Содержание статьи

Двоичный код состоит из последовательностей нулей и единиц, каждая из которых представляет бит информации. Для точного перевода данных важно учитывать длину и структуру кода: текстовые символы обычно кодируются по 8 бит, числовые значения могут занимать 16 или 32 бита.
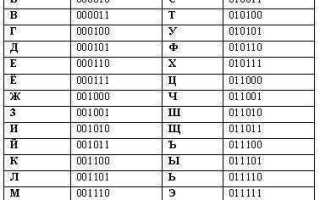
Для расшифровки текста используется таблица ASCII, где каждая 8-битная комбинация соответствует конкретному символу. При работе с числами применяется формула перевода в десятичную систему: сумма значений битов, умноженных на степени двойки. Эти методы позволяют определить точное значение данных без ошибок.
При работе с файлами или изображениями важно учитывать заголовки и структуру формата. Неправильная группировка битов приводит к некорректной интерпретации. Использование скриптов на Python или онлайн-конвертеров ускоряет процесс и позволяет проверять результаты на каждом этапе.
Регулярная проверка расшифрованного кода на соответствие исходным данным помогает выявлять ошибки при вводе или передаче информации. Для анализа сетевых пакетов или бинарных файлов рекомендуется фиксировать группы битов и использовать проверочные таблицы, чтобы сохранить точность интерпретации.
Понимание структуры двоичного кода
Двоичный код формируется последовательностью битов, где каждая единица или ноль имеет определённое значение в зависимости от позиции. Старший бит определяет наибольшую степень двойки в наборе, младший – наименьшую. Например, последовательность 1011 в десятичной системе равна 11, так как 1×2³ + 0×2² + 1×2¹ + 1×2⁰ = 8 + 0 + 2 + 1.
Для текста двоичный код обычно группируется по 8 бит (1 байт), что соответствует одному символу в таблице ASCII. Числовые данные могут занимать 16, 32 или 64 бита в зависимости от формата и точности. Правильное определение длины последовательностей критично для корректной расшифровки.
В бинарных файлах и изображениях структура усложняется за счёт заголовков и метаданных. Первые биты могут содержать информацию о формате, размере или цветовой палитре. Игнорирование этих элементов приводит к неверной интерпретации данных.
Для анализа структуры рекомендуется фиксировать последовательности битов и создавать таблицы соответствия. Скрипты на Python или специализированные утилиты позволяют визуализировать группы битов и проверять корректность перевода в текст или числа.
Преобразование двоичных чисел в десятичные
Для перевода двоичного числа в десятичное каждая позиция бита умножается на степень двойки в зависимости от его места. Старший бит соответствует наибольшей степени, младший – 2⁰. Результаты суммируются, чтобы получить десятичное значение.
Пошаговый метод преобразования:
- Запишите двоичное число справа налево, присваивая каждой позиции степень 2 начиная с 0.
- Умножьте значение каждого бита (0 или 1) на соответствующую степень 2.
- Сложите все полученные произведения.
- Результат суммы – десятичное значение исходного двоичного числа.
Пример: двоичное число 1101:
- 1×2³ = 8
- 1×2² = 4
- 0×2¹ = 0
- 1×2⁰ = 1
- Сумма: 8 + 4 + 0 + 1 = 13
Для длинных последовательностей рекомендуется использовать таблицы степеней двойки или автоматизированные инструменты на Python с функцией int(«1101», 2), которая сразу возвращает десятичное значение.
При работе с последовательностями битов, превышающими 32 бита, важно проверять переполнение и корректное хранение чисел, особенно в программировании и при обработке бинарных файлов.
Использование ASCII для перевода текста из двоичного кода
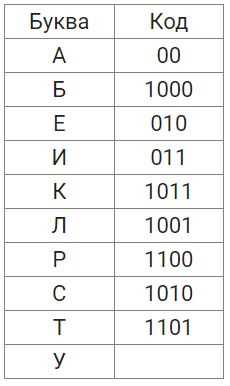
ASCII представляет собой стандарт, где каждый символ текста кодируется числом от 0 до 127. Для перевода двоичного кода в текст необходимо разбить поток бит на блоки по 8 бит, так как 1 байт соответствует одному символу.
Алгоритм перевода:
- Разделите последовательность бит на группы по 8.
- Преобразуйте каждую группу в десятичное число через суммирование степеней двойки.
- Используйте таблицу ASCII, чтобы определить символ, соответствующий числу.
- Объедините символы в текстовую строку.
Пример: последовательность 01100001 01100010:
- 01100001 → 97 → символ a
- 01100010 → 98 → символ b
- Результат: ab
Для больших объёмов текста рекомендуется использовать Python с функцией chr(int(биты, 2)). Это позволяет автоматизировать процесс и избежать ошибок при ручном расчёте.
