Содержание статьи

Очередь в программировании представляет собой структуру данных, в которой элементы добавляются в конец и извлекаются из начала. Этот принцип известен как FIFO (first in, first out). Такая организация гарантирует, что задачи обрабатываются в том порядке, в котором они поступили, что критично для систем управления событиями и планировщиков задач.
Реализация очередей может выполняться с использованием массивов, связанных списков или специализированных контейнеров стандартных библиотек языков программирования. Массивы позволяют быстро обращаться к элементам по индексу, но вставка и удаление в начале требует сдвига остальных элементов. Связанные списки решают эту проблему, обеспечивая константное время добавления и удаления, но потребляют больше памяти из-за хранения ссылок.
Очереди с приоритетом расширяют стандартный FIFO-подход, позволяя обработке задач следовать не только порядку поступления, но и установленным критериям важности. Такие очереди широко применяются в системах планирования процессов, обработке сетевых пакетов и асинхронных задачах.
В многопоточном или распределенном окружении очереди становятся инструментом синхронизации. Применение блокирующих очередей позволяет корректно организовать обмен данными между потоками, предотвращая гонки и потерю сообщений. В веб-сервисах и микросервисной архитектуре очереди обеспечивают надежную доставку сообщений и контроль нагрузки, что снижает риск перегрузки компонентов.
Структура очереди и особенности хранения данных

Очередь организована как линейная структура, где каждый элемент хранит ссылку на следующий или индекс в массиве. В классическом FIFO-подходе первый добавленный элемент извлекается первым, а новые элементы добавляются в конец. Важно учитывать, что структура напрямую влияет на скорость операций вставки и удаления.
Очереди можно реализовать с помощью массивов или связанных списков. В массиве добавление в конец происходит за O(1), а удаление из начала требует сдвига всех элементов, что занимает O(n). В связанных списках удаление и добавление выполняются за O(1), но увеличивается расход памяти на хранение ссылок.
Для сравнения подходов удобно использовать таблицу:
| Тип реализации | Вставка в конец | Удаление из начала | Использование памяти |
|---|---|---|---|
| Массив | O(1) | O(n) | Минимальное, зависит от размера массива |
| Связанный список | O(1) | O(1) | Высокое, хранение ссылок на элементы |
Выбор структуры зависит от задач: для больших очередей с частыми вставками и удалениями предпочтительны связанные списки. Для очередей с фиксированным размером и редкими операциями удаления лучше использовать массивы. В системах с ограниченной памятью стоит учитывать накладные расходы на хранение ссылок при использовании связанных списков.
Очередь FIFO: как организовать последовательную обработку
Очередь FIFO (first in, first out) обеспечивает обработку элементов в порядке их поступления. Это важно для систем, где последовательность выполнения влияет на корректность работы, например, при обработке запросов к базе данных или отправке сообщений в сетевых приложениях.
Для реализации FIFO в программировании чаще используют массивы или связанные списки. В массиве добавление элемента выполняется в конец через индекс tail, а удаление из начала через индекс head. Для оптимизации используется кольцевой буфер, который предотвращает постоянный сдвиг элементов и снижает нагрузку на память.
В связанных списках FIFO добавление нового элемента производится в конец, а удаление – из начала списка. Такая реализация обеспечивает константное время операций вставки и извлечения, независимо от размера очереди.
При проектировании FIFO-очереди важно учитывать размер и частоту операций. Для высоконагруженных систем рекомендуют использовать структуры с предвыделенной памятью или кольцевые буферы, чтобы избежать частых перераспределений памяти. Для динамических задач, где размер очереди изменяется, лучше применять связанные списки с указателями на первый и последний элемент.
Очередь LIFO и её отличие от классической очереди
Очередь LIFO (last in, first out), или стек, извлекает последний добавленный элемент первым. В отличие от классической FIFO-очереди, где обработка идет по порядку поступления, LIFO позволяет работать с задачами в обратном порядке, что удобно для алгоритмов обхода графов, рекурсивных вычислений и отмены операций в приложениях.
Реализация LIFO обычно выполняется через массивы или связанные списки. В массиве добавление и удаление элемента происходит на одном конце, используя индекс top. В связанных списках все операции производятся с головой списка, что обеспечивает константное время операций без сдвига элементов.
При выборе между FIFO и LIFO важно учитывать тип задач. FIFO подходит для обработки потоков данных и очередей запросов, где важен порядок поступления. LIFO эффективен при построении алгоритмов, где требуется последний введенный элемент обработать первым, например, для управления стеком вызовов функций.
Для высоконагруженных приложений с динамическим изменением объема данных рекомендуют использовать связанные списки для LIFO, чтобы избежать перераспределений памяти и обеспечить стабильную производительность.
