Содержание статьи

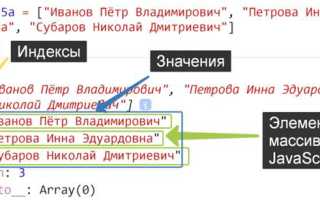
Индекс – это точное указание на местоположение данных внутри структуры, которое позволяет обращаться к элементу без перебора всей коллекции. В массивах и списках индекс обычно представлен целым числом, в базах данных – набором полей, формирующих ключ для ускоренного поиска и сортировки. Использование индексов снижает количество операций сравнения и ускоряет доступ к информации.
При проектировании таблиц SQL индексы делятся на первичные и вторичные. Первичный индекс обеспечивает уникальность строк и оптимизирует выборку по ключевому полю. Вторичный индекс ускоряет поиск по любому другому атрибуту, но увеличивает нагрузку при вставке и обновлении данных. Правильный выбор типа индекса зависит от частоты операций чтения и записи.
В языках программирования индексы применяются для работы с массивами, строками и списками. В Python отрицательные индексы позволяют обращаться к элементам с конца последовательности, а в C++ и Java индексы начинаются с нуля, что важно учитывать при реализации алгоритмов. Ошибки в индексах часто приводят к выходу за пределы массива и сбоям программы.
Оптимизация с помощью индексов требует анализа структуры данных и характера операций. Для частых точечных запросов подходят хеш-таблицы, для диапазонных выборок – деревья поиска. Индексы также сокращают время обработки больших текстов, упрощают сортировку и фильтрацию, а их правильное использование напрямую отражается на производительности приложений.
Индекс в программировании: принципы и применение

Индекс в программировании представляет собой ссылку на конкретное местоположение элемента в структуре данных. В массивах и списках он обычно выражается целым числом, указывающим позицию, а в базах данных индекс формируется на основе одного или нескольких полей для ускорения выборки. Применение индекса позволяет сократить количество операций поиска с линейного до логарифмического времени, что критично при обработке больших массивов данных.
Принцип работы индекса в базе данных основан на структуре данных: B-деревья используются для сортированных таблиц и обеспечивают быстрый диапазонный поиск, хеш-таблицы – для точного доступа по ключу. Первичный индекс гарантирует уникальность записей и ускоряет выборку по ключевому полю, вторичные индексы оптимизируют поиск по дополнительным атрибутам, но увеличивают нагрузку при вставке и обновлении данных.
В языках программирования индексы применяются для работы с массивами, строками и списками. В Python отрицательные индексы позволяют обращаться к элементам с конца последовательности без вычисления длины, в C++ и Java индексация начинается с нуля, что важно учитывать при алгоритмических расчетах. Неверное использование индекса приводит к выходу за границы массива и ошибкам выполнения.
Практическое применение индексов включает ускорение SQL-запросов, оптимизацию циклов обработки массивов, упрощение поиска и сортировки текстовых данных. Выбор структуры данных с учетом типов индексов позволяет уменьшить время выполнения операций и нагрузку на память, повышая производительность программ без изменения алгоритмов обработки данных.
Как индекс ускоряет поиск элементов в массиве
Индекс в массиве представляет собой целое число, указывающее позицию элемента, что позволяет обращаться к нему напрямую, без перебора всей коллекции. В стандартных массивных структурах доступ по индексу выполняется за константное время O(1), что значительно сокращает затраты на поиск по сравнению с последовательным обходом O(n).
Использование индекса особенно важно при обработке больших массивов данных. Например, для массива из 1 миллиона элементов последовательный поиск потребует до 1 миллиона операций сравнения, тогда как обращение по индексу сразу возвращает нужный элемент. Это критично при алгоритмах сортировки, фильтрации и выборки.
Таблица ниже иллюстрирует разницу между поиском с использованием индекса и без него:
| Метод поиска | Время доступа | Количество операций для 1 млн элементов |
|---|---|---|
| Последовательный поиск | O(n) | До 1 000 000 сравнений |
| Доступ по индексу | O(1) | 1 операция |
При работе с многомерными массивами индексы применяются для указания позиции в каждой размерности. Например, для двумерного массива A[i][j] индекс i выбирает строку, а j – столбец. Это позволяет быстро обращаться к любому элементу и уменьшает сложность алгоритмов обработки данных.
Рекомендация: всегда использовать индексы для прямого доступа к элементам массивов и списков, особенно при больших объемах данных или частых операциях выборки. Это уменьшает нагрузку на процессор и сокращает время выполнения программ.
Использование индексов в базах данных для фильтрации записей

