Содержание статьи

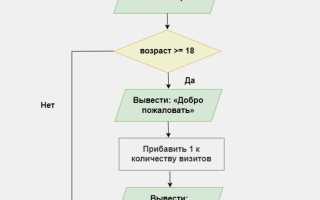
Алгоритм – это пошаговое описание процесса решения задачи. В программировании алгоритмы представляют собой последовательности действий, которые используются для выполнения различных операций, от сортировки данных до оптимизации ресурсов. Разработка правильного алгоритма напрямую влияет на скорость работы программы и её способность обрабатывать большие объемы информации.
Выбор подходящего алгоритма требует анализа задачи, которая стоит перед разработчиком. Например, при работе с большими массивами данных важно выбирать алгоритм сортировки, который минимизирует количество операций и эффективно использует память. Для задач поиска и сортировки существуют разные подходы, такие как быстрый поиск или сортировка слиянием, каждый из которых оптимален в определённых условиях.
Одним из ключевых аспектов алгоритмов является их способность справляться с изменяющимися условиями и масштабами данных. Современные вычислительные задачи, такие как анализ данных в реальном времени или машинное обучение, требуют особых алгоритмов, которые способны эффективно адаптироваться к новым входным данным и меняющимся параметрам.
Оптимизация алгоритмов для конкретных платформ и задач – ещё один важный аспект, который стоит учитывать при разработке. Алгоритм, который хорошо работает на одном устройстве, может быть неэффективным на другом, из-за различий в архитектуре или доступной памяти. Программисты часто используют профилирование и тестирование для выявления «узких мест» в алгоритмах и их улучшения.
Как выбрать алгоритм для решения конкретной задачи
Выбор алгоритма зависит от нескольких факторов, таких как тип задачи, размер данных, требования к скорости выполнения и ограничения по памяти. Важно правильно определить, какие критерии важны для вашей программы, и на основе этого выбирать оптимальный подход.
1. Анализ задачи: Сначала нужно понять, что именно требуется от алгоритма. Если задача связана с обработкой и сортировкой больших объёмов данных, то наиболее подходящими будут алгоритмы сортировки, такие как сортировка слиянием или быстрая сортировка, которые демонстрируют хорошую производительность при больших массивах. Для поиска элемента в отсортированном массиве лучше выбрать бинарный поиск, который работает за логарифмическое время.
2. Оценка сложности: Оценка времени выполнения и использования памяти является важным аспектом при выборе алгоритма. Программисты часто используют асимптотику алгоритмов, чтобы понять, как алгоритм будет вести себя при увеличении объема данных. Например, алгоритм сортировки слиянием имеет сложность O(n log n), что делает его более предпочтительным, чем сортировка пузырьком с O(n²) при работе с большими массивами.
3. Простота реализации: Иногда для небольших задач важно не только выбрать быстрый алгоритм, но и учесть его сложность для реализации. Простой в реализации алгоритм может быть предпочтительнее сложного, если время разработки ограничено, а данные – не слишком большие. Например, если необходимо быстро найти минимальный элемент в неотсортированном списке, достаточно пройти по всему массиву за O(n), вместо более сложных решений.
4. Ограничения по памяти: Некоторые алгоритмы требуют значительных объёмов памяти для хранения данных, что может быть критичным на устройствах с ограниченными ресурсами. Для таких случаев часто выбирают алгоритмы с линейной сложностью по памяти. Например, алгоритм быстрой сортировки, в отличие от сортировки слиянием, может работать с меньшими требованиями к памяти, если использовать его в месте, где важна экономия памяти.
5. Устойчивость к ошибкам и внешним условиям: Для критичных приложений, где возможны сбои или потери данных, следует выбирать алгоритмы с проверенной стабильностью. Алгоритм должен быть не только быстрым и экономным по памяти, но и надёжным в любых условиях.
