Добавление записи в базу данных требует понимания структуры таблицы и типов данных, которые она поддерживает. Перед вставкой необходимо определить уникальные ключи, обязательные поля и ограничения на значения, чтобы избежать ошибок при сохранении.
Для работы с базой важно подготовить данные заранее. Например, если поле ожидает дату в формате YYYY-MM-DD, любые отклонения приведут к сбою запроса. Аналогично числовые поля не принимают текстовые значения, а строки должны быть экранированы, если содержат специальные символы.
В большинстве систем управления базами данных (MySQL, PostgreSQL, SQLite) используется команда INSERT. Она позволяет вставить одну или несколько записей за один запрос. При добавлении нескольких записей стоит учитывать ограничения на транзакции и возможность отката при ошибках.
После выполнения запроса рекомендуется проверять результат с помощью SELECT или встроенных функций системы для подтверждения успешного добавления. Это помогает вовремя выявлять ошибки и корректировать данные без потери информации.
Соблюдение точного порядка действий и правильного форматирования данных снижает вероятность появления дублирующихся записей и нарушений целостности базы, обеспечивая стабильную работу приложения и точность отчетности.
Выбор подходящей СУБД для вашего проекта
При выборе системы управления базами данных важно учитывать тип данных и нагрузку на сервер. Для хранения структурированных таблиц с множеством связей оптимальны реляционные СУБД, такие как MySQL или PostgreSQL. Они поддерживают транзакции и обеспечивают контроль целостности данных через ключи и индексы.
Если проект предполагает работу с большими объемами неструктурированных данных, логичнее использовать NoSQL-решения, например MongoDB или Cassandra. Эти системы лучше масштабируются горизонтально и позволяют быстро добавлять записи без строгой схемы.
Следует учитывать требования к скорости чтения и записи. Для приложений с высокой частотой добавления данных имеет значение поддержка батчевых операций и индексов. PostgreSQL предоставляет расширенные возможности индексации, включая GiST и GIN, что ускоряет поиск по сложным структурам.
Совместимость с языками программирования и наличие готовых библиотек также критична. Для Python часто используют SQLAlchemy с реляционными СУБД, а для Node.js удобны драйверы MongoDB и Redis. Этот аспект упрощает интеграцию с существующей логикой приложения.
Необходимо оценить требования к резервному копированию и восстановлению. Многие реляционные СУБД поддерживают point-in-time recovery, а NoSQL-системы предлагают репликацию и шардирование. Выбор зависит от объема данных и допустимого времени простоя при сбоях.
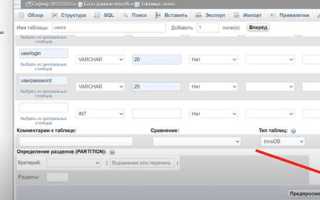
Создание таблицы и определение полей для данных
При создании таблицы важно заранее определить типы данных для каждого столбца. Например, для числовых значений используйте INT или DECIMAL, для текста – VARCHAR с указанием максимальной длины, а для дат – DATE или TIMESTAMP. Это снижает риск ошибок при добавлении записей.
Каждая таблица должна содержать первичный ключ, уникально идентифицирующий запись. Обычно используется поле id с автогенерацией значения через AUTO_INCREMENT или SERIAL в зависимости от СУБД.
При необходимости ограничения целостности данных добавляют NOT NULL для обязательных полей и UNIQUE для уникальных значений. Связи между таблицами реализуются через FOREIGN KEY, что обеспечивает согласованность при добавлении связанных записей.
Следует заранее планировать индексирование полей, по которым часто выполняются запросы. Индексы ускоряют поиск и выборку, но увеличивают время вставки и объем базы, поэтому важно выбрать только необходимые столбцы для индексации.
Перед созданием таблицы стоит протестировать структуру на тестовой базе с реальными типами данных. Это помогает выявить несоответствия форматов и оптимизировать поля до внесения постоянных изменений в рабочую систему.
Подготовка данных перед вставкой в таблицу
Перед добавлением записи важно привести данные к формату, который поддерживает таблица. Это включает проверку типов, длины и уникальности значений.
