Содержание статьи

В SQL команды GROUP BY и ORDER BY выполняют разные задачи, хотя обе влияют на результат запроса. GROUP BY объединяет строки с одинаковыми значениями указанной колонки, позволяя применять агрегатные функции, такие как SUM, COUNT, AVG. Это особенно полезно при анализе продаж по регионам или подсчете уникальных пользователей в месяц.
Команда ORDER BY не меняет количество строк, а только сортирует их по возрастанию или убыванию. Например, можно отсортировать список клиентов по дате последнего заказа или отсортировать результаты агрегатной функции для выявления топ-5 продуктов. Понимание порядка выполнения запросов важно: сортировка выполняется после группировки, если обе команды используются вместе.
При работе с большими таблицами неправильное использование GROUP BY или ORDER BY может существенно замедлить запрос. Практическая рекомендация: использовать индексы на колонках для сортировки и группировки, а также ограничивать выборку через WHERE до применения агрегатов и сортировки. Это снижает нагрузку на сервер и ускоряет получение результатов.
В статье будут рассмотрены конкретные примеры синтаксиса и сценарии использования GROUP BY и ORDER BY, включая комбинации обеих команд и ошибки, которые часто встречаются у разработчиков при построении запросов.
Разница между GROUP BY и ORDER BY в SQL
Команда GROUP BY группирует строки таблицы по значениям одной или нескольких колонок, позволяя выполнять агрегатные вычисления на каждой группе. Например, запрос SELECT region, SUM(sales) FROM orders GROUP BY region вернет сумму продаж по каждому региону, сокращая множество строк в одну строку на группу. Без использования агрегатных функций GROUP BY не изменяет результат, но обычно комбинируется с COUNT, SUM, AVG, MIN или MAX.
Как GROUP BY объединяет строки по значениям колонок
Команда GROUP BY объединяет строки, которые имеют одинаковые значения в указанных колонках, создавая отдельные группы для каждой уникальной комбинации. Это позволяет выполнять агрегатные вычисления на уровне группы вместо отдельных строк.
Примеры применения:
- Подсчет количества заказов по каждому клиенту: SELECT customer_id, COUNT(*) FROM orders GROUP BY customer_id.
- Суммирование продаж по каждому продукту: SELECT product_id, SUM(amount) FROM sales GROUP BY product_id.
- Определение среднего значения оценки студентов по курсам: SELECT course_id, AVG(score) FROM grades GROUP BY course_id.
Рекомендации при использовании GROUP BY:
- Все колонки в SELECT, которые не используются в агрегатных функциях, должны быть включены в GROUP BY.
- Использовать индексы на колонках группировки для ускорения выполнения запросов на больших таблицах.
- Проверять корректность комбинации колонок при группировке, чтобы не объединять данные некорректно.
- Совмещать с HAVING для фильтрации групп по агрегатным значениям, например: HAVING SUM(amount) > 1000.
Как ORDER BY сортирует строки по возрастанию и убыванию

Примеры применения:
- Сортировка результатов экзаменов по оценкам: SELECT student_id, score FROM grades ORDER BY score DESC, student_id ASC – сначала по убыванию оценки, затем по идентификатору студента.
Рекомендации при использовании ORDER BY:
- Для больших таблиц использовать индексы на колонках сортировки, чтобы ускорить выполнение запроса.
- При комбинировании с GROUP BY сортировка должна ссылаться на агрегатные функции или колонки группировки.
Использование агрегатных функций с GROUP BY

Команда GROUP BY чаще всего применяется вместе с агрегатными функциями, которые выполняют вычисления внутри каждой группы. Основные функции включают SUM, COUNT, AVG, MIN и MAX. Они позволяют получать сводные данные без необходимости вручную объединять строки.
Примеры практического применения:
- Сумма продаж по каждому региону: SELECT region, SUM(sales) FROM orders GROUP BY region.
- Количество заказов у каждого клиента: SELECT customer_id, COUNT(*) FROM orders GROUP BY customer_id.
- Средняя оценка студентов по курсу: SELECT course_id, AVG(score) FROM grades GROUP BY course_id.
- Нахождение минимальной и максимальной цены товаров в категориях: SELECT category_id, MIN(price), MAX(price) FROM products GROUP BY category_id.