Основные типы алгоритмов в программировании

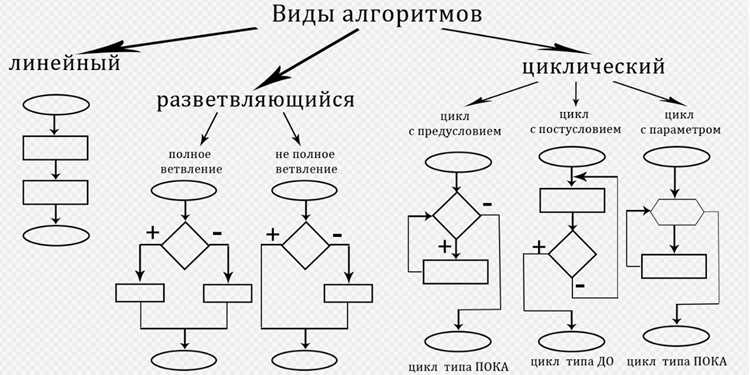
Алгоритмы в программировании можно разделить на несколько типов в зависимости от их назначения и структуры. Каждый тип решает определённые задачи, и выбор подходящего зависит от особенностей проекта.
1. Алгоритмы поиска: Эти алгоритмы предназначены для нахождения элементов в различных структурах данных, таких как массивы, списки, деревья и графы. К наиболее известным относятся линейный поиск (O(n)) и бинарный поиск (O(log n)), который применяется в отсортированных данных. Бинарный поиск более эффективен, но требует предварительной сортировки данных.
2. Алгоритмы сортировки: Сортировка данных – одна из самых часто встречающихся задач. Алгоритмы сортировки делятся на несколько типов в зависимости от скорости и объёма памяти. Примеры включают пузырьковую сортировку (O(n²)), сортировку слиянием (O(n log n)), быструю сортировку (O(n log n) в среднем случае) и сортировку кучей (O(n log n)). Выбор алгоритма зависит от объёма данных и требований к производительности.
3. Алгоритмы для работы с графами: Графы – это структуры данных, состоящие из вершин и рёбер. Алгоритмы, работающие с графами, включают поиск в глубину (DFS) и поиск в ширину (BFS). Они используются для решения задач маршрутизации, анализа связности графа и других задач, например, нахождения кратчайшего пути с помощью алгоритма Дейкстры.
4. Алгоритмы динамического программирования: Этот тип алгоритмов используется для оптимизации задач, которые могут быть разбиты на подзадачи с перекрывающимися подпроблемами. Алгоритмы динамического программирования, такие как метод “снизу-вверх”, позволяют значительно ускорить решение, избегая повторных вычислений. Примером является алгоритм для нахождения наибольшей общей подстроки или задачи о рюкзаке.
5. Жадные алгоритмы: Жадные алгоритмы принимают локальные оптимальные решения на каждом шаге, с целью получить глобальное оптимальное решение. Примером является алгоритм Краскала для поиска минимального остовного дерева. Хотя жадные алгоритмы не всегда дают глобальный оптимум, они обычно имеют низкую сложность и подходят для многих задач.
6. Алгоритмы разделяй и властвуй: Этот метод используется для решения задач путём их разделения на меньшие подзадачи, которые решаются независимо, а затем объединяются. Алгоритмы сортировки слиянием и быстрая сортировка являются классическими примерами, где принцип «разделяй и властвуй» помогает эффективно решать задачу с минимальными затратами.
7. Алгоритмы обработки строк: Строки – это последовательности символов, и для их обработки существует несколько специализированных алгоритмов, таких как поиск подстроки (алгоритм Кнута-Морриса-Пратта) и алгоритм Бойера-Мура. Эти алгоритмы предназначены для эффективного поиска подстрок в строках или для анализа текстов, что часто требуется в задачах поиска и парсинга.
Как алгоритмы влияют на производительность программ
Выбор алгоритма определяет, как быстро программа будет решать задачу, а также, сколько ресурсов она будет потреблять. Неправильно выбранный алгоритм может значительно замедлить выполнение программы или привести к ненужным расходам памяти.
1. Время выполнения: Один из ключевых факторов производительности программы – это время, которое алгоритм тратит на выполнение. Например, алгоритм сортировки слиянием (O(n log n)) будет работать быстрее, чем сортировка пузырьком (O(n²)), особенно при больших данных. Алгоритм с меньшей асимптотической сложностью в идеальных условиях всегда будет работать быстрее.
- Если нужно сортировать миллион элементов, алгоритм сортировки слиянием окажется значительно быстрее пузырьковой сортировки.
- Алгоритмы поиска с меньшей сложностью, такие как бинарный поиск (O(log n)), будут работать гораздо быстрее линейного поиска (O(n)), особенно на больших объёмах данных.