При работе с расширенными наборами символов, например для кириллицы, следует учитывать кодировку UTF-8, где один символ может занимать 16 или 24 бита, что требует корректного разбиения двоичного потока на байты.
Расшифровка двоичного кода в шестнадцатеричный формат
Шестнадцатеричный формат представляет данные в виде цифр от 0 до 9 и букв A–F, где каждая цифра кодирует 4 бита. Для перевода двоичного кода в шестнадцатеричный необходимо разбить последовательность бит на группы по 4.
Методика преобразования:
- Разделите двоичный поток на блоки по 4 бита справа налево.
- Преобразуйте каждую группу в десятичное число.
- Соответствующее число от 0 до 9 или буква от A до F – шестнадцатеричный символ.
- Соедините все символы для получения шестнадцатеричной строки.
Пример: двоичная последовательность 11010111:
- 1101 → 13 → D
- 0111 → 7 → 7
- Результат: D7
Для длинных кодов удобно использовать функции на Python, например hex(int(«11010111», 2)), которые автоматически выполняют преобразование и возвращают корректное шестнадцатеричное значение.
Расшифровка в шестнадцатеричный формат полезна при анализе памяти, сетевых пакетов и бинарных файлов, так как сокращает длину записи и упрощает визуальное сопоставление данных.
Применение онлайн-инструментов для перевода двоичного кода
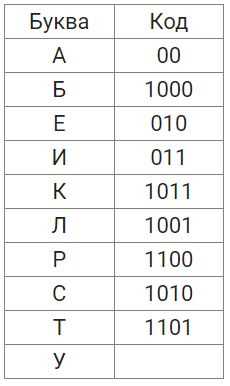
Онлайн-конвертеры позволяют мгновенно преобразовывать двоичный код в текст, десятичные и шестнадцатеричные значения без ручного расчёта. Они автоматически группируют биты по 8 или 4 и учитывают выбранную кодировку.
Рекомендации при работе с онлайн-инструментами:
- Используйте сервисы с поддержкой ASCII и UTF-8, чтобы корректно отображать текст на любых языках.
- Следите за форматом ввода: некоторые конвертеры требуют пробелы между байтами или определённое разделение групп бит.
- Проверяйте результаты с помощью встроенных функций визуализации или сравнения, чтобы убедиться в точности перевода.
- Для больших файлов применяйте инструменты с поддержкой загрузки документов и пакетной обработки, чтобы исключить ошибки при ручном копировании длинных последовательностей.
Онлайн-инструменты ускоряют анализ бинарных данных, сетевых пакетов и тестирование скриптов, облегчая проверку и визуализацию двоичного кода.
Обработка двоичного кода в программировании на Python
Python предоставляет инструменты для работы с двоичными данными, включая встроенные функции и типы данных. Двоичные строки обозначаются префиксом b, например b’10101010′, что позволяет оперировать битами напрямую.
Основные методы обработки:
- Преобразование в десятичное число: int(‘1101’, 2) возвращает 13.
- Перевод в шестнадцатеричный формат: hex(int(‘11010111’, 2)) выдаёт ‘0xd7’.
- Конвертация в символы по ASCII: chr(int(‘01001000’, 2)) даёт ‘H’.
- Обработка длинных потоков: Используйте списковые включения: ».join([chr(int(byte,2)) for byte in data.split()]) для последовательного перевода битов в текст.
- Чтение бинарных файлов: open(‘file’, ‘rb’) позволяет считывать данные по байтам и применять преобразования без потери информации.
Для анализа сетевых пакетов и больших файлов рекомендуется разбивать двоичный поток на блоки фиксированной длины, проверять правильность разбиения и использовать встроенные функции Python для контроля корректности каждого этапа преобразования.
Проверка корректности расшифровки двоичного текста
После преобразования двоичного кода в текст важно убедиться в точности расшифровки. Ошибки могут возникать из-за неправильного разбиения на байты, несоответствия кодировки или повреждения данных.
Методы проверки:
- Сравнение с исходными данными: Если доступен оригинальный текст, сверяйте результат побайтно с исходной последовательностью.
- Проверка кодировки: Убедитесь, что для текста используется корректная кодировка: ASCII для стандартных символов или UTF-8 для расширенных наборов.
- Контроль длины: Количество байтов после расшифровки должно совпадать с ожидаемым числом символов.
- Автоматическая проверка: Используйте скрипты на Python для повторного преобразования текста в двоичный код и сравнения с исходной последовательностью.
- Визуальная проверка: Для коротких текстов можно сверять символы вручную, фиксируя несовпадения.
Регулярная проверка корректности позволяет выявлять ошибки на ранних этапах и предотвращает потерю информации при обработке двоичных данных.