Реализация очереди с использованием массивов и списков
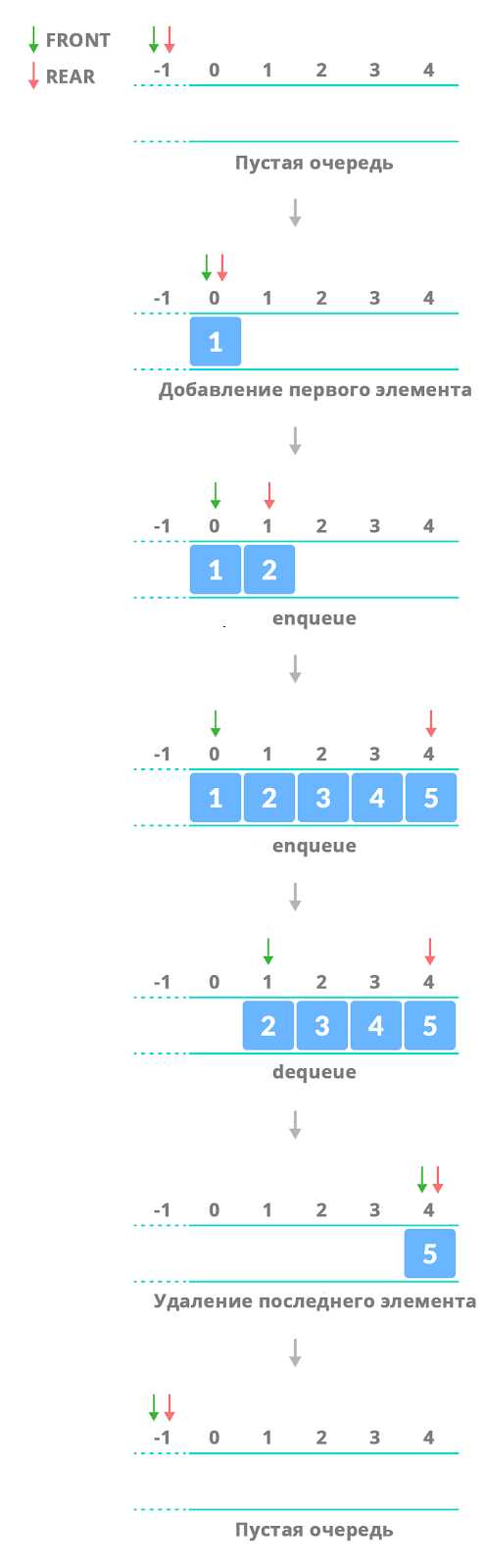
Очередь можно реализовать двумя основными способами: через массивы и через связанные списки. Каждый метод имеет свои особенности и ограничения, влияющие на скорость операций и использование памяти.
Реализация через массивы:
- Элементы хранятся в последовательных индексах.
- Добавление элемента в конец выполняется за O(1).
- Удаление элемента из начала массива требует сдвига всех последующих элементов, что занимает O(n).
- Оптимизация возможна с использованием кольцевого буфера, который позволяет повторно использовать освободившиеся индексы без сдвига.
Реализация через связанные списки:
- Каждый элемент содержит данные и ссылку на следующий.
- Добавление в конец и удаление из начала выполняются за O(1), независимо от размера очереди.
- Расход памяти выше, так как нужно хранить ссылки на элементы.
- Удобно использовать для динамических очередей с часто меняющимся объемом данных.
Рекомендации при выборе реализации:
- Для фиксированного размера очереди с редкими удалениями из начала подходит массив с кольцевым буфером.
- Для динамического объема данных и частых операций вставки/удаления лучше применять связанные списки.
- В системах с ограниченной памятью предпочтительны массивы, чтобы минимизировать накладные расходы на хранение ссылок.
Очереди с приоритетами: механизм сортировки задач
Очередь с приоритетом позволяет обработке элементов следовать не только порядку поступления, но и уровню важности. Каждый элемент получает числовой приоритет, и при извлечении выбирается элемент с наивысшим значением. Такая структура широко используется в системах планирования процессов, обработке событий и сетевых приложениях.
Для реализации применяют кучи (heap) или сбалансированные деревья:
- В двоичной куче добавление и извлечение элемента выполняется за O(log n). Элементы автоматически перестраиваются для сохранения порядка по приоритету.
- В сбалансированных деревьях поддерживается упорядоченность элементов, что позволяет эффективно искать и изменять приоритеты, но операции могут занимать больше памяти и времени на перестройку структуры.
При проектировании очереди с приоритетами важно учитывать:
- Максимальный объем данных и частоту изменений приоритетов.
- Необходимость обработки элементов с одинаковым приоритетом, что может потребовать сохранения внутреннего FIFO-порядка.
- Использование фиксированных массивов для ограниченных очередей или динамических структур для систем с непредсказуемым потоком задач.
Очереди с приоритетами особенно эффективны для планирования ресурсов и распределения нагрузки, где своевременная обработка критичных задач имеет решающее значение.