2. Использование памяти: Память также является важным ресурсом. Некоторые алгоритмы требуют большого объёма памяти для хранения промежуточных данных. Например, алгоритм сортировки слиянием требует дополнительной памяти для хранения копий данных, в то время как быстрая сортировка работает «на месте» и использует меньше памяти. Использование памяти напрямую влияет на масштабируемость программы, особенно в условиях ограниченных ресурсов.
- Алгоритмы с высоким расходом памяти, такие как динамическое программирование, требуют внимательного подхода при реализации на устройствах с ограниченной памятью.
- Алгоритм, использующий дополнительную память, может замедлить выполнение программы из-за необходимости копировать и хранить данные, особенно если объём данных велик.
3. Масштабируемость: Когда количество данных или количество пользователей программы увеличивается, алгоритм должен оставаться работоспособным без значительного ухудшения производительности. Например, алгоритм сортировки слиянием будет работать примерно одинаково хорошо, независимо от объёма данных, тогда как алгоритм с пузырьковой сортировкой может стать неприемлемым при большом объёме данных.
- Для большого объёма данных важен выбор алгоритма с низкой сложностью, чтобы избежать значительных задержек и перегрузки системы.
- Если приложение должно обрабатывать данные в реальном времени, алгоритм должен быть не только быстрым, но и отзывчивым при масштабировании нагрузки.
4. Параллельность и распределённые системы: В многозадачных и распределённых системах выбор алгоритма может повлиять на скорость параллельных вычислений. Некоторые алгоритмы легче адаптируются к многозадачности, такие как алгоритмы сортировки, которые можно параллелить, разделяя данные и обрабатывая их одновременно.
- Алгоритмы с минимальной зависимостью между элементами могут быть легко распараллелены, что значительно повышает производительность в многозадачных системах.
- Некоторые алгоритмы, такие как сортировка слиянием, могут быть эффективно реализованы на многозадачных системах для увеличения производительности при обработке больших объёмов данных.
Роль алгоритмов в обработке больших данных

Обработка больших данных требует использования алгоритмов, которые могут эффективно управлять огромными объёмами информации. Стандартные алгоритмы, подходящие для небольших данных, не всегда могут справиться с задачами, когда объёмы информации растут до миллиардов строк. Для таких случаев разработаны специализированные подходы, оптимизированные для работы с Big Data.
1. Алгоритмы MapReduce: Этот алгоритм широко используется для обработки больших данных, особенно в распределённых системах, таких как Hadoop. MapReduce разделяет задачу на два этапа: «Map» – разделение данных на маленькие блоки, и «Reduce» – агрегирование результатов. Это позволяет эффективно обрабатывать данные в параллельных вычислениях, снижая время обработки на многозадачных системах.
2. Алгоритмы для обработки потоков данных: В реальном времени потоки данных могут поступать постоянно, и их нужно обрабатывать по мере поступления. Алгоритмы, такие как Sliding Window, позволяют анализировать данные, не храня их полностью в памяти, что критично для систем с ограниченными ресурсами. Алгоритмы потоковой обработки данных оптимальны для мониторинга в реальном времени, например, в IoT или системах логирования.
3. Алгоритмы кластеризации: Для анализа больших данных часто необходимо группировать схожие элементы, что делает алгоритмы кластеризации, такие как K-средние и DBSCAN, важными. Они позволяют выявлять паттерны и сегменты в данных, что полезно при анализе поведения пользователей, обработке изображений или текстов. Алгоритм DBSCAN, например, эффективен для работы с шумными данными, где нужно выделить плотные группы без явных кластерных центров.
4. Алгоритмы для работы с графами: В обработке больших данных часто встречаются задачи, связанные с графами, такие как анализ социальных сетей или оптимизация маршрутов. Алгоритмы поиска в графах, такие как алгоритм Дейкстры и алгоритм Беллмана-Форда, находят своё применение в таких областях. Эффективные алгоритмы обхода графа позволяют работать с сетями, состоящими из миллиардов рёбер и узлов, с минимальными затратами ресурсов.
5. Алгоритмы с параллельной обработкой: Для эффективной работы с большими данными важно использовать алгоритмы, поддерживающие параллельные вычисления. Алгоритмы, такие как многозадачность или распределённые вычисления, могут ускорить обработку данных за счёт распределения работы между несколькими процессами или узлами сети. Это особенно важно при работе с хранилищами данных, такими как Hadoop или Spark, где задачи разделяются между множеством вычислительных узлов.
