Для вычисляемых значений удобно применять Array.from с функцией генерации элементов, что сокращает количество строк кода и упрощает структуру массива.
Когда стоит применять методы map, filter и reduce вместо циклов?
Методы map, filter и reduce удобны для преобразования массивов или получения новых наборов данных без изменения исходного. Они сокращают код и делают логику обработки более наглядной. Циклы for и while остаются полезными, если нужна частичная обработка или оптимизация производительности для очень больших массивов, поскольку методы создают дополнительные функции обратного вызова.
Как выбрать алгоритм поиска элементов в массиве в зависимости от объема данных?
Для небольших или неотсортированных массивов достаточно линейного поиска с перебором всех элементов. Если массив отсортирован, целесообразно использовать двоичный поиск, что сокращает количество проверок до логарифмического значения. При частых повторных поисках полезно создавать вспомогательные структуры, такие как словари или индексы, для ускорения выборки без перебора всего массива.
В каких случаях необходимо делать глубокое копирование массива?
Глубокое копирование требуется, если массив содержит объекты или вложенные структуры, и нужно изменять их без воздействия на исходный массив. Простое поверхностное копирование через slice или оператор spread дублирует только первый уровень, оставляя ссылки на вложенные объекты. Для полного отделения используют JSON.parse(JSON.stringify(arr)) или специализированные функции глубокого клонирования.
Какие подходы применяются для объединения и разбиения массивов с большим количеством элементов?
Для объединения массивов используют concat или оператор spread. Разбиение выполняется методами slice или splice. При больших объемах данных следует учитывать расход памяти: каждая операция создания нового массива увеличивает использование оперативной памяти. В таких случаях целесообразно работать с индексами или ссылками на элементы исходного массива, минимизируя дублирование.