Основные этапы подготовки данных:
- Проверка типов данных: числовые значения должны быть целыми или с плавающей точкой, даты – в формате YYYY-MM-DD, строки – корректно экранированы.
- Удаление лишних пробелов и спецсимволов: это снижает вероятность ошибок при вставке и дублировании записей.
- Проверка уникальности: поля с ограничением UNIQUE не должны содержать повторяющиеся значения.
- Преобразование форматов: например, конвертация чисел с запятой в десятичный формат, замена локальных форматов даты на международные.
- Валидация обязательных полей: убедитесь, что все поля с NOT NULL заполнены корректными данными.
Для массовой вставки данных стоит использовать подготовленные массивы или CSV-файлы. Это позволяет заранее проверить корректность каждой строки и избежать ошибок при выполнении SQL-запроса.
Использование SQL-запроса INSERT для добавления записи
Для добавления записи в таблицу используется команда INSERT INTO. Она позволяет указать целевую таблицу, список столбцов и соответствующие значения.
Пример базового синтаксиса:
INSERT INTO имя_таблицы (столбец1, столбец2, столбец3) VALUES (значение1, значение2, значение3);
Если таблица содержит автогенерируемый PRIMARY KEY, его не нужно указывать в запросе. Значения для обязательных полей с NOT NULL должны быть предоставлены, иначе запрос завершится ошибкой.
Для вставки нескольких записей за один запрос используют синтаксис:
INSERT INTO имя_таблицы (столбец1, столбец2) VALUES (значение1, значение2), (значение3, значение4);
При работе с динамическими данными важно экранировать специальные символы и использовать подготовленные выражения (prepared statements) для предотвращения SQL-инъекций.
После выполнения запроса рекомендуется проверять результат с помощью SELECT или встроенных функций СУБД, чтобы убедиться, что запись добавлена корректно и соответствует ожиданиям.
Проверка успешного добавления записи в базу
После выполнения запроса INSERT необходимо убедиться, что запись действительно добавлена. В реляционных СУБД это можно сделать с помощью команды SELECT, указав уникальный идентификатор или другие ключевые поля.
Пример проверки:
SELECT * FROM имя_таблицы WHERE id = последний_вставленный_id;
Для массовой вставки данных рекомендуется использовать проверку количества затронутых строк. В большинстве СУБД результат выполнения запроса возвращает число добавленных записей, которое должно соответствовать ожидаемому.
Если используется автогенерируемый PRIMARY KEY, можно получить значение последней вставленной записи через функции LAST_INSERT_ID() в MySQL или RETURNING в PostgreSQL.
Дополнительно можно проверять целостность данных, сравнивая значения полей с исходными данными. Это особенно важно при автоматических преобразованиях формата или при вставке через скрипты.
Исправление ошибок при вставке данных
Ошибки при добавлении записей возникают из-за несоответствия типов данных, нарушения ограничений целостности или конфликтов уникальности. Для их исправления важно точно определить источник ошибки.
Частые причины и способы исправления можно структурировать в таблице:
| Причина ошибки | Признаки | Метод исправления |
|---|---|---|
| Несоответствие типов данных | Ошибка при выполнении запроса, сообщение о неверном формате | Проверить тип столбца, привести данные к нужному формату, экранировать строки |
| Нарушение ограничения NOT NULL | Сообщение о пропущенном обязательном поле | Заполнить все обязательные поля корректными значениями перед вставкой |
| Конфликт UNIQUE или PRIMARY KEY | Ошибка дублирования значения ключа | Использовать новое уникальное значение или проверить наличие записи перед вставкой |
| Ошибки формата даты или чисел | Невозможно преобразовать строку в дату/число | Проверить формат данных и привести к стандарту, принятому СУБД |
| Нарушение внешнего ключа (FOREIGN KEY) | Сообщение о несоответствии значения в связанной таблице | Убедиться, что вставляемое значение существует в родительской таблице |
После исправления ошибок рекомендуется повторно выполнить запрос и проверить результат через SELECT или функции СУБД для подтверждения корректного добавления записи.