Рекомендации при использовании агрегатных функций с GROUP BY:
- Все колонки в SELECT, которые не участвуют в агрегатах, обязательно включать в GROUP BY.
- При работе с большими объемами данных применять индексы на колонках группировки для ускорения запроса.
- Использовать HAVING для фильтрации групп по агрегатным значениям вместо WHERE, который работает только на исходные строки.
Команда ORDER BY изменяет только порядок строк в результате запроса, не объединяя их и не влияя на количество. Даже без использования GROUP BY она позволяет контролировать, какие строки будут отображены первыми.
Примеры использования:
- Сортировка всех заказов по дате: SELECT * FROM orders ORDER BY order_date DESC – новые заказы показываются первыми.
- Сортировка продуктов по цене: SELECT * FROM products ORDER BY price DESC для выявления самых дорогих товаров.
Рекомендации при использовании ORDER BY без группировки:
- Использовать индексы на колонках сортировки для ускорения запроса на больших таблицах.
- Учитывать, что сортировка может потреблять дополнительную память при больших объемах данных, особенно без индексов.
Комбинирование GROUP BY и ORDER BY в одном запросе
Примеры применения:
- Сумма продаж по продуктам с сортировкой по убыванию: SELECT product_id, SUM(sales) FROM sales GROUP BY product_id ORDER BY SUM(sales) DESC.
- Количество заказов по клиентам, отсортированных по имени: SELECT customer_id, COUNT(*) FROM orders GROUP BY customer_id ORDER BY customer_id ASC.
Рекомендации при комбинировании GROUP BY и ORDER BY:
- Сначала формируются группы с помощью GROUP BY, затем выполняется сортировка агрегированных данных.
- Для ускорения запроса использовать индексы на колонках группировки и колонках, по которым выполняется сортировка.
- При сортировке по агрегатам всегда ссылаться на функцию в ORDER BY, а не на исходные строки.
Ошибки при использовании GROUP BY без SELECT с агрегатами
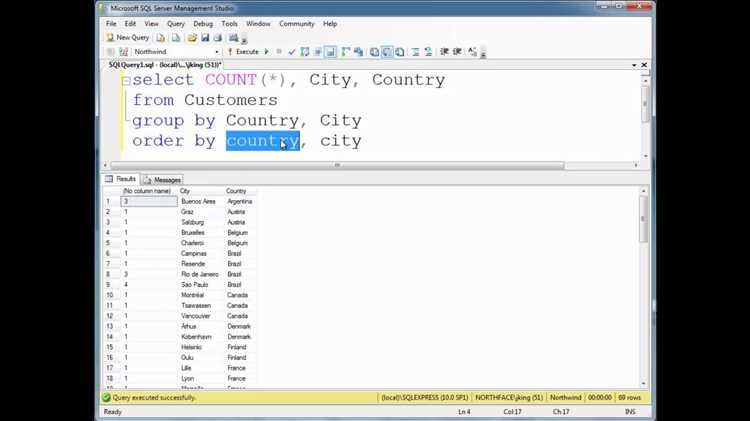
Еще одна ошибка – попытка подсчета агрегатов без явного указания функции. Например, SELECT customer_id, COUNT FROM orders GROUP BY customer_id не сработает, потому что COUNT требует вызова COUNT(*) или COUNT(column_name).
Рекомендации для корректного использования GROUP BY:
- Все колонки в SELECT, которые не агрегируются, должны быть включены в GROUP BY.
- Использовать агрегатные функции для подсчета, суммирования или усреднения данных в группах.
- При сложных запросах проверять совместимость с выбранной СУБД, так как синтаксис и требования к GROUP BY могут отличаться.
- Для фильтрации агрегированных данных использовать HAVING, а не WHERE, который работает только с исходными строками.