Индексы в базах данных создаются на одном или нескольких столбцах таблицы для ускорения выборки записей. При фильтрации данных индексы позволяют СУБД быстро находить нужные строки без полного сканирования таблицы, снижая время выполнения запросов с O(n) до O(log n) для деревьев поиска или до O(1) для хешированных структур.
Типы индексов для фильтрации:
- Первичный индекс – гарантирует уникальность записей и ускоряет выборку по ключевому полю.
- Вторичный индекс – используется для поиска по дополнительным колонкам, оптимизируя фильтры и сортировки.
- Составной индекс – объединяет несколько полей, что сокращает время выполнения сложных запросов с несколькими условиями.
Практические рекомендации:
- Создавать индексы на колонках, часто используемых в WHERE и JOIN условиях.
- Использовать составные индексы для запросов с несколькими фильтрами, соблюдая порядок колонок по частоте фильтрации.
- Регулярно анализировать статистику использования индексов и удалять редко применяемые, чтобы не замедлять операции INSERT и UPDATE.
- Для диапазонных запросов предпочтительнее B-деревья, для точного поиска по ключу – хеш-индексы.
Применение индексов позволяет ускорить фильтрацию записей в десятки и сотни раз при больших объемах данных, сокращая нагрузку на процессор и время отклика приложения.
Различие между первичными и вторичными индексами
Первичный индекс создается на столбце или наборе столбцов, обеспечивая уникальность записей в таблице. Он автоматически формируется при создании первичного ключа и упорядочивает данные физически или логически в структуре таблицы, что ускоряет выборку и поддерживает целостность данных.
Вторичный индекс создается для ускорения поиска по другим колонкам, не являющимся ключевыми. Он не влияет на уникальность записей и не изменяет физическое расположение данных, а лишь хранит ссылки на строки, удовлетворяющие условиям поиска. Вторичные индексы полезны при частых фильтрах и сортировках по вспомогательным полям.
Отличия в использовании:
- Первичный индекс: оптимизирован для выборки по ключу, минимизирует время доступа к строке, важен для операций JOIN и идентификации записей.
- Вторичный индекс: ускоряет выборку по дополнительным условиям, увеличивает нагрузку на INSERT и UPDATE, требует регулярного анализа использования для оптимизации.
Рекомендации: создавать первичный индекс только на ключевом поле, вторичные – на колонках, которые часто используются в WHERE и ORDER BY. Сочетание этих индексов позволяет достичь баланса между скоростью выборки и нагрузкой на изменение данных.
Индексы в строках и их роль при работе с текстовыми данными

Индекс в строке указывает на позицию конкретного символа, позволяя напрямую обращаться к элементу без перебора всей последовательности. В языках программирования, таких как Python, Java и C++, индексация начинается с нуля, а в Python поддерживаются отрицательные индексы для обращения с конца строки.
Использование индексов упрощает операции поиска и замены символов или подстрок. Например, метод substring с указанием начального и конечного индекса позволяет извлечь нужную часть текста за константное время на доступ к отдельным символам. Для поиска подстрок эффективны алгоритмы с использованием индексов, такие как KMP или Boyer-Moore, которые минимизируют количество сравнений.
Практические рекомендации:
- Использовать индексы для извлечения подстрок и символов без создания дополнительных копий строки.
- Применять отрицательные индексы в Python для упрощения работы с последними символами.
- При больших текстовых данных индексировать позиции ключевых слов для ускорения поиска и анализа.
Индексы также применяются в обработке массивов строк, позволяя быстро обращаться к конкретной строке и символу внутри нее. Это сокращает время выполнения алгоритмов поиска, фильтрации и модификации текстовых данных, особенно при обработке больших объемов информации.
Ошибки при работе с индексами и как их избежать

Другой частой проблемой является неправильное использование отрицательных индексов. В Python отрицательные индексы считаются с конца последовательности, и их неправильное применение может вернуть неожиданные элементы. В языках без поддержки отрицательных индексов использование отрицательных значений приводит к ошибкам.
Ошибки могут возникнуть при неверном порядке индексов в многомерных массивах или таблицах. Например, обращение A[j][i] вместо A[i][j] изменяет строку и столбец, что приводит к некорректным результатам при обработке данных.
Рекомендации для предотвращения ошибок:
- Всегда проверять длину массива или строки перед обращением по индексу.
- Использовать циклы с правильными границами и встроенные методы перебора, чтобы исключить выход за пределы.
- При работе с многомерными структурами соблюдать порядок индексов и документировать назначение каждой размерности.
- Тестировать функции с граничными значениями, включая нулевые и максимальные индексы.
Соблюдение этих правил позволяет избежать сбоев программы, повышает надежность обработки данных и минимизирует затраты на отладку при работе с индексами.
Применение индексов в структурах данных: списки, деревья и хеш-таблицы

