Содержание статьи

В PostgreSQL таблица pg_toast используется для хранения больших значений данных, которые не помещаются в стандартную страницу таблицы размером 8 КБ. Любое поле типа TEXT, BYTEA или массив, превышающее этот размер, автоматически сохраняется в отдельной toast-таблице, связанной с основной таблицей.
Каждая основная таблица с большими значениями имеет свою уникальную pg_toast, где данные разбиваются на чанки по 2 КБ. Это позволяет базе данных сохранять компактность основной таблицы и ускоряет операции чтения и записи, так как большие значения обрабатываются отдельно.
Pg_toast не отображается напрямую в списке пользовательских таблиц, но доступ к ней возможен через системные каталоги PostgreSQL. Анализ и очистка toast-таблиц помогает управлять расходом дискового пространства и предотвращает накопление «мертвых» данных после частых обновлений.
Для мониторинга содержимого toast-таблиц применяются SQL-запросы с соединением с основной таблицей через системные идентификаторы. Рекомендовано регулярно проверять размер toast-данных и при необходимости запускать VACUUM или ANALYZE для поддержания производительности.
Назначение и роль таблицы pg_toast в хранении данных
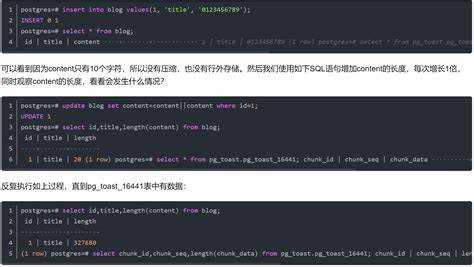
Таблица pg_toast служит для хранения больших объектов, которые не помещаются в стандартную страницу таблицы PostgreSQL размером 8 КБ. Любое поле типа TEXT, BYTEA или массив, превышающее этот размер, автоматически разделяется на части и сохраняется в toast-таблице.
Каждая основная таблица с большими значениями имеет собственную pg_toast, где данные разбиваются на чанки по 2 КБ. Это снижает нагрузку на основную таблицу, ускоряет вставку и обновление строк, а также уменьшает фрагментацию страниц.
Pg_toast позволяет поддерживать целостность данных: каждый большой объект связан с конкретной записью основной таблицы через идентификаторы chunk_id и chunk_seq. Это обеспечивает корректное восстановление и чтение данных при любых операциях.
Для управления объемом toast-данных рекомендуется периодически запускать команды VACUUM и ANALYZE на основной таблице. Это очищает устаревшие или удаленные чанки, предотвращает рост дискового пространства и улучшает производительность выборок больших объектов.
Как PostgreSQL распределяет большие значения в pg_toast

Когда значение поля превышает 2 КБ, PostgreSQL автоматически перемещает его в соответствующую toast-таблицу. Данные разбиваются на чанки фиксированного размера 2 КБ, каждый из которых хранится как отдельная запись. Это позволяет основной таблице оставаться компактной и ускоряет операции доступа.
Связь между основной записью и чанками обеспечивается уникальным идентификатором chunk_id и порядком chunk_seq. При чтении PostgreSQL собирает все чанки в правильной последовательности для восстановления полного значения.
Пример распределения данных можно представить в виде таблицы:
| Основная таблица | Поле | Размер значения | Чанк | Ссылка в pg_toast |
|---|---|---|---|---|
| users | profile_photo | 6 КБ | 1 | pg_toast_16384 |
| users | profile_photo | 6 КБ | 2 | pg_toast_16384 |
| users | profile_photo | 6 КБ | 3 | pg_toast_16384 |
Для эффективного хранения рекомендуется ограничивать частые обновления больших полей, так как каждая модификация создает новые чанки. Регулярное выполнение VACUUM помогает удалять устаревшие чанки и поддерживать размер toast-таблицы под контролем.
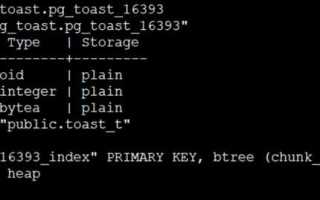
Структура и ключевые поля таблицы pg_toast
Таблица pg_toast хранит большие значения данных в виде отдельных чанков. Каждая запись соответствует части исходного значения и имеет несколько ключевых полей для идентификации и восстановления данных.
- chunk_id – уникальный идентификатор связанной записи основной таблицы.
- chunk_seq – порядковый номер чанка, указывающий последовательность для сборки полного значения.
- chunk_data – собственно данные, разделённые на блоки фиксированного размера (по 2 КБ).
Структура таблицы позволяет PostgreSQL быстро находить и собирать большие значения без загрузки всей основной записи. Для анализа и оптимизации размера toast-таблицы полезно:
- Проверять количество чанков для каждого значения с помощью SQL-запросов к pg_toast.
- Использовать VACUUM для удаления устаревших или удалённых чанков.
- Регулярно запускать ANALYZE для обновления статистики, чтобы планировщик запросов учитывал реальный размер данных.
Методы просмотра и анализа содержимого pg_toast
Прямой доступ к таблицам pg_toast осуществляется через системные каталоги PostgreSQL. Каждая toast-таблица имеет имя вида pg_toast_OID, где OID соответствует основной таблице.
Для просмотра содержимого можно использовать SQL-запросы:
- Определение соответствующей toast-таблицы:
- Просмотр чанков больших значений:
- Подсчёт числа чанков для конкретной записи:
SELECT reltoastrelid FROM pg_class WHERE relname = ‘имя_таблицы’;
SELECT * FROM pg_toast.pg_toast_16384 LIMIT 10;
SELECT COUNT(*) FROM pg_toast.pg_toast_16384 WHERE chunk_id = 12345;
Для анализа объема и распределения данных применяют команды pg_total_relation_size и pg_size_pretty:
SELECT pg_size_pretty(pg_total_relation_size(‘pg_toast.pg_toast_16384’));
Рекомендуется периодически проверять размеры toast-таблиц и количество чанков, особенно после массовых обновлений, чтобы своевременно запускать VACUUM и освобождать дисковое пространство.
Влияние pg_toast на производительность запросов и обновлений