Асинхронная обработка и очереди в многопоточном окружении
В многопоточном программировании очереди используются для синхронизации обмена данными между потоками. Элементы добавляются в очередь одним потоком и извлекаются другим, что позволяет разделять работу и предотвращать блокировки общего ресурса.
Для безопасной работы применяют блокирующие очереди и неблокирующие структуры:
- Блокирующая очередь при попытке извлечения элемента из пустой структуры приостанавливает поток до появления новых данных.
- Неблокирующая очередь использует атомарные операции для добавления и удаления элементов, снижая риск гонок и повышая производительность в системах с высокой конкуренцией потоков.
При проектировании асинхронных систем важно учитывать размер очереди и частоту операций. Рекомендуется:
- Использовать кольцевые буферы для фиксированного объема данных, чтобы избежать перераспределения памяти.
- Для динамических потоков применять связанные списки, позволяющие масштабировать очередь без потерь производительности.
- Контролировать количество потоков-потребителей, чтобы не возникала чрезмерная конкуренция за элементы очереди.
Очереди в многопоточном окружении обеспечивают стабильную обработку задач, уменьшают вероятность блокировок и позволяют выстраивать предсказуемый порядок обработки данных в реальном времени.
Практическое использование очередей в веб-приложениях и сервисах
Очереди активно применяются для управления задачами и обмена сообщениями в веб-приложениях и микросервисных архитектурах. Они обеспечивают упорядоченную обработку запросов, распределение нагрузки и контроль последовательности действий.
Типичные сценарии использования:
- Отправка электронной почты и уведомлений в фоне без блокировки основного потока приложения.
- Обработка медленных операций, таких как генерация отчетов, транзакций или импорт больших данных.
- Оркестрация микросервисов, где сообщения передаются через очередь с гарантией доставки.
- Реализация механизма повторной попытки выполнения задач при сбоях или ошибках.
Рекомендации при применении очередей:
- Использовать брокеры сообщений (RabbitMQ, Kafka, Redis Streams) для надежной доставки и масштабирования.
- Настраивать размер очереди и количество потребителей в зависимости от пиковых нагрузок.
- Применять очереди с приоритетами для задач, критичных к времени обработки.
- Мониторить состояние очередей и внедрять механизмы контроля задержки и времени ожидания сообщений.
Использование очередей позволяет разгрузить веб-сервер, ускорить отклик пользователя и повысить надежность сервисов при работе с асинхронными задачами и высокими потоками данных.
Вопрос-ответ:
Что такое очередь в программировании и как она работает?
Очередь — это структура данных, в которой элементы добавляются в конец и извлекаются из начала. Основной принцип работы называется FIFO (first in, first out), что обеспечивает последовательную обработку задач. Очереди применяются для планирования операций, синхронизации потоков и управления задачами в приложениях.
В чем отличие очередей FIFO и LIFO?
Очередь FIFO извлекает элементы в порядке их добавления, что важно для соблюдения последовательности задач. LIFO, или стек, извлекает последний добавленный элемент первым. FIFO подходит для обработки потоков данных и очередей запросов, тогда как LIFO используют для рекурсивных операций, отката изменений или работы со стеком вызовов функций.
Какие способы реализации очередей существуют и какие у них особенности?
Очереди реализуют через массивы и связанные списки. В массиве добавление в конец выполняется быстро, а удаление из начала требует сдвига элементов, что замедляет работу при больших объемах данных. Связанный список обеспечивает константное время для добавления и удаления элементов, но использует больше памяти на хранение ссылок. Выбор зависит от объема данных и частоты операций.
Как работают очереди с приоритетами и когда их используют?
В очередях с приоритетами каждый элемент получает числовой приоритет, и извлекается элемент с наивысшим значением. Реализуют их через двоичные кучи или сбалансированные деревья. Используются для обработки критичных задач, распределения ресурсов и планирования процессов, когда порядок выполнения зависит не только от времени поступления, но и от важности задачи.
Зачем очереди нужны в многопоточном и веб-программировании?
В многопоточном окружении очереди позволяют безопасно обмениваться данными между потоками, предотвращая гонки и блокировки. В веб-приложениях и сервисах очереди обеспечивают асинхронную обработку задач: отправку уведомлений, выполнение фоновых операций, управление микросервисами. Это помогает разгрузить сервер и поддерживать стабильную работу при высоких нагрузках.
Как выбрать подходящую структуру очереди для конкретной задачи в программировании?
Выбор структуры очереди зависит от характера операций и объема данных. Если требуется часто добавлять и удалять элементы в динамическом потоке, лучше использовать связанные списки, где вставка и удаление выполняются за константное время. Для очередей с фиксированным размером и редкими удалениями подойдет массив с кольцевым буфером, который экономит память и снижает количество операций сдвига элементов. Также важно учитывать необходимость сортировки по приоритету: для этого используют очереди с приоритетами на основе двоичных куч или сбалансированных деревьев, что обеспечивает быструю обработку критичных задач.