Чтение двоичного кода для файлов и изображений
Файлы и изображения хранятся в виде последовательностей битов, объединённых в байты. Для их расшифровки важно учитывать структуру формата: заголовки, метаданные и данные содержимого. Неправильное чтение битов может привести к повреждению файла или некорректной интерпретации изображения.
Стандартный подход к чтению двоичного кода:
- Использовать двоичный режим открытия файла, например open(‘file’, ‘rb’) в Python.
- Читать данные блоками по фиксированному числу байтов, соответствующему структуре файла.
- Сохранять информацию о заголовках, которые содержат ключевые параметры: размер, формат, цветовую палитру.
- Преобразовывать содержимое в нужный формат для анализа или визуализации.
Пример структуры файла в таблице:
| Блок | Описание | Размер |
|---|---|---|
| Заголовок | Содержит формат, размер и метаданные | 14–54 байта |
| Данные изображения | Пиксели, закодированные в RGB или другом формате | Зависит от разрешения |
| Дополнительные метаданные | EXIF, цветовой профиль, информация о камере | Варьируется |
Для анализа и восстановления файлов рекомендуется использовать специализированные библиотеки, которые разбивают двоичный поток на блоки, проверяют контрольные суммы и корректно интерпретируют данные изображения.
Вопрос-ответ:
Что такое двоичный код и как его правильно читать?
Двоичный код — это последовательность нулей и единиц, которая используется для хранения данных на компьютере. Каждый бит имеет значение 0 или 1, а их комбинации формируют числа, символы или команды. Для правильного чтения важно разбивать поток бит на группы: по 8 бит для текста (1 байт) и по 16, 32 или 64 бита для чисел. После этого последовательность переводят в десятичную систему или используют таблицы кодировок, например ASCII, чтобы получить символы.
Как перевести двоичный код в текст с помощью ASCII?
Для перевода текста двоичный поток делят на блоки по 8 бит. Каждая группа преобразуется в десятичное число через суммирование степеней двойки. После этого число сопоставляется с таблицей ASCII, где каждая цифра соответствует конкретному символу. Для автоматизации процесса можно использовать Python: chr(int(‘01001000’, 2)) даст символ ‘H’. Важно учитывать кодировку: стандартная ASCII подходит для английских символов, а UTF-8 — для кириллицы и специальных знаков.
Как проверить, правильно ли расшифрован двоичный текст?
После перевода битов в текст проверяют корректность с помощью нескольких методов. Сравнивают результат с исходными данными, проверяют кодировку и длину строк. Можно повторно преобразовать текст обратно в двоичный код и сверить последовательности. Для коротких текстов подходит визуальная проверка, а для больших — автоматические скрипты, которые фиксируют ошибки в группировке байтов или некорректные символы.
В каких случаях удобно использовать онлайн-конвертеры для двоичного кода?
Онлайн-конвертеры ускоряют перевод длинных последовательностей бит в текст, десятичные или шестнадцатеричные значения. Они автоматически группируют биты и поддерживают различные кодировки, включая ASCII и UTF-8. Рекомендуется проверять формат ввода и использовать функции визуализации, чтобы убедиться, что результат совпадает с исходными данными. Конвертеры полезны при анализе сетевых пакетов, бинарных файлов или тестировании скриптов.
Как обрабатывать двоичный код для файлов и изображений?
Файлы и изображения хранятся в виде последовательностей байтов с заголовками и метаданными. Для чтения используют двоичный режим, например open(‘file’, ‘rb’) в Python, и обрабатывают данные блоками. Важно сохранять информацию о заголовках, чтобы корректно интерпретировать формат, размер и цветовую палитру. Для анализа больших файлов используют библиотеки, которые разбивают поток бит на блоки, проверяют контрольные суммы и извлекают содержимое без ошибок.
Как перевести длинную последовательность двоичных чисел в текст без ошибок?
Для длинных последовательностей важно сначала разбить поток бит на байты по 8 бит. Каждая группа преобразуется в десятичное число с помощью суммирования степеней двойки. Затем это число сопоставляется с таблицей ASCII или UTF-8 для получения символа. Для автоматизации используют скрипты на Python, которые обрабатывают весь поток и собирают текст, одновременно проверяя длину и правильность разбиения, чтобы избежать ошибок при ручном расчёте.
Можно ли расшифровать двоичный код для изображения и получить его пиксели?
Да, для изображений двоичный код делится на заголовки и блоки данных пикселей. Заголовки содержат информацию о формате файла, разрешении и цветовой палитре. Данные пикселей считываются в байтах и интерпретируются в соответствии с форматом, например RGB или RGBA. Для анализа используют двоичный режим открытия файлов и специализированные библиотеки, которые позволяют выделять блоки, проверять контрольные суммы и преобразовывать их в читаемую форму без искажений.