Pg_toast позволяет хранить большие значения отдельно от основной таблицы, что уменьшает размер страниц основной таблицы и ускоряет обычные SELECT-запросы. Однако чтение больших полей требует сборки чанков, что увеличивает нагрузку на I/O и память при выборках.
При обновлении полей с большими значениями PostgreSQL создает новые чанки вместо перезаписи существующих. Частые изменения крупных данных приводят к росту toast-таблицы и увеличению числа «мертвых» записей, что замедляет VACUUM и последующие запросы.
Для снижения нагрузки рекомендуется:
- Разделять большие поля на отдельные таблицы, если они редко используются в выборках.
- Ограничивать размер текстовых или бинарных полей при проектировании схемы.
- Регулярно запускать VACUUM и ANALYZE на основной и toast-таблицах для очистки устаревших чанков и обновления статистики.
- Использовать выборочные запросы с указанием нужных полей вместо SELECT *, чтобы избегать ненужной сборки больших значений.
Удаление и очистка данных в pg_toast без повреждения основной таблицы
Данные в таблице pg_toast связаны с основной таблицей через идентификатор chunk_id. Прямое удаление записей из toast-таблицы может нарушить целостность, поэтому рекомендуется использовать встроенные механизмы PostgreSQL.
Основные методы очистки:
- Запуск VACUUM на основной таблице – удаляет устаревшие или удаленные чанки из toast-таблицы автоматически.
- Использование VACUUM FULL при значительном росте toast-данных – полностью перестраивает таблицу и освобождает дисковое пространство.
- Команда ANALYZE – обновляет статистику, чтобы планировщик запросов учитывал актуальные размеры toast-таблицы и избегал избыточной нагрузки.
Рекомендуется планировать очистку toast-таблиц после массовых обновлений или удаления больших полей, чтобы предотвратить накопление «мертвых» данных и снизить объем дискового хранения без воздействия на основную таблицу.
Вопрос-ответ:
Что такое таблица pg_toast в PostgreSQL и для чего она нужна?
Таблица pg_toast хранит большие значения данных, которые не помещаются в стандартную страницу основной таблицы размером 8 КБ. Это могут быть поля типов TEXT, BYTEA или массивы. PostgreSQL автоматически переносит такие значения в toast-таблицу, разбивая их на чанки по 2 КБ для сохранения целостности и ускорения работы с основной таблицей.
Как PostgreSQL разделяет большие значения между основной таблицей и pg_toast?
При вставке или обновлении большого значения PostgreSQL создаёт отдельные записи в соответствующей toast-таблице. Каждое значение делится на чанки фиксированного размера 2 КБ. В основной таблице хранится ссылка на набор чанков, а при выборке данные собираются в правильной последовательности по идентификатору chunk_id и порядковому номеру chunk_seq.
Можно ли напрямую изменять данные в pg_toast без риска для основной таблицы?
Прямое редактирование или удаление данных в pg_toast опасно, так как нарушает связь с основной таблицей. Очистку и удаление устаревших чанков следует выполнять через команды VACUUM и ANALYZE на основной таблице. Они безопасно удаляют «мертвые» записи и обновляют статистику, не затрагивая целостность данных.
Как узнать размер и количество данных в pg_toast для конкретной таблицы?
Для оценки объема toast-данных используют системные функции PostgreSQL. Например, pg_total_relation_size(‘pg_toast.pg_toast_OID’) показывает общий размер toast-таблицы, а SELECT COUNT(*) FROM pg_toast.pg_toast_OID WHERE chunk_id = X; позволяет узнать количество чанков для конкретной записи. Это помогает контролировать дисковое пространство после массовых обновлений.
Как pg_toast влияет на производительность выборок и обновлений?
Разделение больших значений на чанки уменьшает нагрузку на основную таблицу и ускоряет обычные SELECT-запросы. Однако при выборке больших полей требуется сборка чанков, что увеличивает I/O и потребление памяти. Частые обновления создают новые чанки, увеличивая размер toast-таблицы. Регулярные VACUUM и ANALYZE помогают поддерживать производительность.