Содержание статьи

При работе с текстовыми файлами в Notepad многие пользователи сталкиваются с искажением русских букв: вместо привычных символов отображаются странные иероглифы или знаки вопроса. Основная причина этого – неправильная кодировка файла. Notepad по умолчанию использует ANSI для старых систем, что не поддерживает все символы кириллицы, особенно если файл создавался в другой программе или на другой операционной системе.
Для корректного отображения русских букв важно понимать разницу между основными кодировками: UTF-8, UTF-16 и ANSI. UTF-8 полностью поддерживает кириллицу и является стандартом для современных текстовых файлов, тогда как ANSI может корректно отображать только локальные символы, определяемые региональными настройками системы. При открытии UTF-8 файла в ANSI Notepad заменяет неподдерживаемые символы на «кракозябры».
Практическим решением является использование функции «Сохранить как» с выбором UTF-8 при создании или редактировании файлов. Также важно проверять исходную кодировку документов, особенно если они были скачаны из интернета или получены от коллег, использующих другие редакторы. Эти меры позволяют избежать потери данных и сохранить читаемость текста без необходимости использовать сторонние программы.
В статье подробно рассмотрены причины искажения русских букв в Notepad, способы проверки текущей кодировки файла и методы исправления проблем, которые возникают при работе с текстами на кириллице. Следуя конкретным инструкциям, можно гарантировать корректное отображение символов и минимизировать риск появления ошибок при обмене файлами между различными системами.
Почему в Notepad русские буквы отображаются некорректно
Notepad отображает текст на основе выбранной кодировки файла. Если файл создан в кодировке UTF-8, а Notepad пытается открыть его в ANSI, русские буквы заменяются на непонятные символы. ANSI поддерживает только ограниченный набор символов, соответствующий системной локали, что делает его несовместимым с полным набором кириллицы.
Еще одной причиной искажения может быть отсутствие BOM (Byte Order Mark) в UTF-8 файле. Notepad без BOM иногда неверно определяет кодировку и отображает текст как ANSI, что приводит к «кракозябрам». Файлы, созданные на Linux или в других редакторах, часто сохраняются без BOM, поэтому проблема особенно распространена при переносе документов между системами.
Исправить отображение можно через меню «Файл» → «Сохранить как», выбирая кодировку UTF-8 с BOM. Для уже открытых документов целесообразно использовать опцию «Открыть с кодировкой» и явно указать UTF-8. Это гарантирует корректное отображение всех русских символов независимо от исходной платформы или локальных настроек системы.
Кроме того, при частой работе с текстами на кириллице рекомендуется проверять кодировку сторонними редакторами, такими как Notepad++ или VS Code, которые точно распознают UTF-8 без BOM и позволяют быстро конвертировать файлы. Такой подход минимизирует риск искажения символов при совместной работе с разными источниками.
Как выбрать правильную кодировку при открытии файла
При открытии текстового файла в Notepad важно определить его исходную кодировку. Если файл был создан в UTF-8, но Notepad открывает его в ANSI, русские символы будут отображаться некорректно. Чтобы выбрать правильную кодировку, используйте команду «Файл» → «Открыть» и внизу окна укажите UTF-8 вместо стандартной ANSI.
Для файлов, которые могут быть в UTF-16 или с нестандартной локалью, рекомендуется проверять отображение через другой редактор с поддержкой кодировок, например Notepad++ или VS Code. Если русские буквы отображаются правильно там, нужно сохранить файл в UTF-8 с BOM, чтобы Notepad корректно распознал текст при открытии.
Важно учитывать, что Notepad автоматически определяет кодировку только для файлов с BOM. Файлы без BOM могут открываться в неправильной кодировке, даже если содержат UTF-8 символы. В таких случаях явный выбор кодировки при открытии гарантирует правильное отображение всех русских букв без искажений.
Регулярная проверка кодировки при открытии файлов и сохранении в UTF-8 с BOM снижает риск появления «кракозябр» и позволяет корректно работать с текстами на кириллице в Windows-среде.
Почему ANSI может ломать русские символы
Кодировка ANSI ограничена набором символов, определяемым локалью операционной системы. Для русской версии Windows это обычно Windows-1251, которая поддерживает кириллицу, но не полностью совместима с UTF-8 или UTF-16. Если файл создан в другой кодировке и открывается в ANSI, символы, отсутствующие в таблице Windows-1251, заменяются на непонятные знаки.