6. Алгоритмы для анализа текстов и поисковых систем: Для обработки больших объёмов текстовой информации применяются алгоритмы для индексирования и поиска, такие как алгоритмы обратного индексирования и поиска по тексту. Такие подходы оптимальны для систем, которые требуют быстрого поиска по миллиардам документов, например, в поисковых системах или в обработке логов.
Как отлаживать и тестировать алгоритмы в реальных проектах

Отладка и тестирование алгоритмов в реальных проектах требуют систематического подхода, так как ошибки могут возникать в самых разных частях программы. Для обеспечения корректности алгоритмов и их оптимальности важно использовать несколько методов отладки и тестирования.
1. Юнит-тестирование: Каждый алгоритм должен быть протестирован на основе заранее подготовленных тестов. Юнит-тестирование позволяет проверить работу алгоритма на небольших входных данных и убедиться, что он выполняет требуемую задачу. Тесты должны покрывать не только стандартные случаи, но и граничные значения (например, пустые массивы или большие объёмы данных), чтобы проверить стабильность работы алгоритма в разных условиях.
- Используйте фреймворки для юнит-тестирования, такие как JUnit для Java или pytest для Python, чтобы автоматизировать процесс тестирования.
- Создавайте тесты, которые проверяют не только правильность, но и производительность алгоритмов при увеличении объёма данных.
2. Профилирование: Для оценки производительности алгоритмов используется профилирование, которое помогает выявить узкие места в коде. Профилировщики анализируют, сколько времени алгоритм тратит на выполнение, и помогают оптимизировать его части, которые требуют наибольших затрат. Программисты могут использовать инструменты, такие как gprof или VisualVM, для анализа времени выполнения различных частей алгоритма.
3. Логирование: В процессе разработки важно вести логирование ключевых шагов выполнения алгоритма, особенно если алгоритм работает с большими данными. Логи помогут отслеживать, где именно происходит сбой, если алгоритм не работает как ожидается. При необходимости можно включить детализированные логи для анализа внутренних состояний данных.
- Записывайте входные и выходные данные, чтобы можно было воспроизвести ошибку и исследовать её причины.
4. Тестирование на реальных данных: Тестирование алгоритмов на реальных данных позволяет выявить проблемы, которые не всегда видны при использовании искусственных наборов данных. Например, алгоритмы, которые работают хорошо на теоретических примерах, могут столкнуться с проблемами при обработке неструктурированных или неполных данных. Для этого важно работать с реальными входными данными, которые могут содержать ошибки, пропуски или нестандартные форматы.
5. Модульное тестирование и рефакторинг: В процессе разработки важно не только протестировать алгоритм, но и регулярно проводить рефакторинг кода, улучшая его структуру и читаемость. Это особенно важно при работе с большими проектами, где сложность алгоритмов может увеличиваться. Модульное тестирование позволяет поддерживать стабильность программы на протяжении всей разработки, а регулярное обновление и улучшение алгоритмов помогает поддерживать их эффективность.
6. Стресс-тестирование и нагрузочное тестирование: Чтобы убедиться, что алгоритм будет работать корректно в условиях высокой нагрузки, его необходимо протестировать при экстремальных данных. Стресс-тестирование позволяет выявить, как алгоритм ведет себя при максимальных объёмах данных, например, когда количество элементов в коллекции достигает миллиардов.
- Используйте генераторы случайных данных для создания тестов с большими объёмами информации.
- Применяйте нагрузочные тесты, чтобы проверить, как алгоритм ведет себя при пиковых значениях нагрузки.
Машинное обучение и алгоритмы: как они работают в паре
1. Алгоритмы обучения с учителем: Эти алгоритмы работают с размеченными данными, где каждое входное значение имеет соответствующую метку. Машинное обучение с учителем используется для задач классификации и регрессии, и алгоритмы играют ключевую роль в обучении модели.
- Логистическая регрессия: Простой и эффективный алгоритм для бинарной классификации. Применяется для задач, таких как предсказание вероятности события.
- Деревья решений: Используются для создания интерпретируемых моделей, где каждое решение разбивает данные на подмножества, что удобно для анализа.
- Метод опорных векторов (SVM): Хорошо работает в высокоразмерных пространствах, где важно разделить данные с минимальной ошибкой. Применяется в задачах классификации, например, в распознавании лиц.
2. Алгоритмы обучения без учителя: В этих алгоритмах модель обучается на неразмеченных данных, и цель состоит в том, чтобы найти скрытые закономерности в данных без предварительного указания меток.