В списках индексы обеспечивают прямой доступ к элементам по позиции, что сокращает время выполнения операций выборки до O(1) для массивов. В связных списках индексация отсутствует, поэтому для доступа к элементу требуется последовательный обход, что увеличивает сложность до O(n).
В деревьях индексы реализуются через ключи узлов, упорядоченных по определенному правилу (например, в бинарных деревьях поиска). Это позволяет выполнять операции поиска, вставки и удаления за O(log n) при сбалансированном дереве. Составные индексы в деревьях применяются для ускорения поиска по нескольким критериям одновременно.
В хеш-таблицах индекс формируется с помощью хеш-функции, которая преобразует ключ в позицию массива. Доступ к элементу осуществляется за O(1) в среднем случае. Коллизии решаются методами цепочек или открытой адресации. Для больших объемов данных рекомендуется выбирать хеш-функции с равномерным распределением ключей.
Рекомендации по применению индексов:
- Использовать массивы с прямой индексацией для частого доступа к элементам по позиции.
- Выбирать деревья для сортированных данных и диапазонных запросов.
- Применять хеш-таблицы для быстрого поиска по уникальным ключам.
- Комбинировать структуры и индексы в зависимости от характера операций: выборка, вставка, удаление или диапазонные запросы.
Правильное использование индексов в этих структурах позволяет значительно снизить время выполнения операций и уменьшить нагрузку на память при обработке больших массивов и баз данных.
Вопрос-ответ:
Почему индекс в массиве ускоряет доступ к элементам по сравнению с последовательным поиском?
Индекс представляет собой позицию элемента в массиве, что позволяет напрямую обратиться к нужному значению без перебора всех элементов. В стандартных массивах доступ по индексу выполняется за константное время, тогда как последовательный поиск требует проверки каждого элемента до нахождения совпадения, увеличивая время выполнения при больших объемах данных.
В чем разница между первичным и вторичным индексом в базе данных?
Первичный индекс создается на ключевом поле таблицы и обеспечивает уникальность каждой записи, а также упорядочивает данные для ускорения поиска по ключу. Вторичный индекс создается для других колонок и ускоряет выборку по дополнительным критериям, но не гарантирует уникальности и добавляет нагрузку при вставке и обновлении строк.
Как индексы применяются при работе со строками в программировании?
Индексы в строках указывают на позицию символа, что позволяет обращаться к конкретной букве или подстроке напрямую. Это ускоряет операции извлечения, замены или поиска подстрок. В Python, например, отрицательные индексы позволяют обращаться к символам с конца строки без вычисления длины.
Какие ошибки чаще всего возникают при использовании индексов и как их избежать?
Наиболее распространенные ошибки связаны с выходом за границы массива или строки, неправильным порядком индексов в многомерных массивах и неверным использованием отрицательных индексов. Для предотвращения таких ошибок рекомендуется проверять длину структуры перед обращением, соблюдать порядок индексов и тестировать функции с граничными значениями.
В каких структурах данных индексы играют ключевую роль и как это влияет на производительность?
Индексы важны в массивах, деревьях и хеш-таблицах. В массивах индекс позволяет мгновенно получить элемент по позиции. В деревьях индексы реализуются через ключи узлов и ускоряют поиск, вставку и удаление. В хеш-таблицах индекс формируется хеш-функцией, что обеспечивает быстрый доступ по ключу. Выбор структуры зависит от типа операций: выборка, вставка или диапазонные запросы.
Как индексы влияют на скорость выполнения SQL-запросов с фильтрацией?
Индексы уменьшают количество строк, которые необходимо проверить при фильтрации, направляя СУБД сразу к нужным записям. Например, при фильтре по столбцу с индексом поиск выполняется за O(log n) в случае дерева или почти за O(1) при хешировании, тогда как без индекса база перебирает все строки, что занимает значительно больше времени, особенно при больших таблицах.
Можно ли использовать отрицательные индексы в других языках программирования кроме Python?
Отрицательные индексы в Python позволяют обращаться к элементам с конца последовательности, сокращая необходимость вычислять длину. В большинстве других языков, таких как C++ или Java, отрицательные индексы не поддерживаются, и их использование приведет к ошибкам или выходу за границы массива. Для имитации подобного поведения нужно явно вычислять позицию с конца, вычитая индекс из длины массива или строки.