Основные причины искажения русских букв в ANSI:
- Файл создан в UTF-8 без BOM – Notepad определяет его как ANSI и заменяет нестандартные символы на «кракозябры».
- Файл содержит расширенные символы кириллицы или специальные знаки, которых нет в Windows-1251.
- Перенос файлов между разными системами с различными локальными настройками.
Рекомендации для работы с ANSI-файлами:
- Перед сохранением выбрать UTF-8 с BOM, чтобы Notepad корректно распознал символы.
- Использовать сторонние редакторы, такие как Notepad++ или VS Code, для конвертации кодировки без потери данных.
- При открытии подозрительных файлов явно указывать кодировку UTF-8, чтобы избежать автоматического использования ANSI.
Понимание ограничений ANSI позволяет предотвратить потерю русских символов и сохранить текст читаемым при работе с разными источниками и системами.
Разница между UTF-8 и UTF-16 для русских текстов
UTF-8 чаще используется для файлов, которые будут передаваться между разными системами, так как она совместима с ASCII и минимизирует размер файлов, содержащих преимущественно латиницу. UTF-16 занимает больше места для смешанных текстов, но гарантирует корректное отображение всех символов без необходимости BOM в некоторых редакторах.
Для Notepad важно учитывать, что UTF-8 без BOM может определяться как ANSI, что приведет к искажению русских букв. UTF-16 обычно распознается автоматически, но файлы в этой кодировке занимают больше памяти и могут быть несовместимы с программами, ожидающими UTF-8.
Практические рекомендации:
- Для документов, которые будут использоваться только в Windows и Notepad, безопаснее сохранять в UTF-8 с BOM.
- Если текст содержит большое количество символов из разных языков, UTF-16 обеспечивает корректное отображение всех символов без искажения.
- При обмене файлами через интернет или между разными операционными системами предпочтительнее использовать UTF-8, чтобы избежать проблем с совместимостью.
Как проверить текущую кодировку открытого файла
Notepad не отображает кодировку напрямую, поэтому определить текущую кодировку нужно косвенными методами. Если русские буквы отображаются корректно, скорее всего файл открыт в UTF-8 с BOM или в Windows-1251. Если символы искажены, используется некорректная кодировка, обычно ANSI.
Для точной проверки рекомендуется открыть файл в редакторах с поддержкой кодировок, таких как Notepad++ или VS Code. В Notepad++ текущая кодировка отображается в нижнем правом углу окна и через меню «Кодировка» можно видеть выбранный формат (UTF-8, UTF-8 с BOM, UTF-16 LE/BE, ANSI).
Если файл содержит смешанные символы и непонятные знаки, можно применить пошаговую проверку:
- Открыть файл в Notepad++.
- Выбрать меню «Кодировка» и переключаться между UTF-8, UTF-8 с BOM, UTF-16 и ANSI.
- Следить, при какой кодировке русские буквы отображаются правильно.
После выявления правильной кодировки файл следует сохранить в формате UTF-8 с BOM для совместимости с Notepad, чтобы избежать повторного искажения символов при открытии на других системах.
Почему файлы, созданные в других редакторах, могут отображаться криво
Файлы, созданные в сторонних редакторах, часто сохраняются в кодировках, которые Notepad не определяет автоматически. Например, Linux-редакторы и некоторые версии Visual Studio Code по умолчанию сохраняют UTF-8 без BOM, что приводит к искажению русских букв при открытии в стандартном Notepad.
Еще одной причиной является использование нестандартных символов или шрифтов, которые поддерживаются исходным редактором, но отсутствуют в таблице Windows-1251. При открытии таких файлов Notepad заменяет недопустимые символы на «кракозябры».
Рекомендации для корректного открытия файлов из других редакторов:
- Перед открытием проверить кодировку в исходном редакторе и при необходимости сохранить в UTF-8 с BOM.
- Использовать меню «Файл» → «Открыть с кодировкой» в Notepad и явно выбрать UTF-8 или UTF-16.
- При частой работе с текстами, созданными на разных системах, применять редакторы с поддержкой Unicode, такие как Notepad++ или VS Code, для предварительной проверки и конвертации кодировки.
Следование этим рекомендациям позволяет избежать искажений русских символов и гарантирует совместимость текстовых файлов между различными платформами и редакторами.