- K-средние: Один из самых популярных алгоритмов кластеризации. Он группирует данные в K кластеров, минимизируя внутрикластерное расстояние.
- DBSCAN: Использует плотностные критерии для выделения кластеров. Отличается тем, что не требует заранее определённого числа кластеров и хорошо справляется с шумными данными.
- Алгоритм главных компонент (PCA): Используется для снижения размерности данных, сохраняя основные признаки, что помогает улучшить производительность алгоритмов при обработке больших данных.
3. Алгоритмы обучения с подкреплением: В отличие от обучения с учителем и без учителя, обучение с подкреплением фокусируется на обучении через взаимодействие с окружением. Агент выполняет действия, получает награды или штрафы, и на основе этого изменяет свою стратегию.
- Q-обучение: Используется для поиска оптимальной стратегии в процессе взаимодействия с окружающей средой. Отличается тем, что модель может обучаться на основе опыта, а не на заранее размеченных данных.
- Алгоритм Политики градиента: Применяется для более сложных задач, таких как робототехника, где агент должен самостоятельно находить оптимальную политику для выполнения действий в различных состояниях.
4. Комбинированные алгоритмы: В современных системах машинного обучения часто используются гибридные подходы, где несколько алгоритмов работают вместе, чтобы повысить точность и производительность моделей.
- Случайный лес: Алгоритм, состоящий из множества деревьев решений. Каждый из них обучается на случайном подмножестве данных, и итоговый результат вычисляется как усреднённое значение их предсказаний.
- Градиентный бустинг: Метод ансамблирования, где несколько слабых моделей комбинируются в одну более мощную. Он часто используется для задач регрессии и классификации и демонстрирует высокую точность.
Таким образом, алгоритмы машинного обучения работают в паре с данными, чтобы строить модели, которые могут извлекать полезную информацию и делать предсказания. Выбор правильного алгоритма зависит от типа задачи, объёма и качества данных, а также требований к скорости и точности модели.
Вопрос-ответ:
Что такое алгоритм в программировании и как он влияет на работу программы?
Алгоритм — это последовательность шагов, которые программа выполняет для решения определённой задачи. От правильности и эффективности алгоритма зависит, насколько быстро и корректно программа будет решать поставленную задачу. Например, при обработке больших объёмов данных важно выбрать алгоритм, который минимизирует время работы и использует оптимальные ресурсы.
Какие бывают типы алгоритмов в программировании и в чём их отличие?
Алгоритмы можно разделить на несколько типов: алгоритмы поиска, сортировки, динамического программирования, графовые и многие другие. К примеру, алгоритмы сортировки могут быть быстрыми (быстрая сортировка) или медленными (сортировка пузырьком). Выбор типа зависит от задачи — быстрые алгоритмы подойдут для больших данных, в то время как простые алгоритмы могут быть достаточно хороши для небольших наборов.
Как выбрать правильный алгоритм для решения задачи?
Выбор алгоритма зависит от типа задачи, объёма данных и ограничений по времени и памяти. Для задач, где данные небольшие, можно использовать простые алгоритмы, такие как сортировка пузырьком. Если данные большие или требуют оптимизации, стоит рассмотреть более сложные методы, например, сортировку слиянием или быструю сортировку. Важно учитывать как временную сложность, так и использование памяти.
Почему алгоритмы важны для производительности программы?
Алгоритмы непосредственно влияют на скорость работы программы. Например, алгоритмы с высокой временной сложностью, такие как сортировка пузырьком, могут сильно замедлить выполнение программы при большом объёме данных. Напротив, алгоритмы с низкой сложностью, такие как быстрая сортировка или бинарный поиск, позволяют значительно улучшить производительность. Правильный выбор алгоритма позволяет обеспечить стабильную работу программы даже при увеличении объёмов данных.
Как тестировать алгоритмы, чтобы убедиться в их корректности и эффективности?
Тестирование алгоритмов включает несколько этапов. Во-первых, проводится юнит-тестирование для проверки правильности работы алгоритма на небольших, заранее подготовленных данных. Далее, выполняется нагрузочное тестирование, чтобы оценить производительность при большом объёме данных. Также важно использовать профилировщики для анализа времени выполнения алгоритма и выявления «узких мест». Для повышения точности стоит тестировать алгоритм на реальных данных, которые могут содержать ошибки или нестандартные форматы.