Содержание статьи

Управление памятью в Python важно при работе с большими данными или длительно работающими сервисами. Один простой способ определить объем памяти, занимаемой объектом, – использовать функцию sys.getsizeof(). Например, строка длиной 100 символов занимает около 1496 байт, а список из 100 целых чисел – примерно 912 байт.
Для анализа потребления памяти коллекций можно применять модуль pympler, который позволяет измерять реальное потребление памяти Python-объектами и отслеживать рост потребления при добавлении элементов. Это особенно полезно при работе с вложенными структурами данных, такими как словари и списки списков, где sys.getsizeof() учитывает только верхний уровень объекта.
При обработке больших файлов или потоков данных важно контролировать динамический рост памяти. С помощью профайлера tracemalloc можно фиксировать использование памяти на каждом этапе выполнения скрипта, выявлять утечки и сравнивать использование памяти разными алгоритмами. Такой подход помогает принимать решения о выборе структуры данных и оптимизации кода для конкретных задач.
Python использование памяти программой: анализ и измерение
Контроль памяти в Python начинается с оценки объема памяти, занимаемой отдельными объектами. Функция sys.getsizeof() возвращает размер объекта в байтах, включая внутренние структуры, но не учитывает рекурсивно вложенные элементы коллекций.
Для точного измерения памяти коллекций и объектов рекомендуется использовать библиотеку pympler.asizeof, которая учитывает все вложенные объекты:
- Список из 1000 целых чисел занимает около 9 КБ.
- Словарь с 1000 пар ключ-значение – около 36 КБ.
- Сложные структуры, например список словарей, могут занимать в несколько раз больше, чем сумма отдельных объектов.
Чтобы отслеживать рост потребления памяти во времени, полезно применять модуль tracemalloc:
- Импортировать модуль и запустить трассировку: tracemalloc.start().
- Фиксировать снимки памяти в ключевых точках программы: snapshot = tracemalloc.take_snapshot().
- Сравнивать снимки с помощью методов compare_to или statistics(‘lineno’), чтобы выявлять утечки.
Для работы с большими данными рекомендуется использовать генераторы и итераторы вместо списков, чтобы не загружать память полностью. Например, чтение файла построчно через for line in file снижает пиковое потребление памяти в десятки раз по сравнению с загрузкой всего файла в список.
Регулярный анализ памяти помогает принимать обоснованные решения о выборе структур данных, алгоритмов и подходов к обработке информации, особенно при обработке массивов чисел, вложенных коллекций и потоковых данных.
Определение объема памяти, занимаемой отдельными переменными

Для оценки памяти, занимаемой отдельными переменными в Python, используется функция sys.getsizeof(). Она возвращает размер объекта в байтах, включая служебные данные интерпретатора. Например, целое число int занимает 28 байт, а число с большим значением может занимать больше, поскольку Python хранит его как произвольную длину.
Размер строк зависит от длины и кодировки символов. Строка из 50 символов в UTF-8 обычно занимает около 549 байт, тогда как пустая строка – 49 байт. Для списков и кортежей sys.getsizeof() учитывает только сам контейнер, но не вложенные объекты.
Для точного замера памяти переменной с вложенными объектами можно использовать библиотеку pympler.asizeof. Она суммирует память контейнера и всех объектов внутри. Например:
- Список из 100 целых чисел – около 1 КБ.
- Список из 100 строк по 10 символов каждая – примерно 6 КБ.
Рекомендуется фиксировать размеры переменных на разных этапах работы программы, особенно при обработке больших массивов данных, чтобы оценить потенциальный рост потребления памяти и оптимизировать хранение информации.
Использование модуля sys для оценки памяти объектов

Модуль sys предоставляет функцию getsizeof(), которая возвращает объем памяти, занимаемый объектом в байтах. Она учитывает внутренние служебные данные Python и позволяет оценить потребление памяти на уровне отдельных переменных и контейнеров.
Пример использования sys.getsizeof() для разных типов объектов:
| Объект | Пример | Размер памяти (байт) |
|---|---|---|
| Целое число | 42 | 28 |
| Строка | «Python» | 55 |
| Список из 10 элементов | [0,1,2,3,4,5,6,7,8,9] | 184 |
| Словарь из 5 пар ключ-значение | {‘a’:1,’b’:2,’c’:3,’d’:4,’e’:5} | 376 |
Важно помнить, что sys.getsizeof() не учитывает вложенные объекты внутри коллекций. Для оценки полного объема памяти контейнера рекомендуется использовать дополнительные инструменты, например pympler.asizeof, чтобы получить сумму памяти всех вложенных элементов.