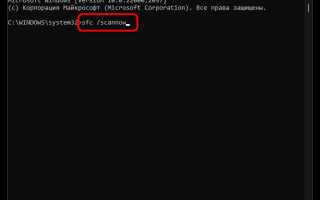
Исправление отображения русских букв через «Сохранить как»
Процесс исправления можно разделить на конкретные шаги:
| Шаг | Действие |
|---|---|
| 1 | Открыть файл с искаженными русскими буквами в Notepad. |
| 2 | В меню выбрать «Файл» → «Сохранить как». |
| 3 | В поле «Кодировка» указать UTF-8. |
| 4 | При необходимости задать новое имя файла и сохранить. |
| 5 | Закрыть файл и открыть заново, убедившись в правильном отображении русских букв. |
Сохранение файла в UTF-8 с BOM обеспечивает корректное отображение всех русских символов, предотвращает появление «кракозябр» при повторном открытии и совместимость с другими системами и редакторами.
Использование сторонних редакторов для корректной работы с кириллицей
Notepad ограничен в определении и выборе кодировок, что часто приводит к искажению русских букв. Для надежной работы с кириллицей целесообразно использовать сторонние текстовые редакторы с поддержкой Unicode, такие как Notepad++, VS Code или Sublime Text.
Преимущества использования сторонних редакторов:
- Автоматическое определение кодировки файла, включая UTF-8 без BOM и UTF-16.
- Возможность мгновенной конвертации файлов между ANSI, UTF-8 и UTF-16 без потери данных.
- Поддержка расширенных символов и смешанных языков, что предотвращает появление «кракозябр».
- Отображение текущей кодировки в интерфейсе и возможность изменить её для конкретного файла.
Практические рекомендации при работе с кириллицей:
- Перед открытием файла проверить его кодировку и при необходимости конвертировать в UTF-8 с BOM.
- Использовать меню кодировок редактора для выбора подходящей кодировки при сохранении и открытии файлов.
- При совместной работе с документами, созданными на разных системах, проверять текст на искажения и сохранять в универсальной кодировке.
Применение этих методов позволяет минимизировать ошибки отображения русских символов, повышает совместимость файлов и упрощает работу с текстами на кириллице на разных платформах.
Вопрос-ответ:
Почему при открытии текстового файла в Notepad русские буквы заменяются на знаки вопроса или квадраты?
Такое искажение символов возникает из-за несовпадения кодировки файла и той, которую использует Notepad. Например, если файл сохранён в UTF-8 без BOM, а Notepad пытается открыть его как ANSI, русские буквы не распознаются и заменяются на некорректные символы. Решение — сохранить файл с явным указанием UTF-8 с BOM или открыть его в редакторе, позволяющем выбрать кодировку вручную.
Как определить, в какой кодировке был создан файл с искаженными русскими буквами?
Notepad не показывает кодировку, поэтому нужно использовать редакторы с поддержкой Unicode, например Notepad++ или VS Code. В Notepad++ кодировка отображается в нижней части окна и в меню «Кодировка». Пробуя разные форматы — UTF-8, UTF-8 с BOM, UTF-16, ANSI — можно определить, какая кодировка позволяет корректно отображать все русские символы.
Почему файлы, созданные на Linux или в других текстовых редакторах, часто отображаются криво в Windows Notepad?
Причина заключается в различиях по умолчанию используемых кодировок. На Linux и некоторых редакторах Windows файлы сохраняются в UTF-8 без BOM. Notepad без BOM не распознаёт кодировку и открывает файл как ANSI, что приводит к искажению русских букв. Чтобы избежать этого, файл следует открыть в редакторе с выбором кодировки и сохранить в UTF-8 с BOM.
Можно ли исправить искажение русских букв в Notepad без использования сторонних программ?
Да, можно через функцию «Сохранить как». Открыв файл с искаженными символами, нужно выбрать кодировку UTF-8 в поле «Кодировка» и сохранить файл. После закрытия и повторного открытия русские буквы будут отображаться корректно. Этот метод работает для большинства текстов, не содержащих сложных специальных символов.
Почему ANSI не подходит для работы с текстами на русском языке?
ANSI ограничен набором символов, который зависит от локали системы. В русской Windows это Windows-1251, поддерживающая только базовую кириллицу. Если файл содержит расширенные символы или был создан в UTF-8, Notepad с ANSI заменяет неподдерживаемые буквы на «кракозябры». Для сохранения русских символов рекомендуется использовать UTF-8 с BOM или UTF-16.