Разница в производительности между сортировкой и группировкой
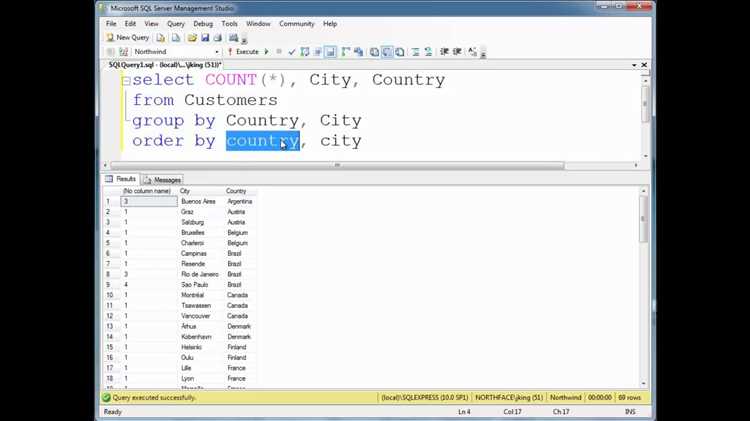
Команды ORDER BY и GROUP BY по-разному влияют на нагрузку на сервер и время выполнения запросов. ORDER BY сортирует все строки в результате, что требует выделения дополнительной памяти и может замедлить запрос на больших таблицах без индексов.
GROUP BY объединяет строки в группы и выполняет агрегатные вычисления. Производительность сильно зависит от количества уникальных значений в колонке группировки и от наличия индексов. Чем больше групп, тем больше ресурсов требуется для агрегации.
Практические рекомендации:
- Использовать индексы на колонках, по которым выполняется сортировка и группировка.
- Сначала фильтровать данные через WHERE, чтобы уменьшить объем для GROUP BY и ORDER BY.
- При необходимости сортировать агрегированные данные, выполнять ORDER BY после GROUP BY для минимизации объема сортировки.
- Для больших таблиц рассматривать частичную агрегацию или использование предварительно вычисленных сводных таблиц.
Следует учитывать, что на больших выборках GROUP BY с агрегатными функциями может работать быстрее, чем ORDER BY, если сортировка выполняется по колонкам без индекса, так как агрегирование часто может быть выполнено через хеш-алгоритмы, а сортировка требует полной перестановки строк.
Вопрос-ответ:
Можно ли использовать ORDER BY без GROUP BY и какие результаты это даст?
Да, ORDER BY можно применять к любой выборке без GROUP BY. В этом случае команда только сортирует строки по указанной колонке или нескольким колонкам, не объединяя их. Например, SELECT * FROM orders ORDER BY order_date DESC выведет все заказы, начиная с самых последних, но каждая строка останется отдельной. Это удобно для анализа последовательности событий или для вывода списка в определенном порядке.
Что произойдет, если в SELECT добавить колонку, которая не входит в GROUP BY и не агрегируется?
Если указать такую колонку, большинство СУБД выдадут ошибку. Например, запрос SELECT customer_id, order_date FROM orders GROUP BY customer_id не сработает, потому что order_date не агрегируется и не входит в GROUP BY. Решение — включить колонку в GROUP BY или использовать агрегатную функцию, например MIN(order_date) или MAX(order_date), чтобы получить конкретное значение для каждой группы.
Можно ли сортировать данные по агрегатной функции после GROUP BY?
Да, это распространенная практика. После формирования групп через GROUP BY можно использовать ORDER BY для сортировки по результатам агрегатной функции. Например, SELECT product_id, SUM(sales) FROM sales GROUP BY product_id ORDER BY SUM(sales) DESC выведет продукты с наибольшей суммой продаж первыми. Такой подход позволяет быстро выявлять лидеров или наименее успешные позиции в наборе данных.
Какие индексы полезно создать для ускорения GROUP BY и ORDER BY?
Для GROUP BY стоит создавать индексы на колонках, по которым выполняется группировка, особенно если таблица большая и количество уникальных значений невелико. Для ORDER BY индексы на колонках сортировки сокращают необходимость полного сканирования таблицы. Если запрос использует и GROUP BY, и ORDER BY, индекс можно создавать на комбинации колонок, соответствующих обоим условиям, чтобы минимизировать время выполнения.
Почему GROUP BY может работать быстрее, чем ORDER BY на больших таблицах?
GROUP BY формирует группы и применяет агрегаты, что может выполняться через хеширование или промежуточные структуры, уменьшающие количество обрабатываемых строк. ORDER BY же требует полной перестановки всех строк для сортировки, что потребляет больше памяти и времени. На больших таблицах без индексов сортировка может быть значительно медленнее, чем агрегация через GROUP BY, особенно если количество уникальных групп относительно невелико.