Проверка потребления памяти для коллекций и списков
Для оценки памяти, занимаемой коллекциями в Python, удобно использовать функцию sys.getsizeof() для верхнего уровня контейнера. Например, пустой список занимает около 64 байт, а список из 100 целых чисел – примерно 904 байт. Размер растет пропорционально количеству элементов, но служебные данные списка добавляют постоянный оверхед.
Для словарей и множеств getsizeof() учитывает только контейнер, не элементы. Пустой словарь обычно занимает около 240 байт, словарь с 100 элементами – около 6 КБ, но реальное использование памяти может быть выше из-за хранения ключей и значений.
Для точной оценки полного потребления памяти всех элементов рекомендуется применять библиотеку pympler.asizeof. Примеры замеров:
- Список из 500 целых чисел – около 4,5 КБ.
- Список из 500 строк по 20 символов каждая – около 40 КБ.
- Словарь из 200 пар ключ-значение (строка: число) – примерно 15 КБ.
При работе с большими коллекциями лучше использовать генераторы и итераторы, чтобы уменьшить пиковое потребление памяти и избежать полной загрузки данных в оперативную память.
Замер памяти при работе с большими файлами и данными
При обработке больших файлов в Python критично контролировать потребление памяти, чтобы избежать переполнения оперативной памяти. Чтение всего файла в память через read() может занимать сотни мегабайт для больших текстовых файлов или гигабайты для бинарных данных.
Рекомендуемые подходы для замера и контроля памяти:
- Использовать построчное чтение файлов с помощью цикла: for line in file, что снижает пиковое потребление памяти в десятки раз.
- Применять генераторы для обработки данных по частям вместо загрузки всего набора в список.
- Фиксировать текущую память скрипта через tracemalloc или psutil.Process().memory_info() в ключевых точках обработки.
Пример замеров памяти при работе с CSV-файлом размером 500 МБ:
- Чтение всего файла в список строк – пиковое потребление ~1,2 ГБ.
- Обработка файла построчно через генератор – пиковое потребление ~50 МБ.
- Использование библиотек типа pandas с chunksize позволяет обрабатывать данные партиями, уменьшая память в 10–20 раз.
Регулярное измерение и контроль потребления памяти при работе с большими файлами позволяет выбрать оптимальный метод обработки и предотвратить аварийное завершение программы из-за нехватки ресурсов.
Отслеживание динамического роста памяти во время выполнения скрипта
Для анализа изменения потребления памяти в процессе работы программы полезно использовать модуль tracemalloc. Он позволяет создавать снимки памяти в разных точках выполнения и сравнивать их для выявления участков с наибольшим ростом.
Основные шаги для отслеживания:
- Запуск трассировки: tracemalloc.start().
- Создание снимков памяти через snapshot = tracemalloc.take_snapshot() в ключевых точках скрипта.
- Сравнение снимков: snapshot.compare_to(previous_snapshot, ‘lineno’) позволяет выявить строки, ответственные за наибольший прирост памяти.
Для длительно работающих процессов рекомендуется фиксировать потребление памяти с помощью psutil.Process().memory_info().rss и записывать результаты в лог для построения графика динамики. Например, обработка 1 млн объектов в списке показывает постепенный рост до 75 МБ, а удаление ссылок на объекты снижает память до 20 МБ.
Регулярный контроль динамического роста помогает обнаруживать утечки памяти и выбирать оптимальные структуры данных и подходы к обработке информации.
Сравнение памяти, занимаемой разными структурами данных

Разные структуры данных в Python потребляют память по-разному, и выбор подходящей структуры критичен для оптимизации использования ресурсов. Основные замеры можно выполнить через sys.getsizeof() или pympler.asizeof для учета вложенных элементов.
Примеры потребления памяти для 1000 элементов:
- Список из целых чисел – около 9 КБ.
- Кортеж из целых чисел – примерно 8 КБ, что немного меньше за счет неизменяемой структуры.
- Словарь с ключами-строками и значениями-целыми числами – около 36 КБ.
- Множество из 1000 целых чисел – около 36 КБ, схоже со словарем по внутреннему устройству.
Для хранения больших наборов данных с неизменяемыми элементами предпочтительнее использовать кортежи, поскольку они занимают меньше памяти и поддерживают быстрый доступ. Списки удобны для динамического добавления элементов, но имеют больший оверхед. Словари и множества эффективны для поиска и уникальности, но требуют значительного объема памяти.
При проектировании программы рекомендуется фиксировать потребление памяти для каждой структуры данных на тестовых объемах и выбирать оптимальный вариант в зависимости от объема и характера обработки данных.