Автоматизация добавления нескольких записей через скрипт
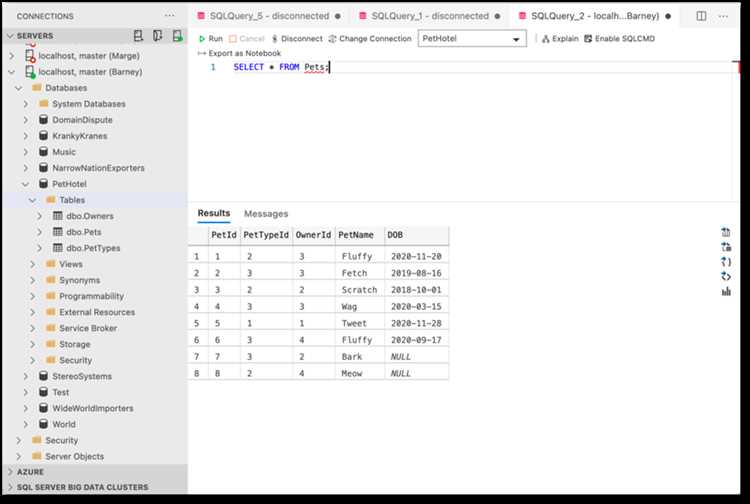
Для массовой вставки данных удобнее использовать скрипты на языке программирования, совместимом с выбранной СУБД. Это позволяет обрабатывать данные динамически и снижает вероятность ошибок.
Основные подходы к автоматизации:
- Использование циклов для генерации SQL-запросов: можно формировать несколько INSERT команд на основе массива или CSV-файла.
- Подготовленные выражения (prepared statements): повышают безопасность, предотвращают SQL-инъекции и ускоряют выполнение повторяющихся запросов.
- Пакетная вставка (batch insert): позволяет вставлять сразу несколько записей за один запрос, уменьшая нагрузку на сервер и повышая скорость обработки.
- Проверка данных перед вставкой: скрипт может автоматически валидировать типы, уникальность и обязательные поля.
- Обработка ошибок и логирование: при сбое отдельных записей скрипт сохраняет информацию об ошибках для последующего анализа.
Пример логики скрипта:
- Загрузить данные из файла или массива.
- Проверить формат и обязательные поля каждой записи.
- Сформировать подготовленный SQL-запрос для каждой записи или пакетно.
- Выполнить вставку и зафиксировать транзакцию.
- Проверить результат через SELECT или функции СУБД.
Использование автоматизации особенно полезно при обновлении больших баз данных или интеграции с внешними источниками данных, где ручная вставка занимает слишком много времени.
Вопрос-ответ:
Какие типы данных нужно учитывать при добавлении записи в таблицу?
При добавлении записи важно точно определить тип данных каждого столбца. Для чисел используют INT или DECIMAL, для текста — VARCHAR с указанием длины, для даты и времени — DATE или TIMESTAMP. Неправильный тип данных приведет к ошибке при вставке или искажению информации.
Как правильно использовать команду INSERT для добавления нескольких записей?
Чтобы добавить сразу несколько записей, используют синтаксис вида: INSERT INTO таблица (столбец1, столбец2) VALUES (значение1, значение2), (значение3, значение4); Такой подход сокращает количество запросов и уменьшает нагрузку на сервер. Важно проверять соответствие типов данных и уникальность ключей перед вставкой.
Какие методы проверки успешного добавления записи существуют?
После выполнения запроса INSERT можно проверить добавленную запись через SELECT, указав уникальный идентификатор или другие ключевые поля. В MySQL доступна функция LAST_INSERT_ID() для получения ID последней вставленной записи. Также важно сверять значения полей с исходными данными для подтверждения корректности.
Что делать при возникновении ошибок при вставке данных?
Ошибки чаще всего возникают из-за несоответствия типов данных, нарушения ограничений NOT NULL или UNIQUE, конфликтов внешних ключей. Для исправления проверяют типы и форматы данных, заполняют обязательные поля, исправляют дублирующиеся значения и проверяют наличие родительских записей при использовании FOREIGN KEY. После исправления запрос повторяют и проверяют результат.