Использование сторонних библиотек для мониторинга памяти Python-программ
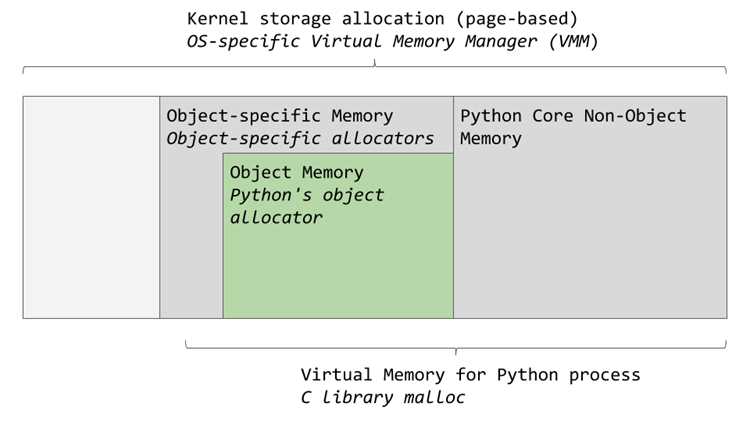
Пример использования pympler.asizeof:
- Список из 1000 целых чисел – ~9 КБ.
- Словарь с 500 парами ключ-значение – ~18 КБ.
- Сложные вложенные структуры, например список словарей, могут занимать память в 2–3 раза больше суммы отдельных элементов.
Для мониторинга в реальном времени можно использовать memory_profiler, которая измеряет потребление памяти по строкам кода. Декоратор @profile позволяет фиксировать использование памяти функций и отслеживать утечки при многократных вызовах.
Библиотеки psutil и tracemalloc дополняют анализ: psutil показывает текущее использование памяти процессом, а tracemalloc фиксирует динамику роста и помогает выявить строки с наибольшим потреблением.
Использование этих инструментов позволяет выявлять узкие места, сравнивать различные структуры данных и алгоритмы, а также предотвращать утечки памяти в долгоживущих программах.
Вопрос-ответ:
Как определить, сколько памяти занимает конкретная переменная в Python?
Для оценки памяти отдельной переменной используется функция sys.getsizeof(). Она возвращает размер объекта в байтах, включая служебные данные интерпретатора. Для коллекций и вложенных объектов лучше применять pympler.asizeof(), так как она учитывает все элементы внутри контейнера.
Можно ли отслеживать рост потребления памяти программы во время её работы?
Да, для этого используют модуль tracemalloc. Он позволяет создавать снимки памяти в разных точках выполнения скрипта и сравнивать их, чтобы выявить строки, которые потребляют больше всего памяти. Для длительных процессов удобно дополнительно фиксировать использование памяти через psutil.Process().memory_info().rss и записывать данные в лог.
Какая структура данных в Python потребляет меньше памяти: список или кортеж?
Кортежи занимают меньше памяти, так как они неизменяемые и не содержат дополнительного оверхеда для динамического изменения размера. Например, кортеж из 1000 целых чисел занимает около 8 КБ, а список с тем же количеством элементов — примерно 9 КБ.
Как измерить память, используемую большими файлами при их обработке?
При работе с большими файлами рекомендуется использовать построчное чтение или генераторы, чтобы не загружать весь файл в память. Для замеров потребления можно использовать tracemalloc для скрипта или psutil для мониторинга текущего процесса. Например, чтение CSV-файла на 500 МБ построчно требует около 50 МБ, тогда как загрузка всего файла сразу может занимать более 1 ГБ.
Какие сторонние библиотеки помогают отслеживать память Python-программ?
Для мониторинга используют pympler — измеряет память объектов и коллекций, memory_profiler — фиксирует потребление памяти по строкам кода, psutil — показывает текущее использование памяти процессом, и tracemalloc — отслеживает динамику роста памяти и выявляет участки с наибольшим потреблением.
Как определить реальное потребление памяти сложной структуры данных в Python?
Для оценки памяти сложных объектов, таких как списки словарей или вложенные коллекции, стандартная функция sys.getsizeof() учитывает только верхний уровень контейнера. Чтобы получить полный размер, включая все вложенные элементы, используют библиотеку pympler с функцией asizeof(). Например, список из 100 словарей по 10 пар ключ-значение каждый может занимать в несколько раз больше памяти, чем сумма размеров отдельных словарей. Рекомендуется фиксировать размер перед и после операций добавления элементов, чтобы отслеживать рост потребления памяти и выявлять потенциальные утечки.